复习: 回顾学习完第一章,我们对泰坦尼克号数据有了基本的了解,也学到了一些基本的统计方法,第二章中我们学习了数据的清理和重构,使得数据更加的易于理解;今天我们要学习的是第二章第三节:数据可视化,主要给大家介绍一下Python数据可视化库Matplotlib,在本章学习中,你也许会觉得数据很有趣。在打比赛的过程中,数据可视化可以让我们更好的看到每一个关键步骤的结果如何,可以用来优化方案,是一个很有用的技巧。
2 第二章:数据可视化
开始之前,导入numpy、pandas以及matplotlib包和数据
# 加载所需的库
# 如果出现 ModuleNotFoundError: No module named 'xxxx'
# 你只需要在终端/cmd下 pip install xxxx 即可
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#加载result.csv这个数据
df=pd.read_csv('result.csv')
df.head()

2.7 如何让人一眼看懂你的数据?
2.7.1 任务一:了解matplotlib,自己创建一个数据项,对其进行基本可视化
Matplotlib是一个Python 2D绘图库,它以多种硬拷贝格式和跨平台的交互式环境生成出版物质量的图形。 Matplotlib可用于Python脚本,Python和IPython (opens new window)Shell、Jupyter (opens new window)笔记本,Web应用程序服务器和四个图形用户界面工具包。
screenshots screenshots screenshots screenshots
Matplotlib 尝试使容易的事情变得更容易,使困难的事情变得可能。 您只需几行代码就可以生成图表、直方图、功率谱、条形图、误差图、散点图等。 更多的示例,请参见基础绘图例子和示例陈列馆。
为了简单绘图,该 pyplot 模块提供了类似于MATLAB的界面,尤其是与IPython结合使用时。 对于高级用户,您可以通过面向对象的界面或MATLAB用户熟悉的一组功能来完全控制线型,字体属性,轴属性等
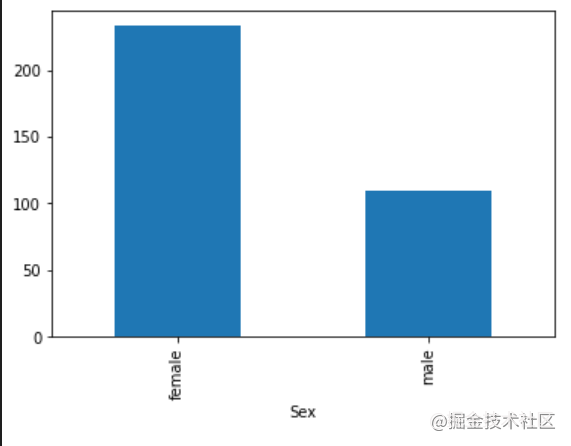
2.7.2 任务二:可视化展示泰坦尼克号数据集中男女中生存人数分布情况(用柱状图试试)。
#代码编写
a=df['Survived'].groupby(df['Sex']).sum()
a.plot.bar()
plt.show()
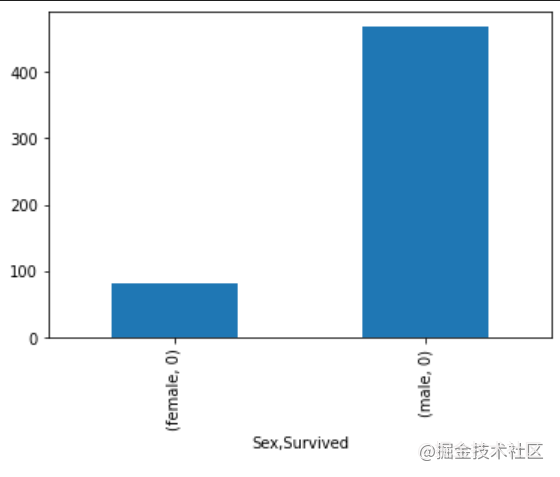
【思考】计算出泰坦尼克号数据集中男女中死亡人数,并可视化展示?如何和男女生存人数可视化柱状图结合到一起?看到你的数据可视化,说说你的第一感受(比如:你一眼看出男生存活人数更多,那么性别可能会影响存活率)。
#思考题回答
data=df[df["Survived"]==0]
data=data['Survived'].groupby(data['Sex'])
result=data.value_counts()
result.plot.bar()
plt.show()
2.7.3 任务三:可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图(用柱状图试试)。
#代码编写
# 提示:计算男女中死亡人数 1表示生存,0表示死亡
data=df.groupby(['Sex','Survived'])
data=data['Survived'].count()
data=data.unstack()
data.plot(kind='bar',stacked='True')
plt.title('survived_count')
plt.ylabel('count')
plt.show()

【提示】男女这两个数据轴,存活和死亡人数按比例用柱状图表示
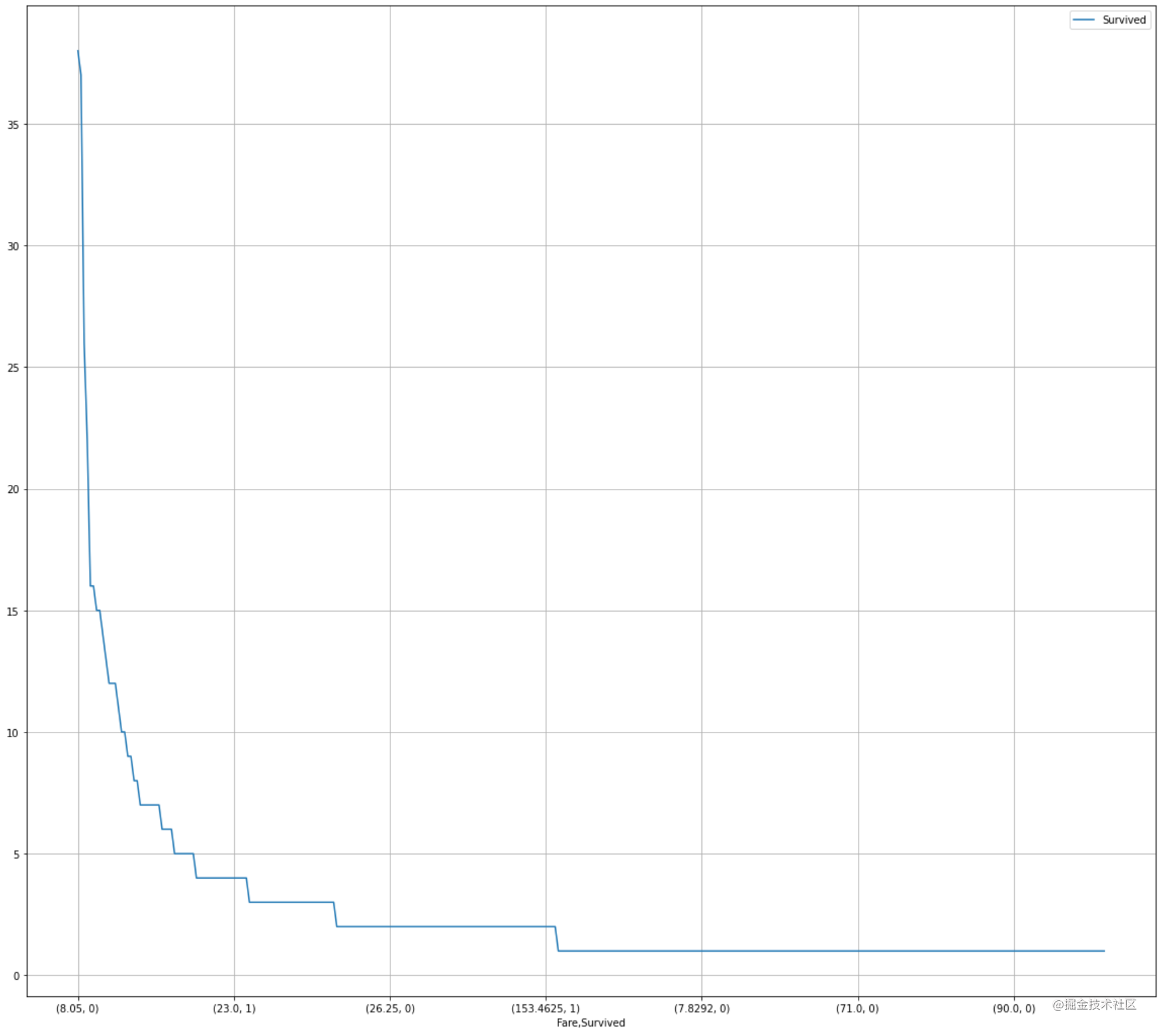
2.7.4 任务四:可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
【提示】对于这种统计性质的且用折线表示的数据,你可以考虑将数据排序或者不排序来分别表示。看看你能发现什么?
# 计算不同票价中生存与死亡人数 1表示生存,0表示死亡
fare_sur = df.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
fare_sur

#代码编写
# 排序后绘折线图
fig = plt.figure(figsize=(20, 18))
fare_sur.plot(grid=True)
plt.legend()
plt.show()
# 排序前绘折线图
fare_sur1 = df.groupby(['Fare'])['Survived'].value_counts()
fare_sur1

fig = plt.figure(figsize=(20, 18))
fare_sur1.plot(grid=True)
plt.legend()
plt.show()

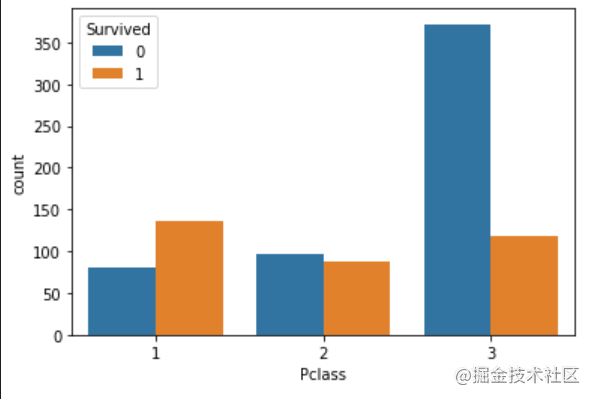
2.7.5 任务五:可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。(用柱状图试试)
#代码编写
# 1表示生存,0表示死亡
pclass_sur = df.groupby(['Pclass'])['Survived'].value_counts()
pclass_sur

seaborn是一个建立在matplot之上,可用于制作丰富和非常具有吸引力统计图形的Python库。Seaborn库旨在将可视化作为探索和理解数据的核心部分,有助于帮人们更近距离了解所研究的数据集。
- https://blog.csdn.net/u010636181/article/details/80671244
- https://blog.csdn.net/fenfenxhf/article/details/82859620
import seaborn as sns
sns.countplot(x="Pclass", hue="Survived", data=df)
具体参数:
sns.countplot(x=None, y=None, hue=None, data=None, order=None, hue_order=None, orient=None, color=None, palette=None, saturation=0.75, dodge=True, ax=None, **kwargs)
- x: x轴上的条形图,以x标签划分统计个数
- y: y轴上的条形图,以y标签划分统计个数
- hue: 在x或y标签划分的同时,再以hue标签划分统计个数
- data: DataFrame或array或array列表,用于绘图的数据集,x或y缺失时,data参数为数据集,同时x或y不可缺少,必须要有其中一个
# 如果特征比较多可以用sns.pairplot(data)来画特征和特征之间的关系
sns.pairplot(df)
plt.show() #直方图是单变量的分析,散点图是特征之间的关系

2.7.6 任务六:可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况。(不限表达方式)
#代码编写
facet = sns.FacetGrid(df, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, df['Age'].max()))
facet.add_legend()

2.7.7 任务七:可视化展示泰坦尼克号数据集中不同仓位等级的人年龄分布情况。(用折线图试试)
#代码编写
df.Age[df.Pclass == 1].plot(kind='kde')
df.Age[df.Pclass == 2].plot(kind='kde')
df.Age[df.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best")

【总结】 到这里,我们的可视化就告一段落啦,如果你对数据可视化极其感兴趣,你还可以了解一下其他可视化模块,如:pyecharts,bokeh等。
如果你在工作中使用数据可视化,你必须知道数据可视化最大的作用不是炫酷,而是最快最直观的理解数据要表达什么