KNN算法
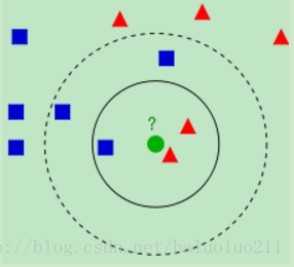
1 简单来说knn算法 就是 寻找未知分类的数据 离它最近的n个已知数据,然后看它属于哪一类
?2 算法原理通用步骤 : 计算距离 升序排列? 取前k个 加权平均
数据集下载链接:https://pan.baidu.com/s/1w8cyvknAazrAYnAXdvtozw
提取码:zxmt
参考教程https://www.bilibili.com/video/BV1Nt411i7oD?from=search&seid=4603953531395093043
import csv
import random
#数据读取
with open('Prostate_Cancer.csv','r') as file:
reader=csv.DictReader(file)
datas=[row for row in reader]
#数据读取,设前三分之一为测试集其余训练集
random.shuffle(datas)
n=len(datas)//3
test_set=datas[0:n]
train_set=datas[n:]
#knn
#距离,这里为欧几里距离
def distance(d1,d2):
res=0
for key in ("radius","texture","perimeter","area","smoothness","compactness","symmetry","fractal_dimension"):
res+=(float(d1[key])-float(d2[key]))**2
return pow(res,0.5)
k=5 #可以改变不同数值测验
def knn(data):
#1距离
res=[
{"result": train['diagnosis_result'],"distance":distance(data,train)}
for train in train_set
]
#2排序(升序)
res=sorted(res,key=lambda item:item['distance'])
#3取前k个
res2=res[0:k]
#4加权平均
result={'B': 0,'M': 0}
#总距离
sum=0
for r in res2:
sum+=r['distance']
for r in res2:
result [r['result']]+=1-r['distance']/sum
if result ['B']>result['M']:
return 'B'
else:
return 'M'
#测试阶段
correct=0
for test in test_set:
result=test['diagnosis_result']
result2=knn(test)
if result==result2:
correct+=1
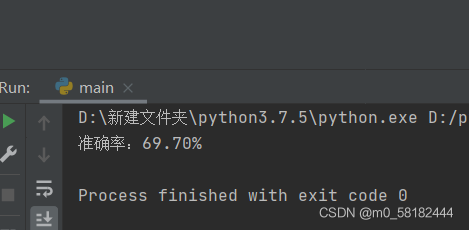
print("准确率:{:.2f}%".format(100*correct/len(test_set)))
?注意:1 python代码编写过程中缩进!!!
? ? ? ? ? ? 2 下载好的csv文件应与main.py放在同一目录下,csv文件不用放在一个文件夹里。