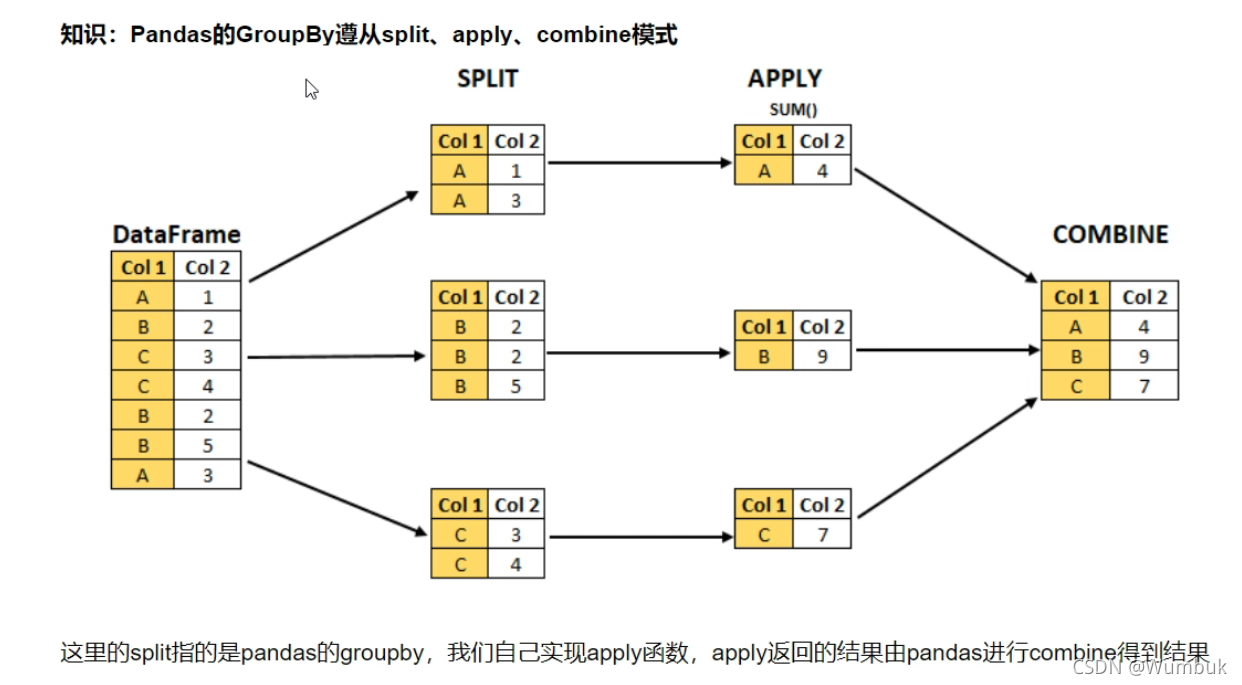
14.Pandas对每个分组应用apply函数
前言
笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章。本节主要记录Pandas中对每个分组应用apply函数.
GroupByapply(function)
- function的第一个参数是dataframe
- functio的返回结果,可是dataframe、series、单个值,甚至和输入dataframe完全没有关系
一、怎样对数值列按分组的归一化
将不同范围的数值列进行归一化,映射到[0,1]区间
- 更容易做数据横向对比,比如价格字段是几百到几千,增幅字段是0到100
- 机器学习模型学的更快,性能更好

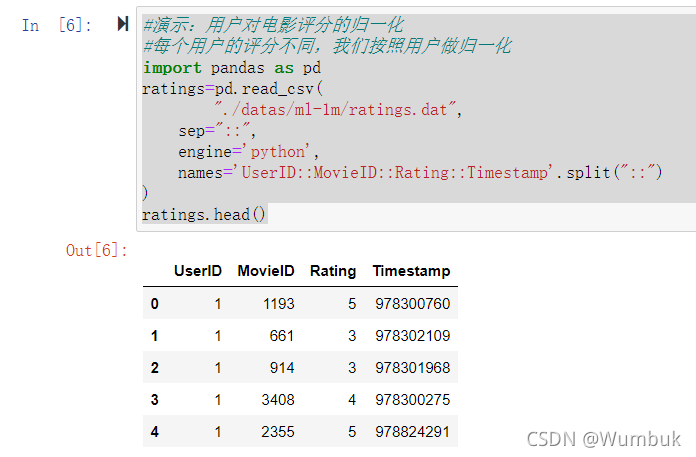
#演示:用户对电影评分的归一化
#每个用户的评分不同,我们按照用户做归一化
import pandas as pd
ratings=pd.read_csv(
"./datas/ml-1m/ratings.dat",
sep="::",
engine='python',
names='UserID::MovieID::Rating::Timestamp'.split("::")
)
ratings.head()
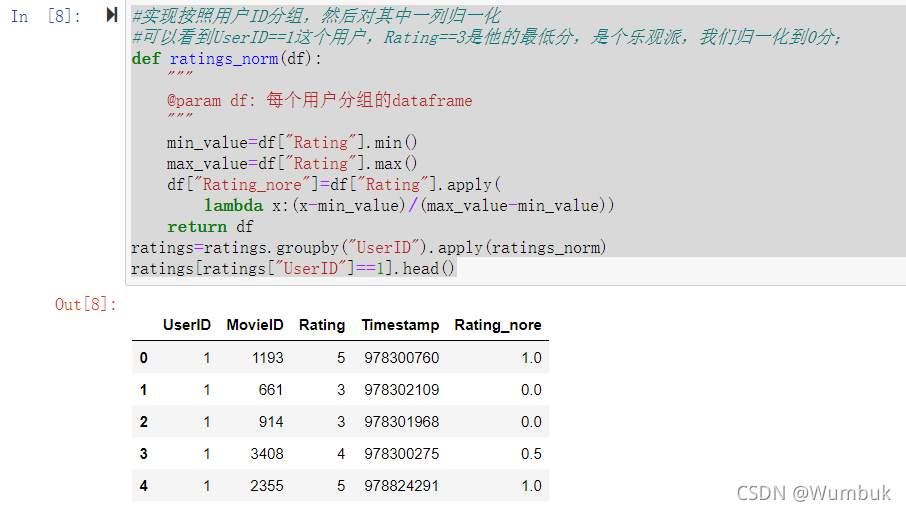
#实现按照用户ID分组,然后对其中一列归一化
#可以看到UserID==1这个用户,Rating==3是他的最低分,是个乐观派,我们归一化到0分;
def ratings_norm(df):
"""
@param df: 每个用户分组的dataframe
"""
min_value=df["Rating"].min()
max_value=df["Rating"].max()
df["Rating_nore"]=df["Rating"].apply(
lambda x:(x-min_value)/(max_value-min_value))
return df
ratings=ratings.groupby("UserID").apply(ratings_norm)
ratings[ratings["UserID"]==1].head()
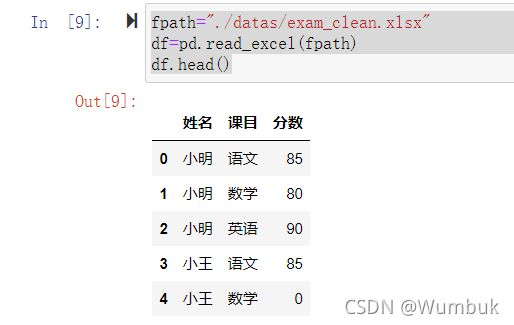
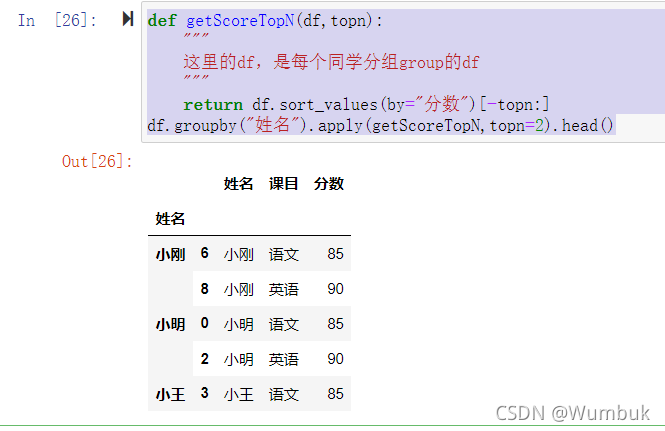
二、取每个分组的TOPN数据
获取每个同学最高的两个分数
fpath="./datas/exam_clean.xlsx"
df=pd.read_excel(fpath)
df.head()
def getScoreTopN(df,topn):
"""
这里的df,是每个同学分组group的df
"""
return df.sort_values(by="分数")[-topn:]
df.groupby("姓名").apply(getScoreTopN,topn=2).head()
总结
这就是pandas对每个分组应用apply函数的基本用法了,希望可以帮助到你。