爬虫的初级知识
request的一些方法
import urllib.request as req
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求 res是HTTPResponse类型
res = req.urlopen(url)
# read方法 read(n)代表返回n个字节
# 返回的是字节形式的二进制数据 按字节读,效率较低
content = res.read()
# 转码
# content = res.read().decode('utf-8')
# 读取一行
content = res.readline()
# 读取所有行 返回列表形式
content = res.readlines()
# 返回状态码
StatusCode = res.getcode()
# 返回url地址
src = res.geturl()
# 获取一些状态信息
status = res.getheaders()
下载文件
import urllib.request as req
# 下载网页
html_url = 'http://www.baidu.com'
req.urlretrieve(html_url,'下载.html')
# 下载图片,去复制图片地址
img_url = 'https://img2.baidu.com/it/u=1408169497,1468953967&fm=11&fmt=auto&gp=0.jpg'
req.urlretrieve(url=img_url,filename='老周.jpg')
# 下载视频
voide_url = 'https://vd2.bdstatic.com/mda-kjiipnx75rm4qpqm/sc/mda-kjiipnx75rm4qpqm.mp4?v_from_s=hkapp-haokan-hna&auth_key=1632218327-0-0-f91edfd8e96b63bbf3d0f33f0ad7802f&bcevod_channel=searchbox_feed&pd=1&pt=3&abtest=3000187_2'
req.urlretrieve(voide_url,'夜曲.mp4')
简单的UA反爬
import urllib.request as req
url = 'https://www.baidu.com'
'''
url的组成
http/https www.baidu.com 80
协议 主机 端口号 路径 参数 锚点
端口号:(http 80,https 443,mysql 3306,oracle 1521,redis 6379,mongodb 27017)
'''
header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
# 请求对象的定制
# 因为参数顺序的问题(中间还有data),所以需要关键字传参
request = req.Request(url=url,headers=header)
res = req.urlopen(request)
content = res.read().decode(' utf-8')
print(content)
'''
url = 'https://www.baidu.com'
res = req.urlopen(url)
content = res.read().decode(' utf-8')
print(content)
可以对比看看,这个的内容少了很多
'''
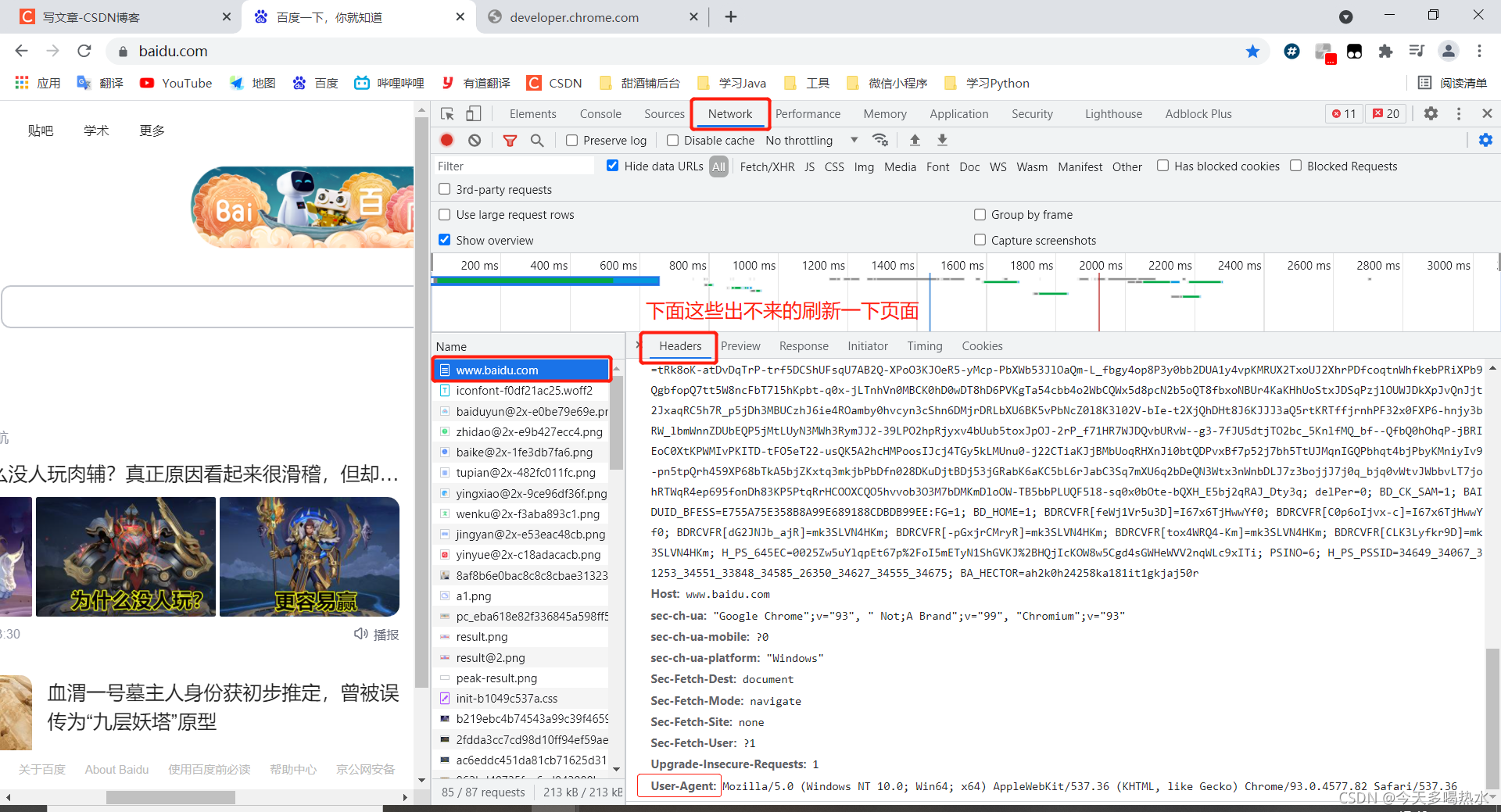
找自己的UA。
get方法
汉字变成Unicode(quote方法)
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
name = urllib.parse.quote('林俊杰') # 将汉字变成Unicode编码
url = url+name
# 请求对象的定制
# 因为参数顺序的问题(中间还有data),所以需要关键字传参
header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
request = urllib.request.Request(url=url,headers=header)
res = urllib.request.urlopen(request)
content = res.read().decode(' utf-8')
print(content)
urlencode:多个参数的转码
import urllib.request
import urllib.parse
base_url = 'https://www.baidu.com/s?'
suffix_url = {'wd':'周杰伦','sex':'男','location':'中国台湾省'}
suffix_url = urllib.parse.urlencode(suffix_url)
# 请求资源路径
url = base_url+suffix_url
header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=header)
# 模拟浏览器向服务器发送请求
res = urllib.request.urlopen(request)
content = res.read().decode(' utf-8')
print(content)
post方法
简单的post请求
import urllib.request
import urllib.parse
import json
url = 'https://fanyi.baidu.com/sug?'
data = {'kw':'spider'}
data = urllib.parse.urlencode(data).encode('utf-8')
# 如果没有.encode() 那么type(data)=<class 'str'>
header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
# post的请求的参数,不会拼接在url的后面,而是需要放在请求对象定制的参数中
request = urllib.request.Request(url=url,data=data,headers=header)
# 模拟浏览器向服务器发送请求
res = urllib.request.urlopen(request)
content = res.read().decode(' utf-8') # 现在str类型,而且内容还是utf-8的二进制码
# 字符串转对象,并将那些十六进制码转为对应的汉字
obj = json.loads(content)
print(obj)
'''
post请求方式的参数必须编码,也就是编码之后还需调用encode方法
参数是放在请求对象定制的方法中(也就是14行的三个参数)
'''
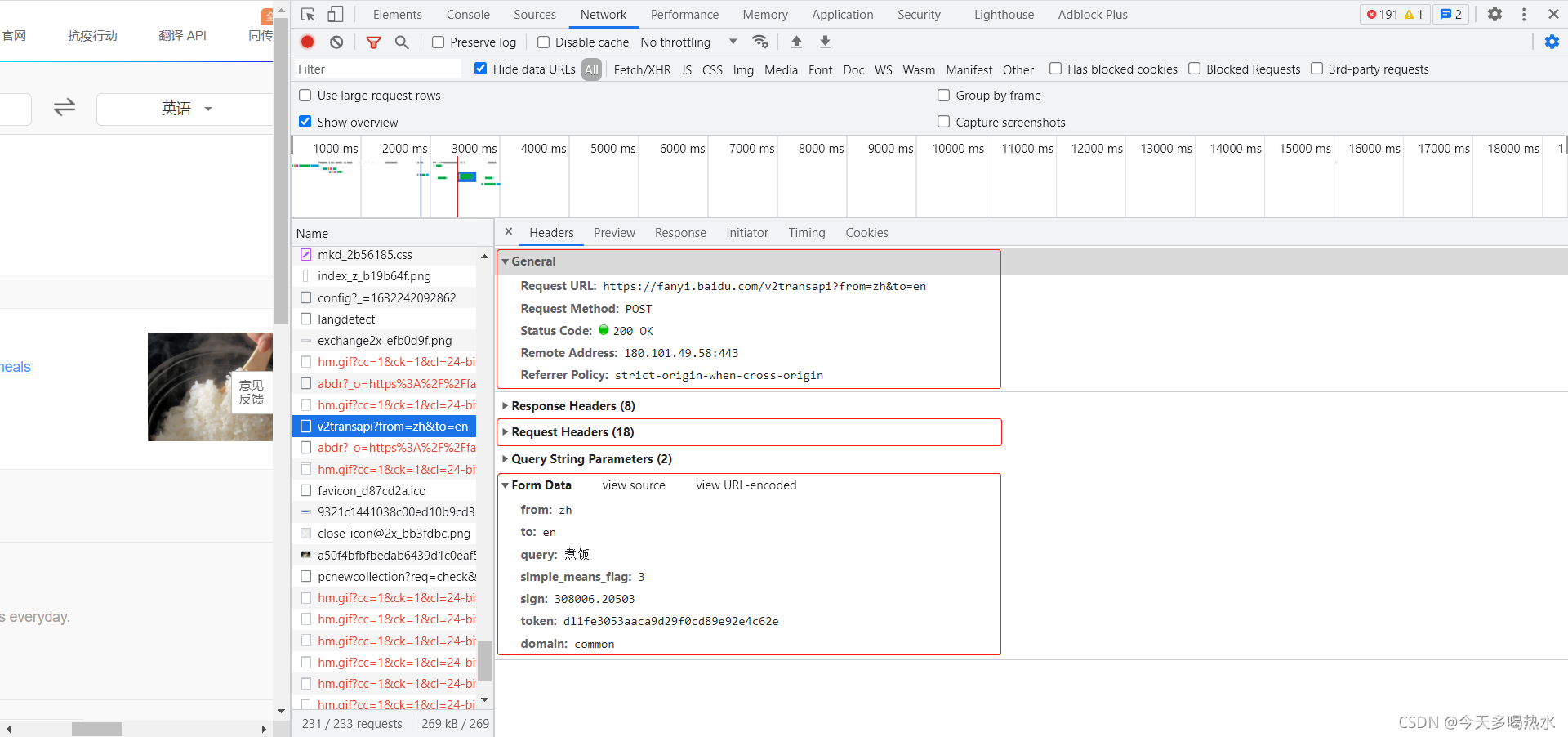
获取百度翻译的详细翻译
import urllib.request
import urllib.parse
import json
url = 'https://fanyi.baidu.com/v2transapi?from=zh&to=en'
data = {
'from':'zh',
'to':'en',
'query':'煮饭',
'simple_means_flag':'3',
'sign':'308006.20503',
'token':'d11fe3053aaca9d29f0cd89e92e4c62e',
'domain':'common'
}
data = urllib.parse.urlencode(data).encode('utf-8')
# 之前的请求头已经不适用了
# 这里我复制了 Request Headers 的所有内容 但最重要的是 Cookie
header={
# 'Accept':' */*',
# 'Accept-Encoding':' gzip, deflate, br',
# 'Accept-Language':' zh-CN,zh;q=0.9',
# 'Connection':' keep-alive',
# 'Content-Length':' 129',
# 'Content-Type':' application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'BIDUPSID=0C88EAAF464EF52F513EE44531F97EB3; PSTM=1625833975; __yjs_duid=1_2dfeeec2d06aef0f826d7ce3131c558a1625834045311; BAIDUID=1E21B1C3656E406711C4EE1FF855B3BF:FG=1; FANYI_WORD_SWITCH=1; REALTIME_TRANS_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDUSS=2xCN01sVDNidDVCTTNYY29qb1FFVk9ITGFsUTRJS2hOSXVyfmNoQkl5TGM5UjFoSVFBQUFBJCQAAAAAAAAAAAEAAACK-ILLtuC6yMjIy64xMjQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANxo9mDcaPZgV; BDUSS_BFESS=2xCN01sVDNidDVCTTNYY29qb1FFVk9ITGFsUTRJS2hOSXVyfmNoQkl5TGM5UjFoSVFBQUFBJCQAAAAAAAAAAAEAAACK-ILLtuC6yMjIy64xMjQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANxo9mDcaPZgV; H_WISE_SIDS=107313_110085_127969_128698_164869_168389_175668_175759_176399_176556_176677_177406_177760_178328_178530_178636_179201_179346_179402_179446_180276_180327_180407_180433_180436_180512_180642_180655_180705_180756_180870_180931_181218_181260_181327_181399_181402_181428_181432_181485_181588_181611_181628_181649_181660_181808_182024_182076_182164_182194_182321_182382_182387_182412_182552_182597_182664_182921; delPer=0; BAIDUID_BFESS=E755A75E358B8A99E689188CDBDB99EE:FG=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; BDRCVFR[C0p6oIjvx-c]=I67x6TjHwwYf0; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm; BDRCVFR[CLK3Lyfkr9D]=mk3SLVN4HKm; PSINO=7; H_PS_PSSID=34649_34067_31253_34551_33848_34585_26350_34627_34555_34675; BA_HECTOR=2l01ah8504ak0k84ls1gkk0t70r; BCLID=10775135699202917406; BDSFRCVID=6ytOJexroG0YyxOHsCmwMPJpdLweG7bTDYLtOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKKXgOTHw0F_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tRk8oK-atDvDqTrP-trf5DCShUFsBlQrB2Q-XPoO3KJOeR5-yMcp-pcXWb53JlOaQm-L_fbgy4op8P3y0bb2DUA1y4vpKMRUX2TxoUJ2XhrPDfcoqtnWhfkebPRiXPb9QgbfopQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0hD0wDjDMj6PVKgTa54cbb4o2WbCQMqbN8pcN2b5oQT8fjtOnBPvkaanuKboJ2R5vOIJTXpOUWfA3XpJvQnJjt2JxaqRC5h6Wfq5jDh3MKUDAjRnre4ROMRcy0hvcyn3cShn6DMjrDRLbXU6BK5vPbNcZ0l8K3l02V-bIe-t2XjQhDHt8J5kOJb3aQ5rtKRTffjrnhPF33PFPXP6-hnjy3bRW_JrlWInajn7EQP5jMtLUyN3MWh3RymJ42-39LPO2hpRjyxv4bUun0PoxJpOJ-KKtKbOaHR7WMpOvbURvW--g3-7fJU5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIEoC0XtCLMMCvPKITD-tFO5eT22-usQmOJ2hcHMPoosIJcjfOxy5kL5xnu0-j22COxbxK5JxbUoqRmXnJi0btQDPvxBf7p52jOLl5TtUJMqpoajlndqt4b2HjyKMniyIv9-pn5tpQrh459XP68bTkA5bjZKxtq3mkjbPbDfn028DKuDjRDKICV-frb-C62aKDs_tT2BhcqJ-ovQT3Z2Jkgyhbm2RbuLgQj0pR55l0bHxbeWfvMXn-R0hbjJM7xWeJpaJ5nJq5nhMJmKTLVbML0qto7-P3y523ihn3vQpnbhhQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0-nDSHH-qqTFe3f; BCLID_BFESS=10775135699202917406; BDSFRCVID_BFESS=6ytOJexroG0YyxOHsCmwMPJpdLweG7bTDYLtOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKKXgOTHw0F_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tRk8oK-atDvDqTrP-trf5DCShUFsBlQrB2Q-XPoO3KJOeR5-yMcp-pcXWb53JlOaQm-L_fbgy4op8P3y0bb2DUA1y4vpKMRUX2TxoUJ2XhrPDfcoqtnWhfkebPRiXPb9QgbfopQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0hD0wDjDMj6PVKgTa54cbb4o2WbCQMqbN8pcN2b5oQT8fjtOnBPvkaanuKboJ2R5vOIJTXpOUWfA3XpJvQnJjt2JxaqRC5h6Wfq5jDh3MKUDAjRnre4ROMRcy0hvcyn3cShn6DMjrDRLbXU6BK5vPbNcZ0l8K3l02V-bIe-t2XjQhDHt8J5kOJb3aQ5rtKRTffjrnhPF33PFPXP6-hnjy3bRW_JrlWInajn7EQP5jMtLUyN3MWh3RymJ42-39LPO2hpRjyxv4bUun0PoxJpOJ-KKtKbOaHR7WMpOvbURvW--g3-7fJU5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIEoC0XtCLMMCvPKITD-tFO5eT22-usQmOJ2hcHMPoosIJcjfOxy5kL5xnu0-j22COxbxK5JxbUoqRmXnJi0btQDPvxBf7p52jOLl5TtUJMqpoajlndqt4b2HjyKMniyIv9-pn5tpQrh459XP68bTkA5bjZKxtq3mkjbPbDfn028DKuDjRDKICV-frb-C62aKDs_tT2BhcqJ-ovQT3Z2Jkgyhbm2RbuLgQj0pR55l0bHxbeWfvMXn-R0hbjJM7xWeJpaJ5nJq5nhMJmKTLVbML0qto7-P3y523ihn3vQpnbhhQ3DRoWXPIqbN7P-p5Z5mAqKl0MLPbtbb0xXj_0-nDSHH-qqTFe3f; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1632240554,1632240569,1632240619,1632241001; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1632242092'
# 'Host':'fanyi.baidu.com',
# 'Origin: https':'//fanyi.baidu.com',
# 'Referer: https':'//fanyi.baidu.com/',
# 'sec-ch-ua':' "Google Chrome";v="93", " Not;A Brand";v="99", "Chromium";v="93"',
# 'sec-ch-ua-mobile':' ?0',
# 'sec-ch-ua-platform':' "Windows"',
# 'Sec-Fetch-Dest':' empty',
# 'Sec-Fetch-Mode':' cors',
# 'Sec-Fetch-Site':' same-origin',
# 'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
# 'X-Requested-With':' XMLHttpRequest'
}
# post的请求的参数,不会拼接在url的后面,而是需要放在请求对象定制的参数中
request = urllib.request.Request(url=url,data=data,headers=header)
# 模拟浏览器向服务器发送请求
res = urllib.request.urlopen(request)
content = res.read().decode(' utf-8')
# 字符串转对象,并
obj = json.loads(content)
print(obj)
'''
Request URL: https://fanyi.baidu.com/v2transapi?from=zh&to=en
from: zh
to: en
query: 煮饭
simple_means_flag: 3
sign: 308006.20503
token: d11fe3053aaca9d29f0cd89e92e4c62e
domain: common
用Notepad++可以快速都为上面这些数据添加引号和结尾的逗号:
选择正则表达式之后,查找目标 (.*):(.*) 替换为 '\1':'\2',
点击全部替换即可
'''
重要的几个参数所在位置:(这里主要用到 Request URL,Request Headers,Form Data)