深度学习――函数、类、爬虫
Python 函数
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
优点:函数能提高应用的模块性,和代码的重复利用率。
定义函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
函数的第一行语句可以选择性地使用文档字符串―用于存放函数说明。
函数内容以冒号起始,并且缩进。
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
语法
def functionname( parameters ):
"函数_文档字符串"
function_suite
return [expression]
实例:*
以下为一个简单的Python函数,它将一个字符串作为传入参数,再打印到标准显示设备上。
def printstr( str ):
"打印传入的字符串到标准显示设备上"
print('str')
return
可更改(mutable)与不可更改(immutable)对象
在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。
不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a。
可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
python 函数的参数传递:
不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
python 传不可变对象实例:
def ChangeInt( a ):
a = 10
b = 2
ChangeInt(b)
print b # 结果是 2
实例中有 int 对象 2,指向它的变量是 b,在传递给 ChangeInt 函数时,按传值的方式复制了变量 b,a 和 b 都指向了同一个 Int 对象,在 a=10 时,则新生成一个 int 值对象 10,并让 a 指向它。
传可变对象实例:
# 可写函数说明
def changeme( mylist ):
"修改传入的列表"
mylist.append([1,2,3,4])
print "函数内取值: ", mylist
return
# 调用changeme函数
mylist = [10,20,30]
changeme( mylist )
print "函数外取值: ", mylist
实例中传入函数的和在末尾添加新内容的对象用的是同一个引用,故输出结果如下:
函数内取值: [10, 20, 30, [1, 2, 3, 4]]
函数外取值: [10, 20, 30, [1, 2, 3, 4]]
参数
以下是调用函数时可使用的正式参数类型:
- 必备参数
- 关键字参数
- 默认参数
- 不定长参数
在定义函数时,位于函数名后面的变量通常称为形参。只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量。
调用函数时,参数表中提供的值称为实参。可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先给实参赋值。
必备参数:
必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
关键字参数:
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
实例:
#可写函数说明
def printme( str ):
"打印任何传入的字符串"
print str
return
#调用printme函数
printme( str = "My string")
以上实例输出结果:
My string
默认参数:
函数默认参数可以简化函数的调用,在设置默认参数时,需要注意以下几点:
1)一个函数的默认参数,仅仅在该函数定义的时候,被赋值一次。
2)默认参数的位置必须在函数形参列表的最右端。
不定长参数:
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。基本语法如下:
def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]
加了星号(* )的变量名会存放所有未命名的变量参数。不定长参数实例如下:
# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print "输出: "
print arg1
for var in vartuple:
print var
return
# 调用printinfo 函数
printinfo( 10 )
printinfo( 70, 60, 50 )
以上实例输出结果:
输出:
10
输出:
70
60
50
位置参数:
调用函数时,Python必须将函数调用中的每个实参都关联到函数定义中的一个形参。
最简单的关联方式是基于实参的顺序。在函数调用时,默认情况下,实参将按照位置顺序传递给形参。
这种关联方式中的参数叫做位置参数。
变量作用域
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序你可以访问哪个特定的变量名称。两种最基本的变量作用域如下:
- 全局变量
- 局部变量
实例
total = 0 # 这是一个全局变量
# 可写函数说明
def sum( arg1, arg2 ):
#返回2个参数的和."
total = arg1 + arg2 # total在这里是局部变量.
print "函数内是局部变量 : ", total
return total
#调用sum函数
sum( 10, 20 )
print "函数外是全局变量 : ", total
以上实例输出结果:
函数内是局部变量 : 30
函数外是全局变量 : 0
类
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。(类似于C中的结构体)
创建类
使用 class 语句来创建一个新类,class 之后为类的名称并以冒号结尾:
class ClassName:
'类的帮助信息' #类文档字符串
class_suite #类体
类的帮助信息可以通过ClassName.__doc__查看。
class_suite 由类成员,方法,数据属性组成。
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别――它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x10d066878>
__main__.Test
从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的:
实例
class Test:
def prt(runoob):
print(runoob)
print(runoob.__class__)
t = Test()
t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x10d066878>
__main__.Test
创建实例对象
实例化类其他编程语言中一般用关键字 new,但是在 Python 中并没有这个关键字,类的实例化类似函数调用方式。
以下使用类的名称 Employee 来实例化,并通过 init 方法接收参数。
"创建 Employee 类的第一个对象"
emp1 = Employee("Zara", 2000)
"创建 Employee 类的第二个对象"
emp2 = Employee("Manni", 5000)
访问属性
您可以使用点号 . 来访问对象的属性。使用如下类的名称访问类变量:
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCount
实例
class Employee:
'所有员工的基类'
empCount = 0
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
"创建 Employee 类的第一个对象"
emp1 = Employee("Zara", 2000)
"创建 Employee 类的第二个对象"
emp2 = Employee("Manni", 5000)
emp1.displayEmployee()
emp2.displayEmployee()
print "Total Employee %d" % Employee.empCount
执行以上代码输出结果如下:
Name : Zara ,Salary: 2000
Name : Manni ,Salary: 5000
Total Employee 2
你可以添加,删除,修改类的属性,如下所示:
emp1.age = 7 # 添加一个 'age' 属性
emp1.age = 8 # 修改 'age' 属性
del emp1.age # 删除 'age' 属性
你也可以使用以下函数的方式来访问属性:
- getattr(obj, name[, default]) : 访问对象的属性。
- hasattr(obj,name) : 检查是否存在一个属性。
- setattr(obj,name,value) : 设置一个属性。如果属性不存在,会创建一个新属性。
- delattr(obj, name) : 删除属性。
hasattr(emp1, 'age') # 如果存在 'age' 属性返回 True。
getattr(emp1, 'age') # 返回 'age' 属性的值
setattr(emp1, 'age', 8) # 添加属性 'age' 值为 8
delattr(emp1, 'age') # 删除属性 'age'
类的继承
(类似于JAVA)
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
继承语法
class 派生类名(基类名)
...
在python中继承中的一些特点:
1、如果在子类中需要父类的构造方法就需要显式的调用父类的构造方法,或者不重写父类的构造方法。详细说明可查看: python 子类继承父类构造函数说明。
2、在调用基类的方法时,需要加上基类的类名前缀,且需要带上 self 参数变量。区别在于类中调用普通函数时并不需要带上 self 参数
3、Python 总是首先查找对应类型的方法,如果它不能在派生类中找到对应的方法,它才开始到基类中逐个查找。(先在本类中查找调用的方法,找不到才去基类中找)。
如果在继承元组中列了一个以上的类,那么它就被称作"多重继承" 。
语法:
派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示:
class SubClassName (ParentClass1[, ParentClass2, ...]):
...
实例
class Parent: # 定义父类
parentAttr = 100
def __init__(self):
print "调用父类构造函数"
def parentMethod(self):
print '调用父类方法'
def setAttr(self, attr):
Parent.parentAttr = attr
def getAttr(self):
print "父类属性 :", Parent.parentAttr
class Child(Parent): # 定义子类
def __init__(self):
print "调用子类构造方法"
def childMethod(self):
print '调用子类方法'
c = Child() # 实例化子类
c.childMethod() # 调用子类的方法
c.parentMethod() # 调用父类方法
c.setAttr(200) # 再次调用父类的方法 - 设置属性值
c.getAttr() # 再次调用父类的方法 - 获取属性值
以上代码执行结果如下:
调用子类构造方法
调用子类方法
调用父类方法
父类属性 : 200
你可以继承多个类(不同于JAVA――只能继承一个类)
class A: # 定义类 A
.....
class B: # 定义类 B
.....
class C(A, B): # 继承类 A 和 B
.....
你可以使用issubclass()或者isinstance()方法来检测。
- issubclass() - 布尔函数判断一个类是另一个类的子类或者子孙类,语法:issubclass(sub,sup)
- isinstance(obj, Class) 布尔函数如果obj是Class类的实例对象或者是一个Class子类的实例对象则返回true。
方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法:
实例:
class Parent: # 定义父类
def myMethod(self):
print '调用父类方法'
class Child(Parent): # 定义子类
def myMethod(self):
print '调用子类方法'
c = Child() # 子类实例
c.myMethod() # 子类调用重写方法
执行以上代码输出结果如下:
调用子类方法
类属性与方法
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字可以为类定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数
类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,不能在类的外部调用。在类的内部调用 self.__private_methods
爬虫
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。
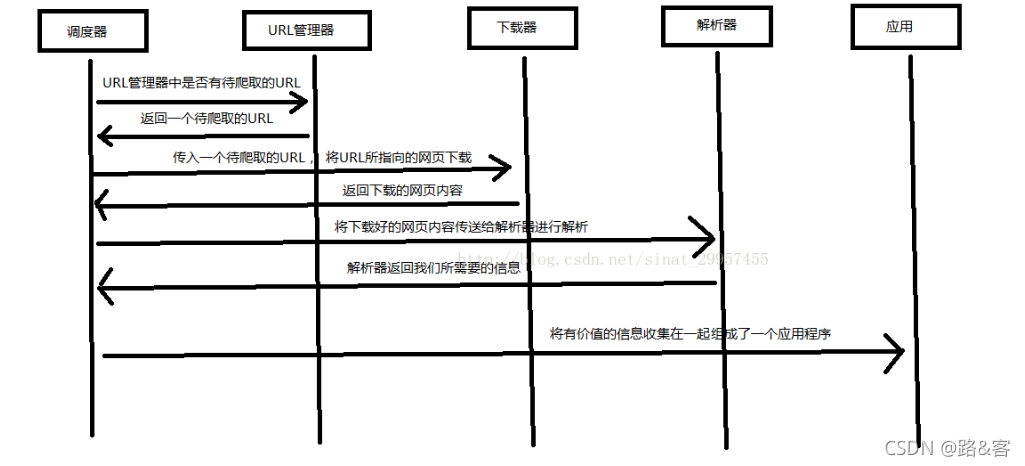
Python爬虫架构
Python 爬虫架构主要由五个部分组成,分别是调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)。
- 调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
- 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
- 网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
- 应用程序:就是从网页中提取的有用数据组成的一个应用。
工作如图: