Python――词频统计
问题
统计每个单词出现的频率
解答
方法1(针对英文):
调用内置collections库
使用collections库的collections.Counter()方法进行词频统计
import collections
songs = 'You raise me up so I can stand on mountains You raise me up to walk on stormy seas I am strong when I am on your shoulders You raise me up To more than I can be'
word_list = songs.split() # 字符串删除空格,输出为列表形式
print(collections.Counter(word_list))
print(dict(collections.Counter(word_list))) # 转换为字典格式,统计完成
输出:
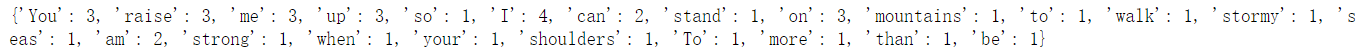
优点:
调用python内置库,很快速的一个方法进行词频统计
缺点:
大小写不分(以上实例中“To”与“to”被识别为两个单词)
手撕代码法
songs = 'You raise me up so I can stand on mountains You raise me up to walk on stormy seas I am strong when I am on your shoulders You raise me up To more than I can be'
word_list = songs.split() # 字符串删除空格,输出为列表形式
d = {}
for word in word_list:
word = word.lower() # 单词改为小写版
if word in d:
d[word] += 1
else:
d[word] = 1
print(d)
输出:
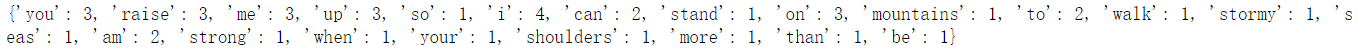
方法2(针对中文):
中文不同于英文,词是由一个一个汉字组成的,而英文的词与词之间本身就有空格,所以中文的分词需要单独的库才能够实现,常用的是jieba。我们以“华特气体”公司的主要业务进行分词,分词前如下图所示。通过open打开华特气体文本文件,使用读模式r,为避免编码错误,指定编码类型为utf-8。读取出来是一个大字符串,将这个大字符串存入txt。然后调用jieba进行分词。lcut的意思是切分词后再转换成列表("l"即表示list的首字母)。将切分后的词存入列表words。
拓展(词云图)
绘制词云图 https://blog.csdn.net/weixin_47282404/article/details/119916124