����Ŀ¼:
ǰ��:
����VOC���ݼ���yolox�ȿӼ�¼,������������,���ݼ�������,ģ��ѵ���ͼ�⡣
1.yolox��ѵ������
1.1 300epoch��ѵ������,����,ǰ5��epochʹ��warmupѧϰ�ʲ���;
�Ż���ʹ�ñ����SGD;
1.2 ��߶�ѵ��:448-832,������������320-608�ˡ���Ӧ������large input size���ǵ㡣
1.3 Backbone����v3��ʹ�õ�DarkNet-53��
1.4 Ԥ�ⲿ�ּ�����IoU-aware��֧,��һ��Ӧ���Ǻ�PP-YOLO�Ƕ����
1.5 ��ʧ����:obj��֧��cls��֧����ʹ��BCE,reg��֧��ʹ��IoU loss;
1.6 ʹ��EMAѵ������(����ܺ���,���Լӿ�ģ�͵������ٶ�);
1.7 ������ǿ��ʹ��RandomHorizontalFlip��ColorJitter�Լ���߶�ѵ��,��ʹ��RandomResizedCrop,������ΪRandomResizedCrop��Mosaic�е��غ��ˡ����ں�������Mosaic Augmentation,����������ʱ�Ȳ�Ҫ�ˡ�
2.yoloxԴ��
����: link.
3.��Ҫ�Ļ���
win10+python3.7+cuda11.1
����yolox���軷��
1.��װ������
pip install -r requirements.txt
# TODO: Update with exact module version
numpy
torch>=1.7
opencv_python
loguru
scikit-image
tqdm
torchvision
Pillow
thop
ninja
tabulate
tensorboard
# verified versions
onnx==1.8.1
onnxruntime==1.8.0
onnx-simplifier==0.3.5
2.��װyolox
python setup.py install
3.��װapex
apex���ص�ַ,
cd��apex-master,
python setup.py install
4.����Ԥѵ��ģ��
model,
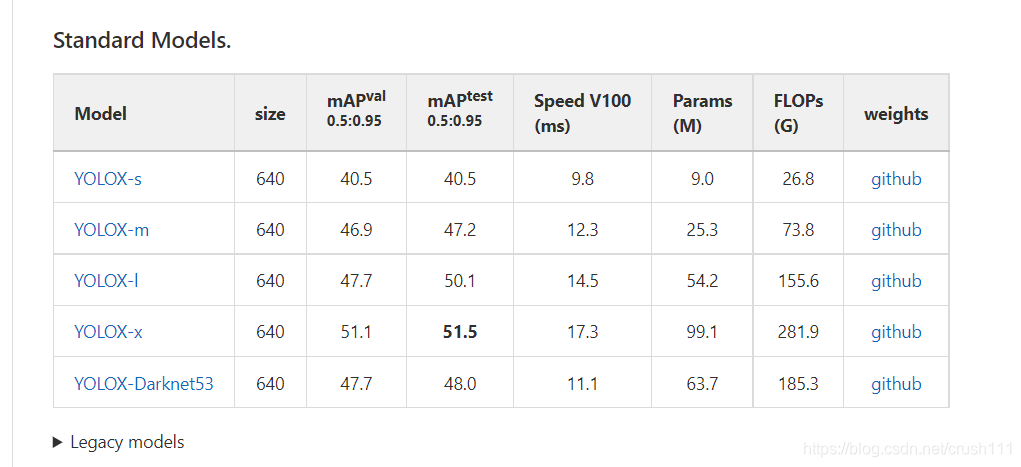
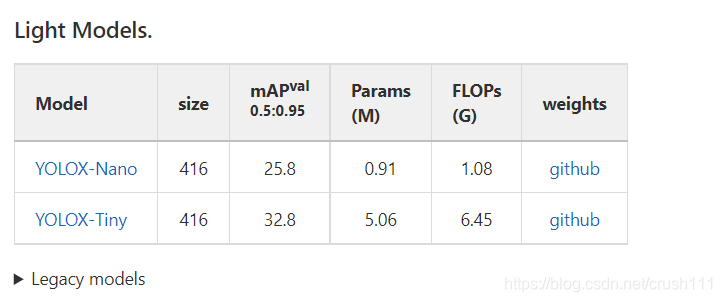
Ԥѵ��ģ�Ͱ�����(standard)������(light)����yolox�ļ����´���һ��weights���ڴ��ģ�͡�
4.���Լ������ݼ�
����VOC���ݼ�
voc���ݼ��ĸ�ʽ����:
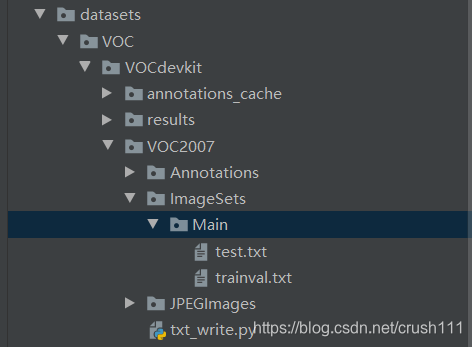
����,annotation���ڴ��xml��ʽ�ı�ǩ�ļ�,JPEGimage���ڴ��ԭʼͼƬ���������Լ����õ�labelme���ı�ǩ,���ɵ���json��ʽ�ı�ǩ�ļ�������������һ��json convert to xml�Ķ�����
import os
from typing import List, Any
import numpy as np
import codecs
import json
from glob import glob
import cv2
import shutil
from sklearn.model_selection import train_test_split
labelme_path = "before/json/" # json�ļ���·��
saved_path = "before/xml/" # xml����·��
if not os.path.exists(saved_path + "Annotations"):
os.makedirs(saved_path + "Annotations")
files = glob(labelme_path + "*.json")
files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files]
print(files)
for json_file_ in files:
json_filename = labelme_path + json_file_ + ".json"
json_file = json.load(open(json_filename, "r", encoding="utf-8"))
height, width, channels = 720, 1280, 3
with codecs.open(saved_path + "Annotations/" + json_file_ + ".xml", "w", "utf-8") as xml:
xml.write('<annotation>\n')
xml.write('\t<folder>' + 'WH_data' + '</folder>\n')
xml.write('\t<filename>' + json_file_ + ".png" + '</filename>\n') # ����ͼƬ��
xml.write('\t<source>\n')
xml.write('\t\t<database>WH Data</database>\n')
xml.write('\t\t<annotation>WH</annotation>\n')
xml.write('\t\t<image>flickr</image>\n')
xml.write('\t\t<flickrid>NULL</flickrid>\n')
xml.write('\t</source>\n')
xml.write('\t<owner>\n')
xml.write('\t\t<flickrid>NULL</flickrid>\n')
xml.write('\t\t<name>WH</name>\n')
xml.write('\t</owner>\n')
xml.write('\t<size>\n')
xml.write('\t\t<width>' + str(width) + '</width>\n')
xml.write('\t\t<height>' + str(height) + '</height>\n')
xml.write('\t\t<depth>' + str(channels) + '</depth>\n')
xml.write('\t</size>\n')
xml.write('\t\t<segmented>0</segmented>\n')
for multi in json_file["shapes"]:
points = np.array(multi["points"])
labelName = multi["label"]
xmin = min(points[:, 0])
xmax = max(points[:, 0])
ymin = min(points[:, 1])
ymax = max(points[:, 1])
label = multi["label"]
if xmax <= xmin:
pass
elif ymax <= ymin:
pass
else:
xml.write('\t<object>\n')
xml.write('\t\t<name>' + labelName + '</name>\n')
xml.write('\t\t<pose>Unspecified</pose>\n')
xml.write('\t\t<truncated>1</truncated>\n')
xml.write('\t\t<difficult>0</difficult>\n')
xml.write('\t\t<bndbox>\n')
xml.write('\t\t\t<xmin>' + str(int(xmin)) + '</xmin>\n')
xml.write('\t\t\t<ymin>' + str(int(ymin)) + '</ymin>\n')
xml.write('\t\t\t<xmax>' + str(int(xmax)) + '</xmax>\n')
xml.write('\t\t\t<ymax>' + str(int(ymax)) + '</ymax>\n')
xml.write('\t\t</bndbox>\n')
xml.write('\t</object>\n')
print(json_filename, xmin, ymin, xmax, ymax, label)
xml.write('</annotation>')
����������txt_write.py,�������ݼ�,��д��main�ļ�����,����trainval.txt��test.txt��
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'F:/YOLOX-main/YOLOX-main/datasets/VOC/VOCdevkit/VOC2007/Annotations'
txtsavepath = 'F:/YOLOX-main/YOLOX-main/datasets/VOC/VOCdevkit/VOC2007/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftest = open('F:/YOLOX-main/YOLOX-main/datasets/VOC/VOCdevkit/VOC2007/ImageSets/test.txt', 'w')
ftrain = open('F:/YOLOX-main/YOLOX-main/datasets/VOC/VOCdevkit/VOC2007/ImageSets/trainval.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftest.write(name)
else:
ftrain.write(name)
ftrain.close()
ftest.close()
���֮��,��VOC copy��datasets�ļ�����,�������VOC���ݼ���������
5.ѵ��
1.�� yolox/data/dataloading.py,line25

2.��exps/example/yolox_voc/yolox_voc_s.py,line31

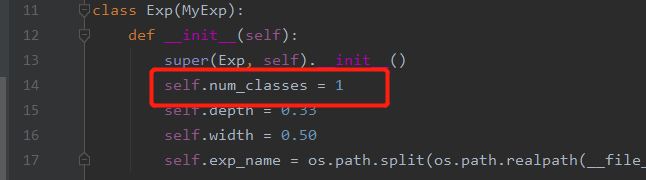
3.��exps/example/yolox_voc/yolox_voc_s.py,line14,
num_classesΪ�Լ����ݵ��ࡣ������������
4.��yolox/data/datasets/voc_classes.pyΪ�Լ������
5.��yolox/evaluators/voc_eval.py,����rootΪannotation�ľ���·����
root = r'F:/yolox/YOLOX-main/YOLOX-main/datasets/VOC/VOCdevkit/VOC2007/Annotations/'
def parse_rec(filename):
""" Parse a PASCAL VOC xml file """
tree = ET.parse(root + filename)
6.��ʼѵ��
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 1 -b 4 --fp16 -o -c yolox_s.pth.tar
�豸��������,һֱ��cuda out of memory �Ĵ�,���ǵ�С��batch_size,�����������Ԥѵ��ģ��,ȥ���˨Cfp16 -o��
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 1 -b 4 -c weights/yolox_nano.pth.tar
Ч����������,��������ֻ��ע��200��ͼƬ,������300��epoch������������2��Сʱ,����֮��,����yolox��Ŀ¼������yolox-output,ֵ��ע�����lastest��best.pth����Ȩ���ļ���
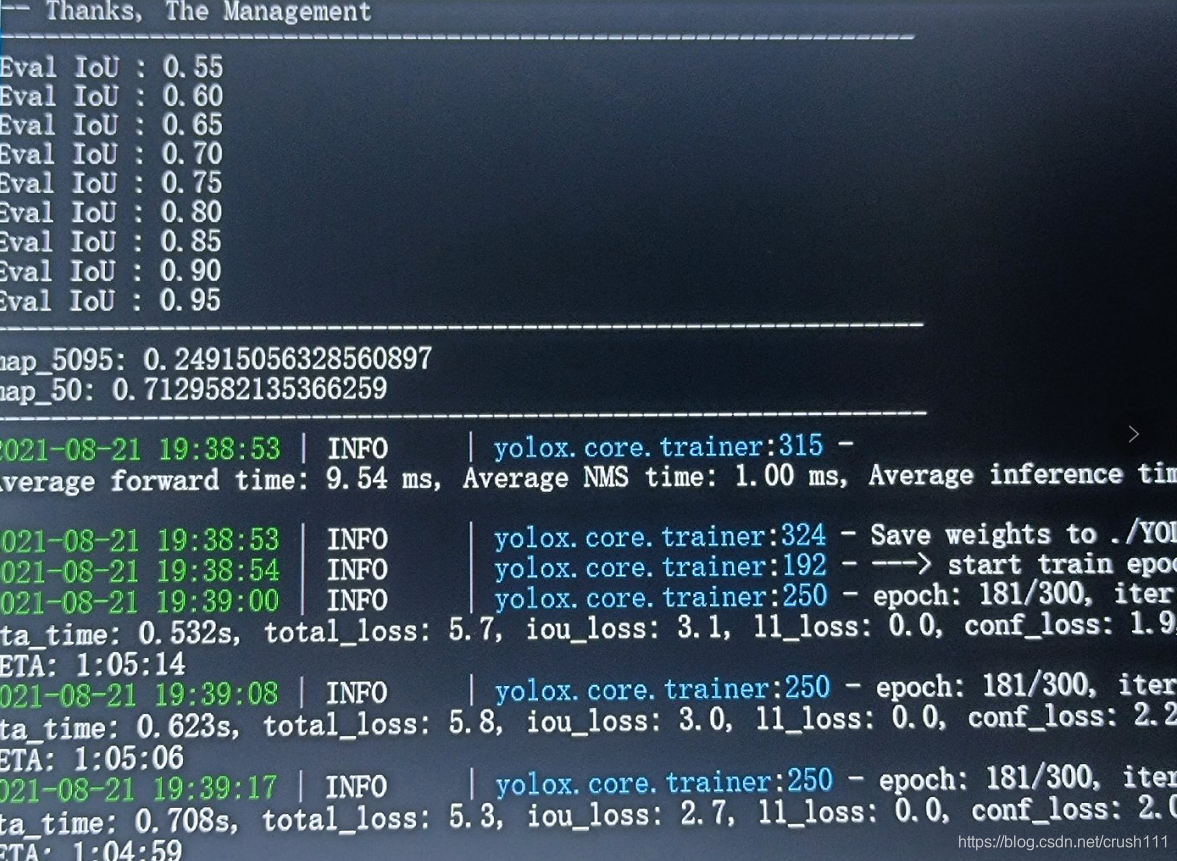
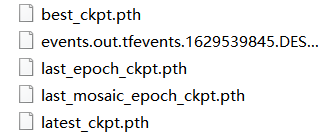
���Ҫ�ϵ������Ļ�,��Ҫ��train.py��resumeΪTRUE,Ȩ���ļ���Ϊlastest��best.pth��
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 1 -b 4 -c YOLOX_outputs/yolox_voc_s/latest_ckpt.pth.tar
6.����
����ʱ��Ҫ��tools�µ�demo.py��
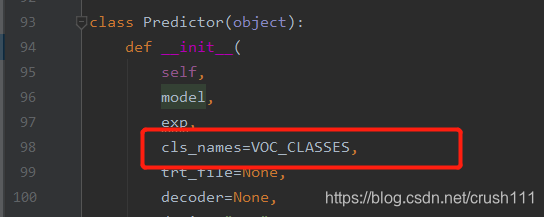
1.import��from yolox.data.datasets.voc_classes import VOC_CLASSES

2.
3.��cls_name
4.���Ե���ͼƬ:
python tools/demo.py video -f exps/example/yolox_voc/yolox_voc_s.py -c YOLOX_outputs/yolox_voc_s/best_ckpt.pth --33d37a437.jpg --conf 0.3 --nms 0.65 --tsize 640 --save_result --device gpu
�������:
python tools/demo.py image -f exps/example/yolox_voc/yolox_voc_s.py -c YOLOX_outputs/yolox_voc_s/best_ckpt.pth --path test/ --conf 0.3 --nms 0.65 --tsize 640 --save_result --device gpu
5.������������ڡ�Ŀ¼��
�ܽ�:
ֻѵ����200��ͼƬ,300��epoch,Ч��������غܴ�,
������ͨ��,
����!

