简单参考 Python3实现网站模拟登录 写了个python模拟登录教务系统,具体用到了selenium浏览器自动测试框架,参考了 Flask 的文档 作接口。代码供参考。
import time
from selenium import webdriver # 网页自动化
from flask import Flask, request
app = Flask(__name__)
login_url = "" # 教务登录页面
base_url = "" # 教务首页
headers = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/91.0.4472.124 Safari/537.36",
"Origin": "https://jwxt.sztu.edu.cn"
} # 用户代理,模拟机器类型
cookies = {}
@app.route("/login", methods=['POST'])
def login():
print("request.json: ", request.json)
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(options=options)
try:
driver.get(login_url)
driver.find_element_by_id('j_username').clear() # 清空输入框
driver.find_element_by_id('j_username').send_keys(request.json['school_id']) # 自动敲入用户名
driver.find_element_by_id('j_password').clear() # 清空输入框
driver.find_element_by_id('j_password').send_keys(request.json['password']) # 自动敲入密码
driver.find_element_by_id('loginButton').click()
time.sleep(1)
driver.get(base_url)
for cookie in driver.get_cookies():
cookies[cookie['name']] = cookie['value']
print("cookies: ", cookies)
finally:
driver.quit()
if not cookies:
return {
"error": "登录失败,账号或密码错误",
}, 403
return {
"cookies": cookies
}
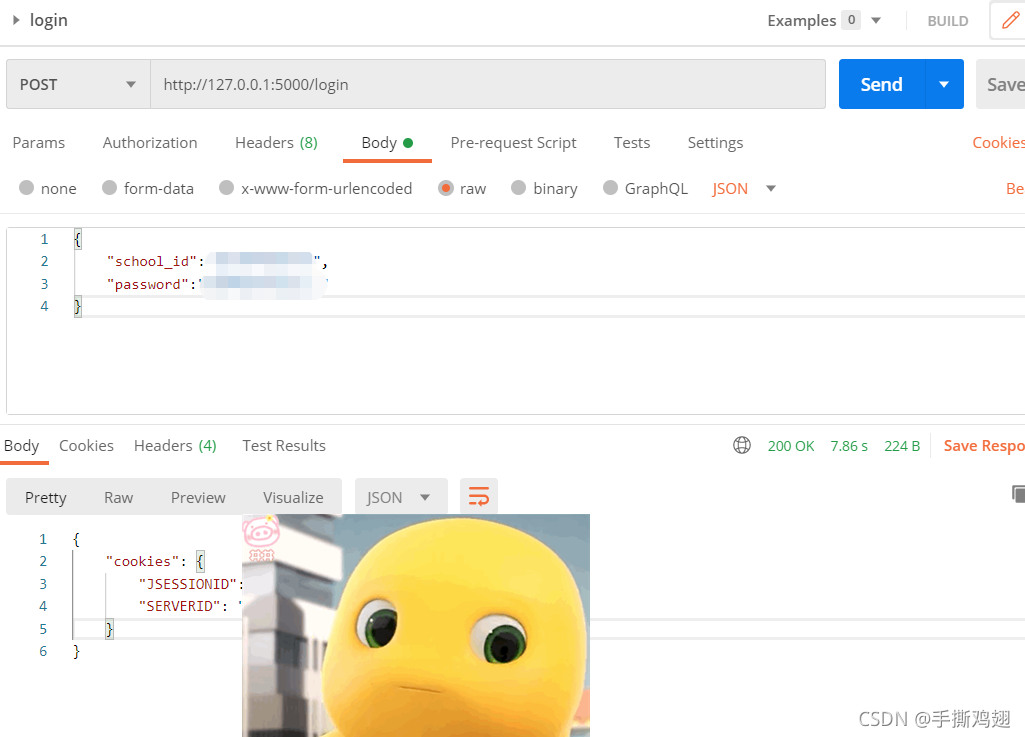
请求中带有模拟登录成功后获取的cookies即可爬取教务其它网页的数据,建议做成函数接口如下。获取后即可进行一些正则提取相应片段的数据,可参考我之前的 Python简单正则使用。
def get(url):
return requests.get(url, headers=headers, timeout=2, cookies=cookies, verify=False)