1.?去标点符号,分隔成单词
paragraph = "Bob hit a ball, the hit BALL: flew far after it was hit."
paragraph = paragraph.lower()
paragraph = paragraph.replace(':',' ')
paragraph = paragraph.replace(',',' ')
paragraph = paragraph.replace('.',' ')
paragraph = paragraph.split()
>>> ['bob','hit','a','ball','the','hit','ball','flew','far','after','it','was','hit']2.?几种字典根据value排序方法
(1)lambda
d = sorted(d.items(),key=lambda x:x[1],reverse=True) #按照value从大到小排
(2)operator.itemgetter()
import operator
x1 =
[
{'a':2,'b':1,'c':3},
{'a':1,'b':2,'c':3},
{'a':3,'b':2,'c':1}
]
x2 = sorted(x1,key=operator.itemgetter('a')
x3 = sorted(x1,key=operator.itemgetter('a','b')
y1 = {'a':1,'b':3,'c':2}
y2 = sorted(y1.items(),key=operator.itemgetter(1))
# 也可以用lambda来代替,但是itemgetter()效率高一些
# min / max 函数也适用
min(rows, key=operator.itemgetter('uid')) # 取uid列最小的一条
(3)zip
d = zip(d.values(),d.keys())
d = sorted(d)3. enumerate()函数
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
list(enumerate(seasons))
>>> [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
list(enumerate(seasons, start=1)) # 下标从 1 开始
>>> [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
seq = ['one', 'two', 'three']
for i, element in enumerate(seq):
print i, element
>>>
0 one
1 two
2 three
对一个字符串用enumerate,可以把里面的元素拆出来
enumerate('dcxs')
>>>
0 d
1 c
2 x
3 s
list('dcxs')也是同样的效果4. is和==的区别
is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值是否相等。 1、当列表,元组,字典中的值都引用 a,b 时,总是返回 True,不受 a,b 值大小的影响
a=1000
b=1000
list1=[a,3,5]
list2=[b,4,5]
print(list1[0] is list2[0])
>>> True
tuple1=(a,3,5)
tuple2=(b,4,5)
print(tuple1[0] is tuple2[0])
>>> True
dict1={6:a,2:3,3:5}
dict2={1:b,2:4,3:7}
print(dict1[6] is dict2[1])
>>> True当不引用a,b,直接用具体值来测试时,列表,字典,不受值大小影响,返回True,元组则受 256 值范围的影响,超出范围则地址改变,返回 False。
list1=[1000,3,5]
list2=[1000,4,5]
print(list1[0] is list2[0])
>>> True
tuple1=(1000,3,5)
tuple2=(1000,4,5)
print(tuple1[0] is tuple2[0])
>>> False
dict1={6:1000,2:3,3:5}
dict2={1:1000,2:4,3:7}
print(dict1[6] is dict2[1])
>>> True当直接用列表、元组、字典本身来测试时,刚好相反,元组返回 True,列表,字典返回 False。
list1=[1000,3,5]
list2=[1000,3,5]
print(list1 is list2)
>>> False
tuple1=(1000,3,5)
tuple2=(1000,3,5)
print(tuple1 is tuple2)
>>> True
dict1={1:1000,2:3,3:5}
dict2={1:1000,2:3,3:5}
print(dict1 is dict2)
>>> False因为 Python 出于对性能的考虑,内部作了优化,对于整数对象,把一些频繁使用的整数对象缓存起来,保存到一个叫 small_ints 的链表中。 在 Python 整个生命周期中,任何需要引用这些整数对象的地方,都不再重新创建新的整数对象,范围是 [-5,256]。
x is y
# 类似 id(x) == id(y). 如果引用的是同一个对象则返回 True,否则返回 False
x is not y
# 类似 id(a) != id(b). 如果引用的不是同一个对象则返回结果 True,否则返回 False5. datetime.timedelta类型转换为int类型
import datetime
prev_day = datetime.datetime(2017, 12, 31)
cur_day = datetime.datetime(2018, 1, 31)
diff = cur_day - prev_day
print(diff)
31 days, 0:00:00
#
diff是datetime.timedelta类型的数据
datetime.timedelta类型转换为int类型:diff.days
#
print(diff.days,type(diff.days))
31 <class 'int'>
---------------------------------------------------
a = datetime.date(2000,1,1)
b = datetime.datetime(2020,1,1)
>>>
a = 2000-01-01
b = 2020-01-01 00:00:006. 时间加减/互转
**加减天**
datetime.timedelta类(天= 0,秒= 0,微秒= 0,毫秒= 0,分钟= 0,小时= 0,星期= 0)
不支持年,月
from datetime import timedelta
a = datetime.datetime(2013,3,1)
b = a + timedelta(days=7)
**加减年/月**
timedelta 不支持年份,因为一年的持续时间取决于哪一年(例如,leap年为2月29日),月份也支持。
可以改用relativedelta支持,years并考虑添加基准日期的方法:
from dateutil.relativedelta import relativedelta
now = datetime.now()
now
>>> datetime.datetime(2019, 1, 27, 19, 4, 11, 628081)
now + relativedelta(years=1)
>>> datetime.datetime(2020, 1, 27, 19, 4, 11, 628081)
relativedelta(months=1)
**datetime和str互转**
datetime转字符串 today_str = today.strftime("%Y-%m-%d")
字符串转datetime today = datetime.datetime.strptime(today_str, "%Y-%m-%d")7. filter()
函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。 该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
list(filter(str.isalpha,s))8. __name__
**__name__属性**
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用**__name__**属性来使该程序块仅在该模块自身运行时执行。
#!/usr/bin/python3
# Filename: using_name.py
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')
运行输出如下:
$ python using_name.py
程序自身在运行
$ python
>>> import using_name
我来自另一模块
>>>
每个模块都有一个**__name__**属性,当其值是'**__main__**'时,表明该模块自身在运行,否则是被引入。
说明:**__name__** 与 **__main__** 底下是双下划线, **_ _** 是这样去掉中间的那个空格。
def main():
...
if __name__ == '__main__':
main()9. 多个list取交集
A = ['bella','label','roller']
#方法一
X = [set(i) for i in A]
X = set.intersection(*X)
#方法二
X = set.intersection(*map(set,A))
*号作用:返回的是多个数,用turple形式返回
set.intersection(set1, set2 ... etc)返回多个集合中的交集10. 统计出现频数
A = 'etct'
#方法一:用Counter.most_common()
return ''.join(x[0]*x[1] for x in Counter(A).most_common())
# Counter(A).most_common() 返回 [('e', 2), ('t', 1), ('r', 1)]
#方法二:不用Counter.most_common()
d = {i:A.count(i) for i in set(A)}
d = sorted(zip(d.values(),d.keys()),reverse=True)
# 按照字典value排序 sorted(zip(d.values(),d.keys())) ; 按照字典key排序 sorted(zip(d.keys(),d.values()))
# 多个list组成dict dict(zip(x,y))
# 多个list组合,并按第一个list排序 list(zip(x,y))
# 给定list = [('a',1),('b',2)], 按照第二列倒序排 sorted(list,key=lambda x:x[1],reverse=True)
x = ''.join(list(map(lambda x:x[1]*x[0],d)))11. 计算时间差
date1 = '2014/09/22',date2 = '2013/11/21'
#思路:
#假设date1大,date2小
#之差 = [365/366-date2的天数 + date1的天数] + 在(date1,date2)之间的闰年 + (date2-date1-1)*36512. defaultdict
使用普通的字典时,如果不在字典里就会报错,如:
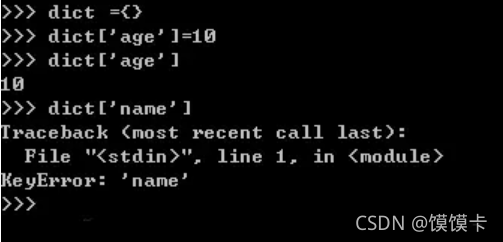
?这时defaultdict就能排上用场了,defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值。 这个factory_function可以是list、set、str等等,作用是当key不存在时,返回的是工厂函数的默认值,比如list对应[ ],str对应的是空字符串,set对应set( ),int对应0,如下:
from collections import defaultdict
dict1 = defaultdict(int)
dict2 = defaultdict(set)
dict3 = defaultdict(str)
dict4 = defaultdict(list)
dict1[2] ='two'
print(dict1[1])
print(dict2[1])
print(dict3[1])
print(dict4[1])
>>>
0
set()
[]?13. 原地修改list
nums = [1,2,3,4,5,6]
nums = nums[:-2] + nums[-2:] #这种不是原地修改,内存地址不同
nums[:] = nums[:-2] + nums[-2:] #原地修改14. 列表extend,append,+
a = [1,2,3]
b = [4,5,6]
a.extend(b) 等价于 a+= b
>>> [1,2,3,4,5,6]
a.append(b)
>>> [1,2,3,[4,5,6]]15. 如何判断一个字符串可以转换为数字
python自身提供了三种判断字符串是否可以转化成数字的方式:
isdigit()
True: Unicode数字,byte数字(单字节),全角数字(双字节)
False: 汉字数字,罗马数字,小数
Error: 无
isdecimal()
True: Unicode数字,,全角数字(双字节)
False: 罗马数字,汉字数字,小数
Error: byte数字(单字节)
?isnumeric()
True: Unicode 数字,全角数字(双字节),汉字数字
False: 小数,罗马数字
Error: byte数字(单字节)
?isalnum()
Python isalnum() 方法检测字符串是否由字母和数字组成。
?16. Python深浅拷贝
import copy
a = [1, 2, 3, 4, ['a', 'b']] #原始对象
b = a #赋值,传对象的引用
c = copy.copy(a) #对象拷贝,浅拷贝(没有拷贝子对象,所以原始的子对象改变时,浅拷贝的也改变)
d = copy.deepcopy(a) #对象拷贝,深拷贝(拷贝了子对象,所以原始任意改变,不影响深拷贝的内容)
a.append(5) #修改对象a
a[4].append('c') #修改对象a中的['a', 'b']数组对象
a = [1,2,3,4,['a','b','c'],5]
b = [1,2,3,4,['a','b','c'],5]
c = [1,2,3,4,['a','b','c']]
d = [1,2,3,4,['a','b']]
#默认拷贝方式是浅copy,效率高(时间少、内存少)17. 编码问题
unicode是全球统一的字符集
utf-8是编码规则(每次8个位传输数据)
ASCII码:针对英文
2.x中字符串有str和unicode两种类型,str有各种编码区别,unicode是没有编码的标准形式。unicode通过编码转化成str,str通过解码转化成unicode。
3.x中将字符串和字节序列做了区别,字符串str是字符串标准形式与2.x中unicode类似,bytes类似2.x中的str有各种编码区别。bytes通过解码转化成str,str通过编码转化成bytes。
Python 2:Python 2的源码.py文件默认的编码方式为ASCII
Python 3:Python 3的源码.py文件默认的编码方式为UTF-8
头部申明
# -*- coding: utf-8 -*-或者# coding: utf-8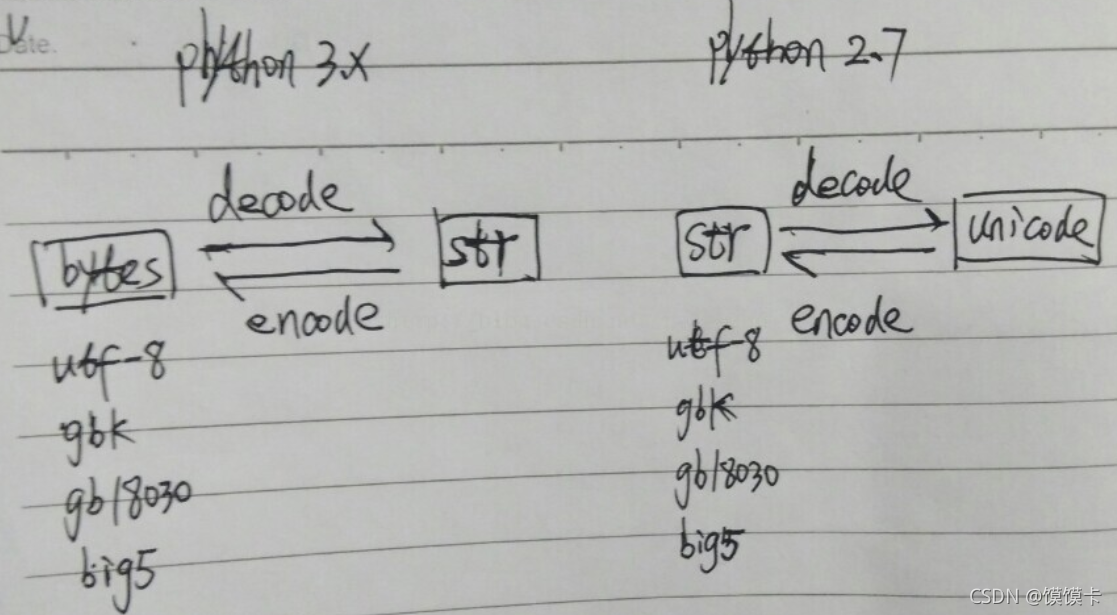
?18. 利用自带的缓存机制提高效率
缓存是一种将定量数据加以保存,以备迎合后续获取需求的处理方式,旨在加快数据获取的速度。 数据的生成过程可能需要经过计算,规整,远程获取等操作,如果是同一份数据需要多次使用,每次都重新生成会大大浪费时间。所以,如果将计算或者远程请求等操作获得的数据缓存下来,会加快后续的数据获取需求。 为了实现这个需求,Python 3.2 + 中给我们提供了一个机制,可以很方便的实现,而不需要你去写这样的逻辑代码。 这个机制实现于 functool 模块中的 lru_cache 装饰器。
@functools.lru_cache(maxsize=None, typed=False)参数解读:
-
maxsize:最多可以缓存多少个此函数的调用结果,如果为None,则无限制,设置为 2 的幂时,性能最佳
-
typed:若为 True,则不同参数类型的调用将分别缓存。
举个例子
from functools import lru_cache
@lru_cache(None)
def add(x, y):
print("calculating: %s + %s" % (x, y))
return x + y
print(add(1, 2))
print(add(1, 2))
print(add(2, 3))输出如下,可以看到第二次调用并没有真正的执行函数体,而是直接返回缓存里的结果
calculating: 1 + 2
3
3
calculating: 2 + 3
5下面这个是经典的斐波那契数列,当你指定的 n 较大时,会存在大量的重复计算
def fib(n):
if n 2:
return n
return fib(n - 2) + fib(n - 1)利用timeit,现在测试一下到底可以提高多少的效率。
不使用 lru_cache 的情况下,运行时间 31 秒
import timeit
def fib(n):
if n 2:
return n
return fib(n - 2) + fib(n - 1)
print(timeit.timeit(lambda :fib(40), number=1))
# output: 31.2725698948由于使用了 lru_cache 后,运行速度实在太快了,所以我将 n 值由 30 调到 500,可即使是这样,运行时间也才 0.0004 秒。提高速度非常显著。
import timeit
from functools import lru_cache
@lru_cache(None)
def fib(n):
if n 2:
return n
return fib(n - 2) + fib(n - 1)
print(timeit.timeit(lambda :fib(500), number=1))
# output: 0.000492105988087132619. 交换的原理
a,b = b,a+b
'''
先右侧:m=b,n=a+b
再左侧:a=m,b=n
'''20. list转链表
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
res = [3,1,5,4,2]
dummy = temp = ListNode(0)
for i in res:
temp.next = ListNode(i)
temp = temp.next
return dummy.next21. 装饰器
装饰器本质上是一个 Python 函数或类,它可以让其他函数或类在不需要做任何代码修改的前提下增加额外功能。【为已经存在的对象添加额外的功能】
对于函数: 如果不加小括号,那么它可以到处传递/赋值给其他变量,且不执行; 如果加了小括号,那么这个函数就会执行。
def a():
return 'yes'
x = a
x
>>> <function a at 0x000002AD34CEFF78>
x()
>>> yes
@a_new_decorator 等价于 any_func = a_new_decorator(any_func)
#但是装饰器重写了我们函数的名字和注释文档(docstring)
print(any_func.__name__)
>>> Output: process_func
#解决方法:用wraps
from functools import wraps
def a_new_decorator(a_func):
@wraps(a_func)
def process_func():
pass
@a_new_decorator
def any_func():
XXX
print(any_func.__name__)
>>> any_func
#装饰器顺序
@a
@b
@c
def f ():
pass
#它的执行顺序是从里到外,最先调用最里层的装饰器,最后调用最外层的装饰器,它等效于
f = a(b(c(f)))22. 兼容Python2
six包:兼容python2和python3
23. 正无穷&负无穷
float('-inf')
float('inf')24. deque
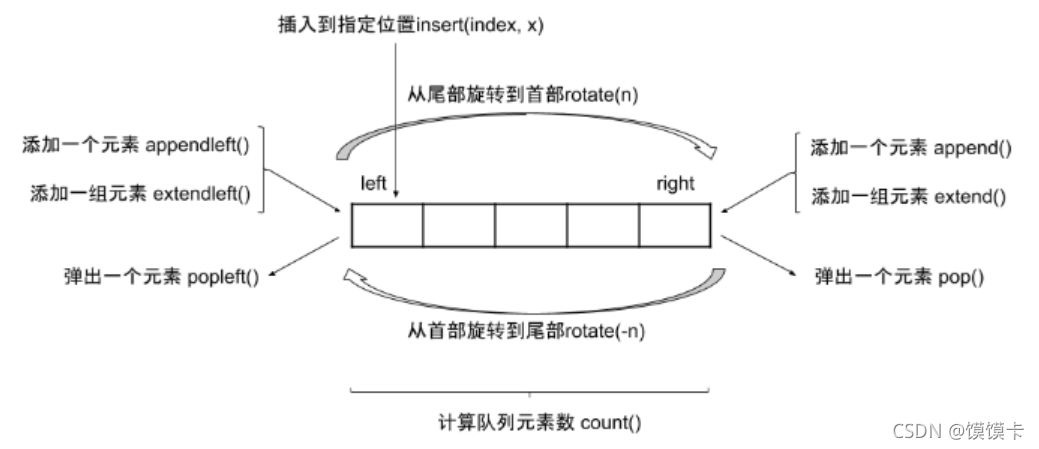
'''
相比于list实现的队列,deque实现拥有更低的时间和空间复杂度。
list实现在出队(pop)和插入(insert)时的时间复杂度大约为O(n),
deque在出队(pop)和入队(append)时的时间复杂度是O(1)。
deque里面是list的形式。
'''
from collections import deque
# deque支持in
q = collections.deque([1, 2, 3, 4])
print(1 in q) # True
# 支持顺、逆时针旋转
q.rotate(1) # [4,1,2,3]
q.rotate(-1)
# index
q.index(3)
q.index(2,0,3) # 在 index 0~3范围内查询数值2的index,找不到返回ValueError
?25. 连接SQL
# 方法一:pyodbc
import pyodbc
connection = pyodbc.connect('DRIVER={SQL Server}; SERVER=(local); DATABASE=AdventureWorks;USER=sa;PASSWORD=1')
query = 'SELECT FirstName, LastName FROM Person.Person where FirstName = "Timothy"'
df1 = pd.read_sql_query(query, connection)
# 方法二:sqlalchemy
import sqlalchemy
engine = sqlalchemy.create_engine('mssql+pyodbc://sa:123456@(local)/AdventureWorks?driver=SQL+Server')
df2 = pd.read_sql_query(query, engine)?26. 字符串转义/重复
str='Runoob'
print(str * 2) # 输出字符串两次,也可以写成 print (2 * str)
print('hello\nrunoob') # 使用反斜杠(\)+n转义特殊字符
print(r'\n') # 如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串
# print sep 参数
a = 10, b = 399, c = 98
print(a,b,c,sep='@') # 输出 10@399@9827. print不换行
# print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end=’’
print(x,end='')28. import小结
关于 import 的小结,以 time 模块为例:
(1) 将整个模块导入,例如:import time,在引用时格式为:time.sleep(1)
(2) 将整个模块中全部函数导入,例如:from time import *,在引用时格式为:sleep(1)
(3) 将模块中特定函数导入,例如:from time import sleep,在引用时格式为:sleep(1)
(4) 将模块换个别名,例如:import time as abc,在引用时格式为:abc.sleep(1)
from fibo import *
这将把所有的名字都导入进来,但是那些由单一下划线(_)开头的名字不在此例。
大多数情况, Python程序员不使用这种方法,因为引入的其它来源的命名,很可能覆盖了已有的定义。
from fibo import fib1,fib2
这种导入的方法不会把被导入的模块的名称放在当前的字符表中
所以在这个例子里面,fibo 这个名称是没有定义的:name 'fibo' is not defined
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回:
>>> dir(fibo)
['__name__', 'fib', 'fib2']
>>> a = 5
>>> dir()
['__name__','fib','fib2','a']29. dict类
def getPairs(dict):
for k,v in dict.items() :
print(k,v,sep=':')
getPairs({ x : x ** 3 for x in (1,2,3,4)})
>>> {1:1,2:8,3:27,4:64}30. float字符串转int
'''
当字符串内容为浮点型要转换为整型时,无法直接用 int() 转换:
a=‘2.1’ 这是一个字符串
'''
print(int(a))
'''
会报错 "invalid literal for int() "。
需要把字符串先转化成 float 型再转换成 int 型:
'''
print(int(float(a)))31. 标准数据类型
Python3 的六个标准数据类型中:
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组)
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)
与 C 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如word[0]='m’会导致错误
32. isinstance
a = 111
isinstance(a, int) # 返回True
'''
isinstance 和 type 的区别在于:
type() 不会认为子类是一种父类类型
isinstance() 会认为子类是一种父类类型33. True和False的数值
Python3 中,把 True 和 False 定义成关键字了,但它们的值还是 1 和 0,它们可以和数字相加。
34. 格式化字符串
# 老版本(使用%定义类型)
'我叫%s 今年%d岁' %('小命',10)
num = 18.7254
'the price is %.2f' %num # 输出18.73
num = 18
'the price is %d' %num # 必须指定%d,否则无法使用
# 过渡版本(使用.format)
'the price is {:.2f}'.format(num)
# 新版本(使用f) 【字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去】
name = 'Runoob'
f'Hello {name}' # 替换变量
f'{1+2}' # 使用表达式
f'{name}:{2+3}' # 输出 Runoob:535. join用法
# join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
x = ['a','c','3','11']
''.join(x) # 输出 'ac311'
'-'.join(x) # 输出 'a-c-3-11'36. 元祖tuple
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开
tup1 = (20,) # 一个元素,需要在元素后添加逗号,不然括号会被当成运算符
tup2 = 20,'b' # 不需要括号也能创建元祖
由于元祖是不可变数据类型,所以修改元素的操作:
# 方法1
先转成list,操作完再转成tuple
# 方法2
通过切片操作
tuple1[:-2] + (3,) + tuple2[3:5]
# 切片操作需注意,不能使用tuple1[2],因为切出来的不是元祖,可以用tuple[2:3]代替37. 集合操作
集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号 { } 或者 set() 函数创建集合,
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
集合中重复的元素会自动被去掉
集合是无序的,不支持索引
# 集合运算
set(a), set(b)
print(a - b) # a 和 b 的差集 【在a里面,不在b里面】
print(a | b) # a 和 b 的并集
print(a & b) # a 和 b 的交集
print(a ^ b) # a 和 b 中不同时存在的元素
set的自动排序对负数不适用
a = [1,-4,-2,2,4]
set(a) # 输出 {1,2,4,-4,-2}
list(set(a)).sort(key=lambda x:x>=0) # 正确做法
尽量不要使用set的自动排序,集合是无序的
# 添加元素
s.add()
s.update() # 添加:列表、元祖、字典等
s.update('abc') # 将'abc'拆分成单个字符后,一一添加到集合中
s.update({'abc'}) # 将'abc'作为一个整体添加到集合中
# 移除元素
s.remove() # 元素不存在,会报错
s.discard() # 元素不存在,不会报错【只有set有discard语法】38. 列表&字典
列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。
# 创建字典
# 1
dict([('Runoob', 1), ('Google', 2), ('Taobao', 3)])
# 2
{x: x**2 for x in (2, 4, 6)}
# 3
dict(Runoob=1, Google=2, Taobao=3)
# 4
a = {'123':a,'b':12,4:5}39. 函数接收可变长参数
# python中的函数还可以接收可变长参数,比如以 “*” 开头的的参数名,会将所有的参数收集到一个元组上。
def test(*args):
return args
type(test(1,2,3,4)) # 返回元组类型
test(1,2,3,4) # 返回 (1,2,3,4)40. 布尔值
其他类型值转换 bool 值时除了
‘’、""、’’’’’’、""""""、0、()、[]、{}、None、0.0、0L、0.0+0.0j、False
为 False 外,其他都为 True
bool(-2) # 返回 True
bool('') # 返回 False
'''
Python3 废除了 long 类型,将 0 和 1 独立出来组成判断对错的 Bool 型,即 0 和 1 可以用来判断 false 和 true。
但是根本上并没有修改原则。这里的 Bool 型依然是 int 型的一部分,所以依然能当做数字参与运算,
所以 Python3 里的 Bool 型是 int 型的一个特例而不是一个独立的类型。41. zip & zip*
x = ['A','B','C','D']
y = ['a','b','c','d']
p = {m:n for m,n in zip(x,y)} # 输出 p: {'A':'a','B':'b','C':'c','D':'d'}
# 与 zip 相反,zip(*) 可理解为解压,返回二维矩阵式
x = [[1,2],[3,4],[5,6]]
list(zip(*x)) # 输出 [[1,3,5],[2,4,6]]
x = [[1,2,3,4],[4,5,6],[7,8,9]]
则zip(*x)返回只有(1,4,7),(2,5,8),(3,6,9),没有[1,2,3,4]里面的442. 字符串操作
# strip() 去掉空格
'cx '.strip()
'cx '.rstrip()
' cx'.lstrip()
# find 查找字符/字符串
str1.find(str2) = 1
str1.find(str2,beg=0,end=len(str1))
# 找不到,返回 -1
# partition分割字符串
s1.partition('s2')
('head','s2','tail') # 如果s2在s1中
(s1,'','') # 如果s2不在s1中
给定2个字符串,求一个字符串在另一个字符串中出现的位置
当它是空字符串时,我们应当返回什么值呢?
应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
# replace替换字符
x.replace('old','new',1) # 1代表替换多少次;默认不写的话,将符合的所有内容都替换掉43. Counter计数器
Counter(计数器):用于追踪值的出现次数
Counter类继承dict类,所以它能使用dict类里面的方法
collections.Counter(...)
# update(增加元素)
obj = collections.Counter(['11','22'])
obj.update(['22','55']) # 返回 Counter({'22': 2, '11': 1, '55': 1})
# subtract(减去元素)
obj = collections.Counter(['11','22','33'])
obj.subtract(['22','55']) # 返回 Counter({'11': 1, '33': 1, '22': 0, '55': -1})
# 删掉了22以后,在dict里面仍然会记录'22':044. 检查两个字符串是否由相同字母不同顺序组成
# 方法一
collections.Counter(a) == collections.Counter(b)
# 方法二
sorted(a) == sorted(b)45. 链式函数调用
def pro(a,b):
return a*b
def add(a,b):
return a+b
x = True
(pro if x else add)(5,6) 直接靠函数名称作为if条件判断46. 字典操作
# get() 返回指定键的值,如果值不在字典中,返回指定的默认值
dict.get(key,default=None)
d = {'a':1,'b':2}
d.get('c','NA')
# dict[] 取不到的话,报错
d['c']
# update 合并/更新字典
m1 = {'a':1}
m2 = {'b':2}
m1.update(m2)
m1 # 输出 {'a':1,'b':2}
m1.update(m2) # 该动作输出None
字典中,不允许同一个键出现两次;
创建时如果同一个键被赋值两次,后一个值会被记住;
键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
# 利用fromkeys()创建字典
seq = ('name','age','sex')
new_dict = dict.fromkeys(seq,10) # 输出 {'name':10,'age':10,'sex':10}
# 或者用字典推导式
new_dict = {i:10 for i in seq}
# 字典删键值
del new_dict['name']
new_dict.pop('name')
# 交换key和value(保证key和value均为不可变类型)
reverse = {y:x for x,y in old_dict.items()}
# 取最大值
max(zip(d1.keys(),d1.values())) # 取出最大键与对应的值
max(zip(d1.values(),d1.keys())) # 取出最大值与对应的键
# 复杂方法,取最大值对应的键
list(d2.keys())[list(d2.values()).index(max(d2.values()))]47. map函数
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
def square(x) : # 计算平方数
return x ** 2
map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
[1, 4, 9, 16, 25]
map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25]
# 提供了两个列表,对相同位置的列表数据进行相加
map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
[3, 7, 11, 15, 19]48. 运算符优先级
运算符优先级:and 拥有更高优先级
优先级:not>and>or
if not x or y and z
(1) (3) (2) ----- 优先级1>2>3 49. and & or
and:若所有值均为真,则返回最后一个值,若存在假,返回第一个假值;
or:返回第一个为真的值
print(0 and 1) # =>0,0等同于False
print(False and 1) # =>False
print(-1 and 1) # =>1
print(1 or False) # =>1,非零等同于True
print(True or False) # =>True
print(-1 or 0) # =>-150. 进制转换
可以分别使用 bin,oct,hex 可输出数字的二进制,八进制,十六进制形式
bin(a),oct(a),hex(a)
二进制1101 -> 十进制13
int('0b'+'1101',2)
十进制13 -> 二进制1101
bin('13')[2:]51. pow()
pow(x,y) = x**y
import math
math.ceil(x) # 向上取整
math.floor(x) # 向下取整52. choice(seq) & random.randint & random.randrange
# 从序列的元素中随机挑选一个元素
random.choice(range(10)) # 从0到9中随机挑选一个整数
random.choice([3,22,198,400])
# random.randint(x,y) 随机生成一个整数int类型,可以指定这个整数的范围
# 其实randint最终调用的是randrange函数,即randint(a,b)调用的是randrange(a,b+1)
random.randint(1000,9999) #包含左、右边界
random.randrange(1,21) #不包含右边界53. 将str拆成list
# 方法1
res = [i for i in st]
# 方法2
res = list(st)54. 将数字list转成str
''.join([str(i) for i in x])55. 取str反向
# 方法1 [::-1]
st[::-1]
# 方法2 list.reverse()
temp = list(st)
temp = temp.reverse()
''.join(temp)
# 方法3 栈实现
temp = list(st)
res = ''
while temp:
res += temp.pop()
# 方法4 reduce
reduce(lambda x,y:y+x,st)
# 方法5 递归
def func(st):
if len(st) < 2:
return st
return func(st[1:]) + st[0]
# 方法6 for循环
res = ''
for i in range(len(st)):
res += s[len(st)-i-1]56. 列表操作
# 创建空元素空间
alist = [None]*3 # 输出 [None,None,None]
当为空列表[]时,取a[0]会出错,但是取a[:] 或 a[0:]可以取到[]
# 列表推导式
[表达式 for 变量 in 列表 if 条件]
[表达式1 if 条件 else 表达式2 for 变量 in 列表]
[表达式 for 变量1 in 列表1 if 条件1 if 条件2 for 变量2 in 列表2 if 条件3]
# list.insert(i,x) # 第一个参数是准备插入到其前面那个元素的索引
a.insert(0,x) # 插入到整个列表之前
a.insert(len(a),x) # 相当于a.append(x)
# 删除list中第一个符合=x的数
list.remove(x)
list不支持replace57. 运行时间
import time
start = time.time
__main__
end = time.time
print(end-start)58. 循环
循环中,continue语句被用来告诉Python跳过当前循环块中的剩余语句,然后继续进行下一轮循环
while 循环语句和 for 循环语句使用 else 的区别:
1.如果 else 语句和 while 循环语句一起使用,则当条件变为 False 时,执行 else 语句。
2.如果 else 语句和 for 循环语句一起使用,else 语句块只在 for 循环正常终止时执行。
pass的用法
if a>1:
? ? pass ?# 如果没有内容,可以先写pass,但是如果不写pass,就会语法错误
59. Python传不可变对象
def ChangeInt(a):
a = 10
b = 2
ChangeInt(b)
print(b) # 输出 260. 默认参数
def printinfo(age=36,name) # 默认参数不放在最后,会报错
def printinfo(name,age=36) # 正确写法61. 函数操作
# 函数文档
def add(a,b):
"这是 add 函数文档"
return a+b
print(add.__doc__)
# 指定函数入参出参类型
def func(param_a:int,param_b:float) -> dict: # 入参int、float,出参dict62. 通过推导式转置矩阵
matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
matrix2 = [[a[i] for a in matrix] for i in range(4)]63. ASCII & 英文转换
ASCII -> 英文
[chr(i) for i in range(97,123)] #小写a-z
[chr(i) for i in range(65,91)] #大写A-Z
英文 -> ASCII
ord('A') = 65
# 一次性输出所有大/小写英文
import string
string.ascii_uppercase
string.ascii_lowercase64. 打开文件
# 一般来说推荐以下方法,执行完自动close,避免忘记关闭文件导致资源的占用
# 写
with open('test.txt', 'w', encoding='utf-8') as f:
f.write('test')
# 读
with open('test.txt', 'r', encoding='utf-8') as f:
f.readlines()65. 正则表达式re
import re
re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest') # 查找
['foot', 'fell', 'fastest']
re.sub(r'(\b[a-z]+)\s\1', r'\1', 'cat in the the hat') # 替换
'cat in the hat'
---------------------------------------------------------------------
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
字符类
[.?!]匹配 标点符号.或?或!
分枝条件
a|b|c匹配 条件a或者b或者c
分组
(a|b){3}匹配 满足了条件a或者b的内容做为一个组,重复3次
\W 匹配任意不是字母,数字,下划线,汉字的字符
\S 匹配任意不是空白符的字符
\D 匹配任意非数字的字符
\B 匹配不是单词开头或结束的位置
[^x] 匹配除了x以外的任意字符
[^aeiou] 匹配除了aeiou这几个字母以外的任意字符
后向引用
用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本,即(\b\w+\b)\s\1匹配'go go'
捕获
(exp) 匹配exp,并捕获文本到自动命名的组里
(?<name>exp) 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp)
(?:exp) 匹配exp,不捕获匹配的文本,也不给此分组分配组号
零宽断言
(?=exp) 匹配exp前面的位置
(?<=exp) 匹配exp后面的位置
(?!exp) 匹配后面跟的不是exp的位置
(?<!exp) 匹配前面不是exp的位置
注释
(?#comment) 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读
(?=exp)叫零宽度正预测先行断言,exp是后缀
(?<=exp)叫零宽度正回顾后发断言,exp是前缀
小括号的另一种用途是通过语法(?#comment)来包含注释。
懒惰限定符
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
$0:引用整个匹配的结果
举例:帮字符串加左右引号
find:\d{5}\D
replace:“$0”
$n
举例:(\d{3})-(\d{4})-(\d{3}) 匹配$1,$2,$3
匹配IP号码
((25[0-5]|2[0-4]\d|[0-1]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[0-1]?\d\d?)
一个更复杂的例子:
(?<=<(\w+)>).(?=<\/\1>)匹配不包含属性的简单HTML标签内里的内容。
(?<=<(\w+)>)指定了这样的前缀:被尖括号括起来的单词(比如可能是<b>),然后是.(任意的字符串),最后是一个后缀(?=<\/\1>),注意后缀里的\/,它用到了前面提过的字符转义。
\1则是一个反向引用,引用的正是捕获的第一组,前面的(\w+)匹配的内容,这样如果前缀实际上是<b>的话,后缀就是</b>了。
整个表达式匹配的是<b>和</b>之间的内容(再次提醒,不包括前缀和后缀本身)。
如果想对多条字符串应用同一条正则表达式,应该使用re.compile创建regex对象,可以节省大量CPU时间
regex = re.compile('\s+')
regex.split(text)66. pdf抓取
import pdfplumber
with pdfplumber.open("E:/ccc.pdf") as pdf:
page_1 = pdf.pages[0]
text = page_1.extract_text()
print(text)67. pop用法
x = [1,2,3]
while x.pop() == 3:
x.pop()
print(x) # 输出 x = []
x.pop()=3,此时x=[1,2],再用x.pop(),x=[1]
再判断x.pop()=1 != 3,此时x=[],同时不符合wile条件,结束while,所以x=[]68. any()
如果any()中的内容全是false,返回False,只要有一个是true,就返回True
69. 查询出现频率最高的数
from collections import Counter
a = [1,2,3,1,2,3,2,2,4,5,6]
Counter(a).most_common(2) # 不指定参数,则全列出,效果等同于Counter(a)70. try
def func1():
try:
print('a')
except ValueError:
print('b')
finally: # 一定会执行
print('finish')71. 日期识别parse
from dateutil.parser import parse
parse('2011-01-03') # 输出 datetime(2011,1,3,0,0)
# 缺点:不完美,会把一些不是日期的字符串识别为日期
# pandas中可用to_datetime来替代