1读写excel数据
利用pandas可以很方便的读写excel数据
1.1 读:
data_in = pd.read_excel('M2FENZISHI.xlsx')
1.1 写:
首先要创建数据框
# example
df = pd.DataFrame({'A':[0,1,2]})
writer = pd.ExcelWriter('test.xlsx') #name of excel file
df.to_excel(writer, sheet_name='Sheet1') # write
writer.save() # save
2举例
2.1 要求
这个例子稍微有点复杂,只看读和写的部分就可以了。
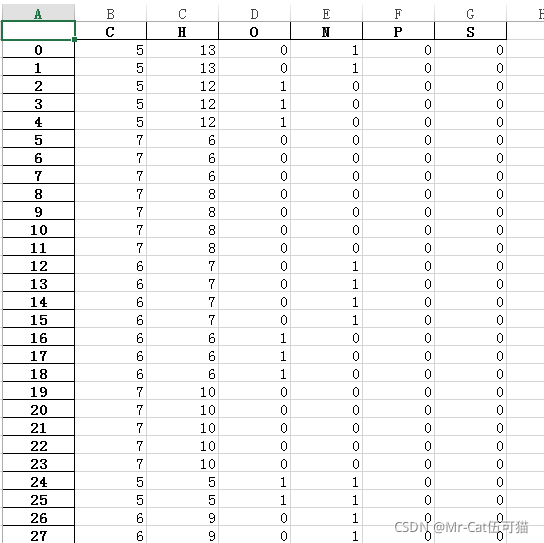
例子要实现的目标为:有一个excel文件,如下:
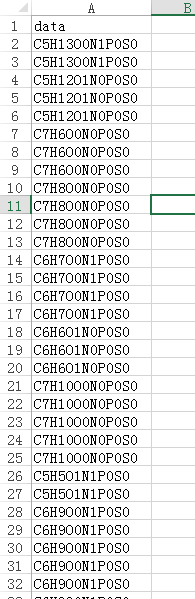
现在要将里面的化学符号中数字和字母分开,得到如下结果
2.2 实现
由于化学符号里面有数字和字母,要提取数字或者字母首先想到的是正则表达式re模块。
在读取时由于我们已经将第一列命名data,因此pandas可以直接只读这一列的提名。
读取数字可以使用re.compile实现,如:
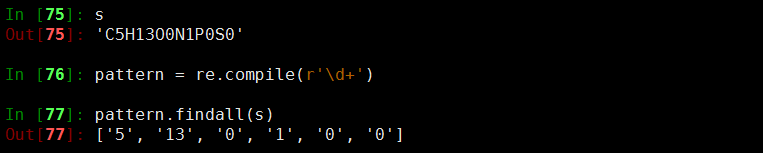
下面是完整实现的代码
import numpy as np
import re
import pandas as pd
data_in = pd.read_excel('M2FENZISHI.xlsx')['data'] #load data
print(data_in.shape)
length = len(data_in) # length
pattern = re.compile(r'\d+') # find number
num_out = []
for i in range(length):
temp = pattern.findall(data_in[i]) # find number
int_num = list(map(int,temp))
num_out.append(int_num)
num_out = np.array(num_out)
print(num_out.shape)
# writer data to excel
df = pd.DataFrame({'C': num_out[:, 0], 'H': num_out[:, 1], 'O': num_out[:, 2],
'N': num_out[:, 3], 'P': num_out[:, 4], 'S': num_out[:, 5]})
writer = pd.ExcelWriter('test.xlsx') # name of the file
df.to_excel(writer, sheet_name='Sheet1')
writer.save()
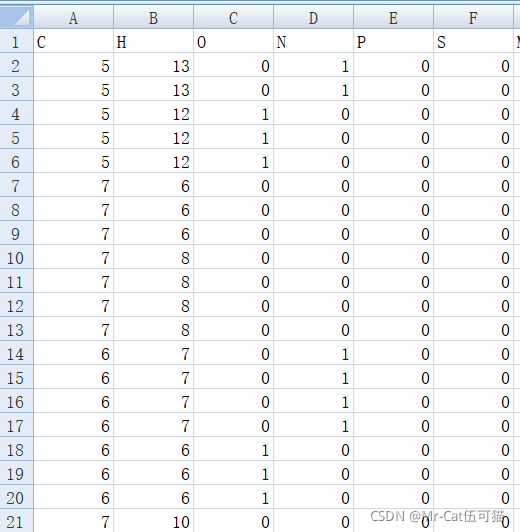
结果如下: