ХРГцЪЕР§:ХРШЁжаЙњЬьЦјЭјЩЯЕБЕивЛжмЕФЦјЮТ
ЪзЯШдкГЬађПЊЪМДІЬэМг:
#coding:UTF-8
етбљОЭФмИцЫпНтЪЭЦїИУpyГЬађЪЧutf-8БрТыЕФ,дДГЬађжаПЩвдгажаЮФ
- ЕквЛВН:ЕМШывЊв§гУЕФАќ
import requests #гУРДХРШЁЭјвГHTMLдДДњТы
import csv #НЋЪ§ОнаДШыCSVЮФМўжа
import random #ШЁЫцЛњЪ§
import time #ЪБМфЯрЙиВйзї
import socket #socketКЭhttp.clientдкетРяжЛгУгквьГЃДІРэ
import http.client
import urllib.request #СэвЛжжХРШЁЭјвГЕФHTMLдДДњТыЕФЗНЗЈ,ЕЋЪЧВЛШчrequestsЗНБу
from bs4 import BeautifulSoup #гУРДДњЬце§дђЪНШЁдДТыжаЯргІБъЧЉжаЕФФкШн
- ЛёШЁЭјвГжаЕФHTMLДњТы
def get_content(url , data = None):
header = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',\
'Accept-Encoding':'gzip, deflate',\
'Accept-Language':'zh-CN,zh;q=0.9' ,\
'Connection': 'keep-alive',\
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'}
timeout = random.choice(range(80,180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout)
rep.encoding = 'utf-8'
break
except socket.timeout as e:
print('3:',e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print('4:',e)
time.sleep(random.choice(range(20,60)))
except http.client.BadStatusLine as e:
print('5:',e)
time.sleep(random.choice(range(30,80)))
except http.client.IncompleteRead as e:
print('6:',e)
time.sleep(random.choice(range(5,15)))
return(rep.text) #ЗЕЛиhtml_text
ЦфжаheaderЪЧrequests.getЕФвЛИіВЮЪ§,ФПЕФЪЧФЃЗТфЏРРЦїЗУЮЪЁЃheaderПЩвдгУChromeЕФПЊЗЂепЙЄОпЛёЕУ,ОпЬхЗНЗЈШчЯТ:
ДђПЊChromeНјШыжаЙњЬьЦјЭј
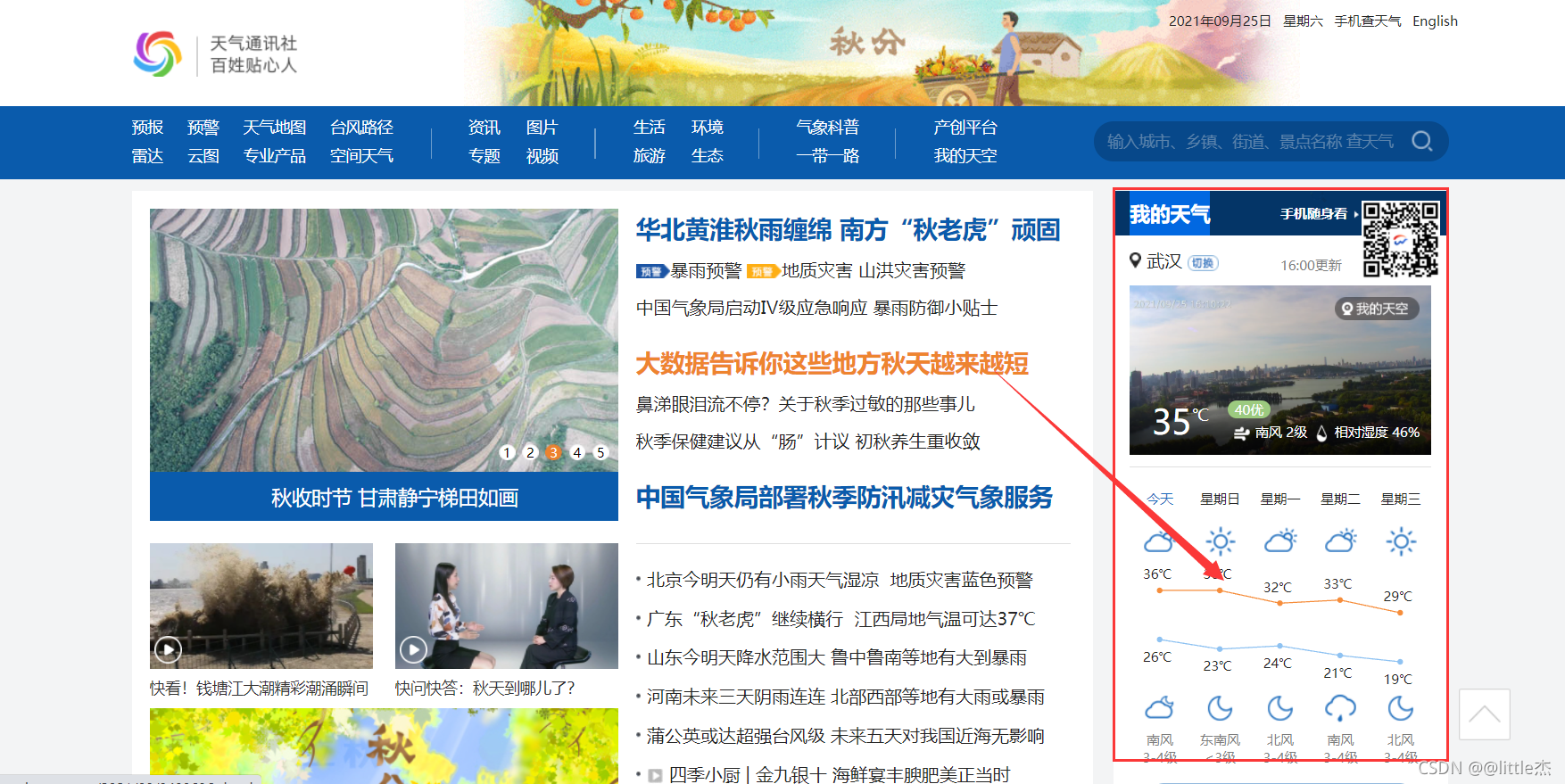
дйЪѓБъгвМќЕуЛїМьВщ
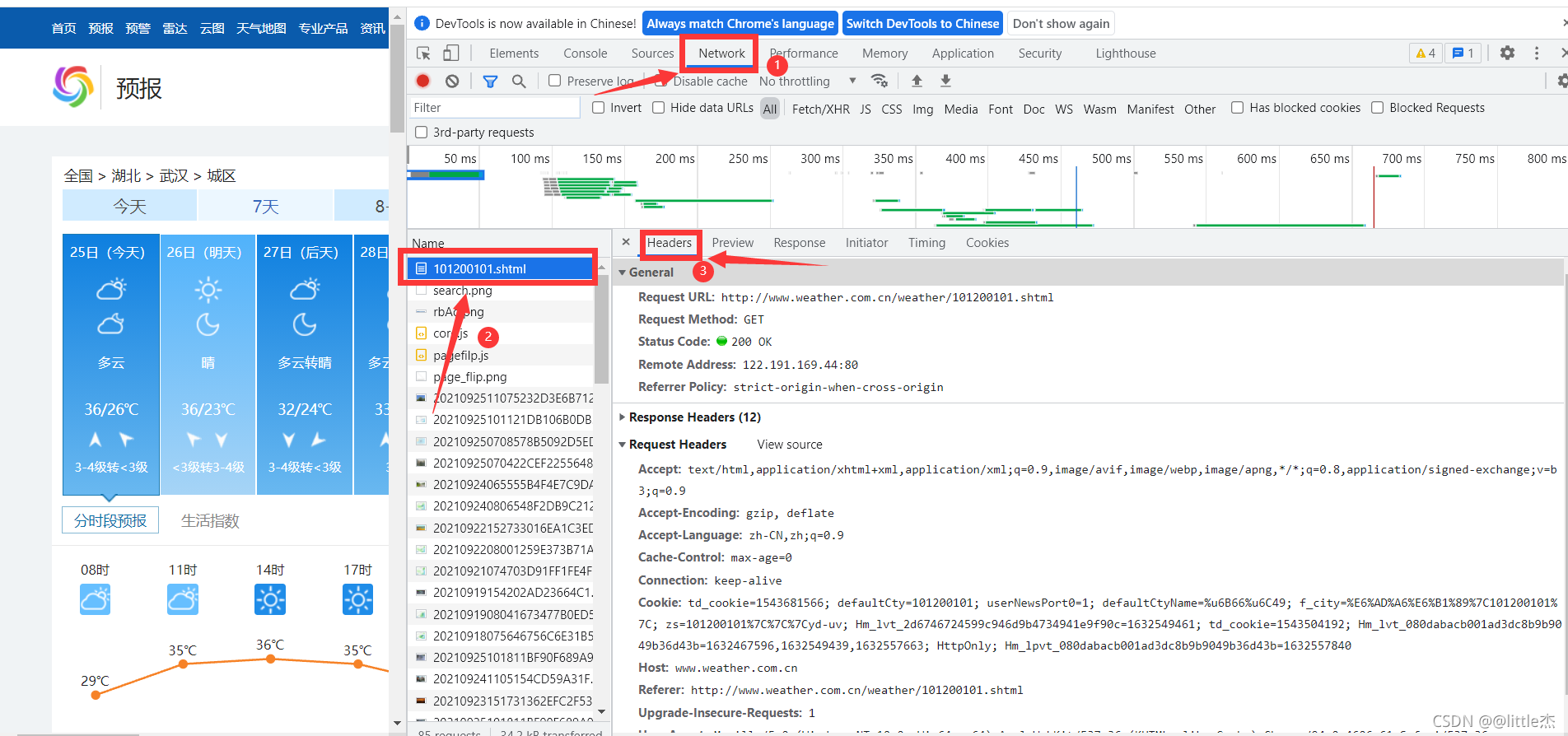
ЕуЛїNetwork,ВщПДЕквЛЬѕЭјТчЧыЧѓ,ВщПДЫќЕФheader
timeoutЪЧЩшЖЈвЛИіГЌЪБЪБМф,ШЁЫцЛњЪ§ЪЧвђЮЊЗРжЙБЛЭјеОШЯЖЈЮЊХРГц(ЦфЪЕОЭЪЧЙўЙўЙў)ШЛКѓЭЈЙ§requests.getЗНЗЈЛёШЁЭјвГЕФдДДњТы,rep.encoding = 'utf-8'ЪЧНЋдДДњТыЕФБрТыИёЪНИФЮЊutf-8,ВЛИФЕФЛА,дДДњТыжажаЮФВПЗжЛсЮЊТвТыЁЃ
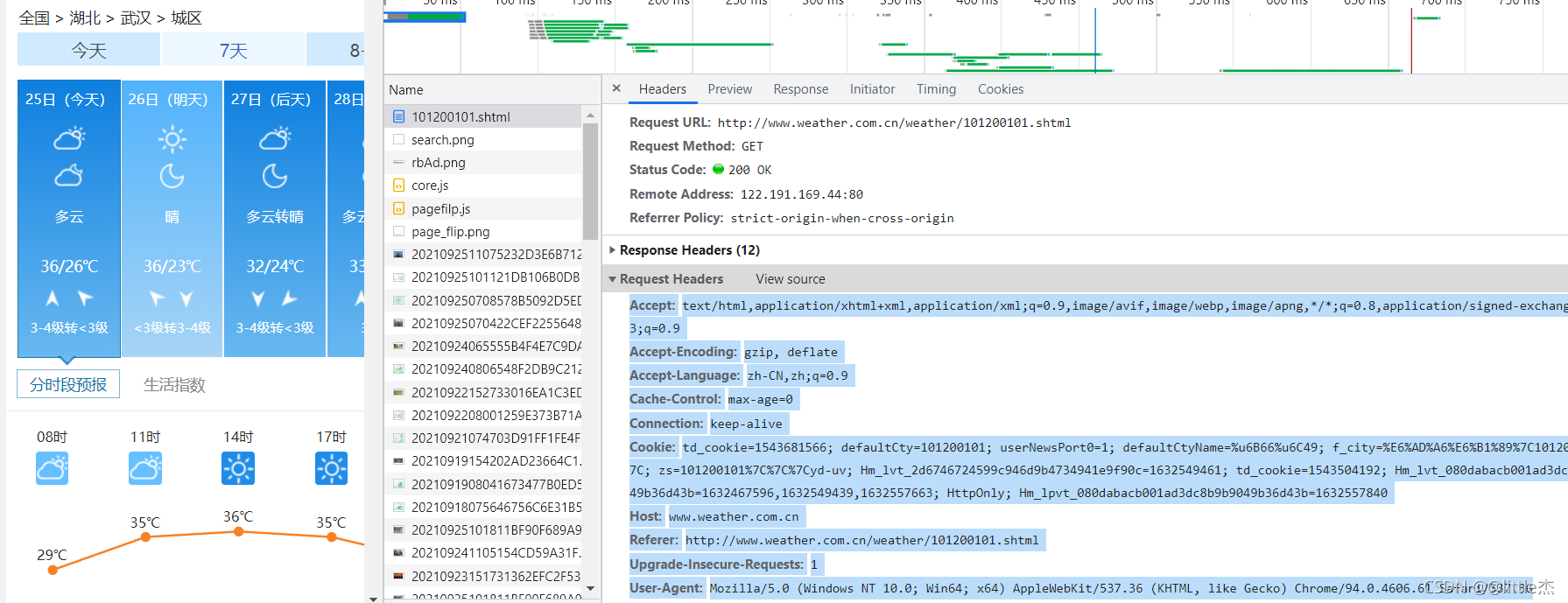
НгзХ,ЛЙЪЧгУПЊЗЂепЙЄОпВщПДЭјвГдДТы,ВЂевЕНЫљашзжЖЮЕФЯргІЮЛжУ
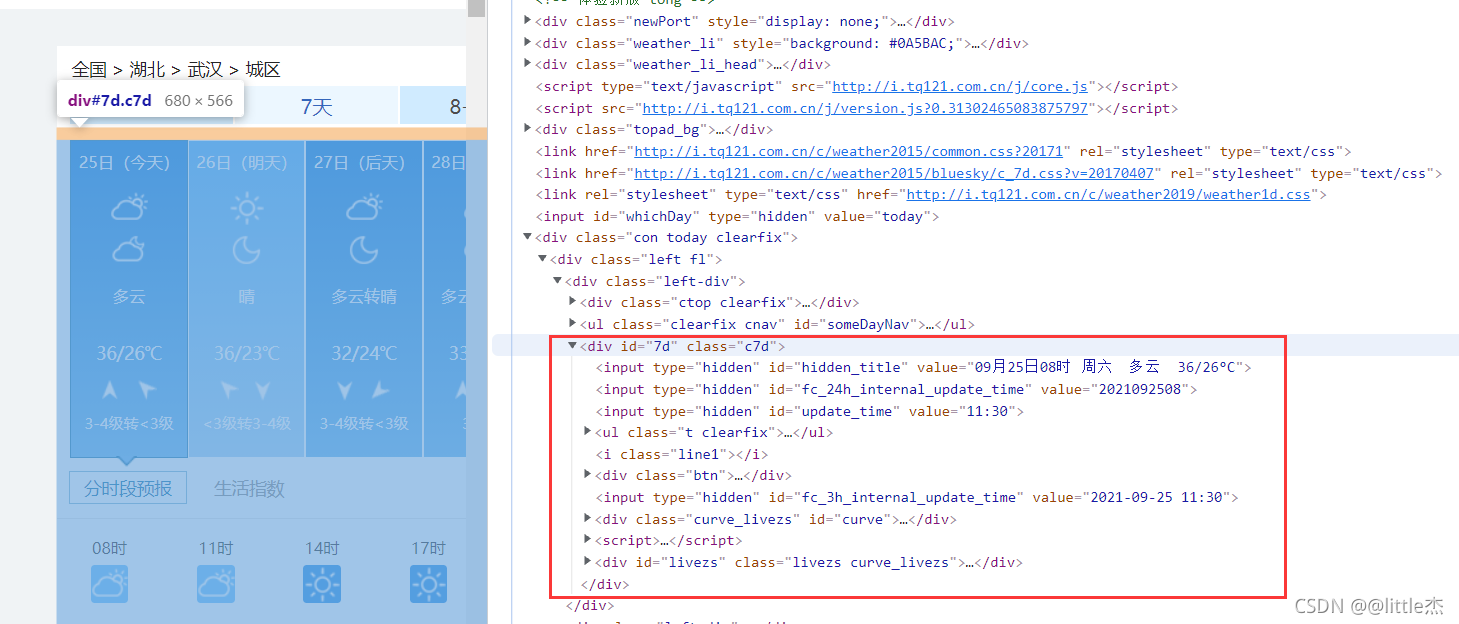
- ЮвУЧашвЊЕФзжЖЮЖМдкid="7d"ЕФЁЎЁАdivЁБЕФulжаЁЃШеЦкдкУПИіliжаhlжа,ЬьЦјЧщПідкУПИі1iЕФЕквЛИіPБъЧЉФк,зюИпЮТЖШКЭЪЧзюЕЭЮТЖШдкУПИіliЕФspanКЭiБъЧЉжаЁЃЕНСЫАјЭэ,ашвЊевЕНЕБЬьзюИпЮТЖШ,ЫљвдвЊЖрМгвЛИіХаЖЯЁЃ
ДњТыШчЯТ:
def get_data(html_text):
final = []
bs = BeautifulSoup(html_text,"html.parser") #ДДНЈbeautifulsoupЖдЯѓ
body = bs.body #ЛёШЁbodyВПЗж
data = body.find('div',{'id':'7d'}) #евЕНidЮЊ7dЕФdiv
ul = data.find('ul') #ЛёШЁulВПЗж
li = ul.find_all('li') #ЛёШЁЫљгаЕФliВПЗж
for day in li: #ЖдУПИіliБъЧЉжаЕФФкШнНјааБщРњ
temp = []
date = day.find('h1').string #евЕНШеЦк
temp.append(date) #ЬэМгЕНtempжа
inf = day.find_all('p') #евЕНliжаЕФЫљгаpБъЧЉ
temp.append(inf[0].string,) #ЕквЛИіpБъЧЉжаЕФФкШн(ЬьЦјзДПі)МгЕНtempжа
if inf[1].find('span') is None:
temperature_highest = None#ЬьЦјдЄБЈПЩФмУЛгаЕБЬьЕФзюИпЦјЮТ(ЕНСЫАјЭэ,ОЭЪЧетбљ)
#ашвЊМгИіХаЖЯгяОф,РДЪфГізюЕЭЦјЮТ
else:
temperature_highest = inf[1].find('i').string #евЕНзюИпЮТЖШ
temperature_highest = temperature_highest.replace('Ёц','')
temperature_lowest = inf[1].find('span').string #евЕНзюЕЭЮТЖШ
temperature_lowest = temperature_lowest.replace('Ёц','')
temp.append(temperature_highest) #НЋзюИпЮТЬэМгЕНtempжа
temp.append(temperature_lowest) #НЋзюЕЭЮТЬэМгЕНtempжа
final.append(temp) #НЋtempЬэМгЕНfinalжа
return final
- аДШыЮФМўCSV,НЋЪ§ОнХРГіРДКѓвЊНЋЫћУЧаДШыЮФМў,ОпЬхДњТыШчЯТ:
def write_data(data,name):
file_name = name
with open(file_name,'a',errors = 'ignore',newline = '') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
- жїКЏЪ§
if __name__ == '__main__':
url = 'http://www.weather.com.cn/weather/101200101.shtml'
html = get_content(url)
result = get_data(html)
write_data(result,'weather.csv')
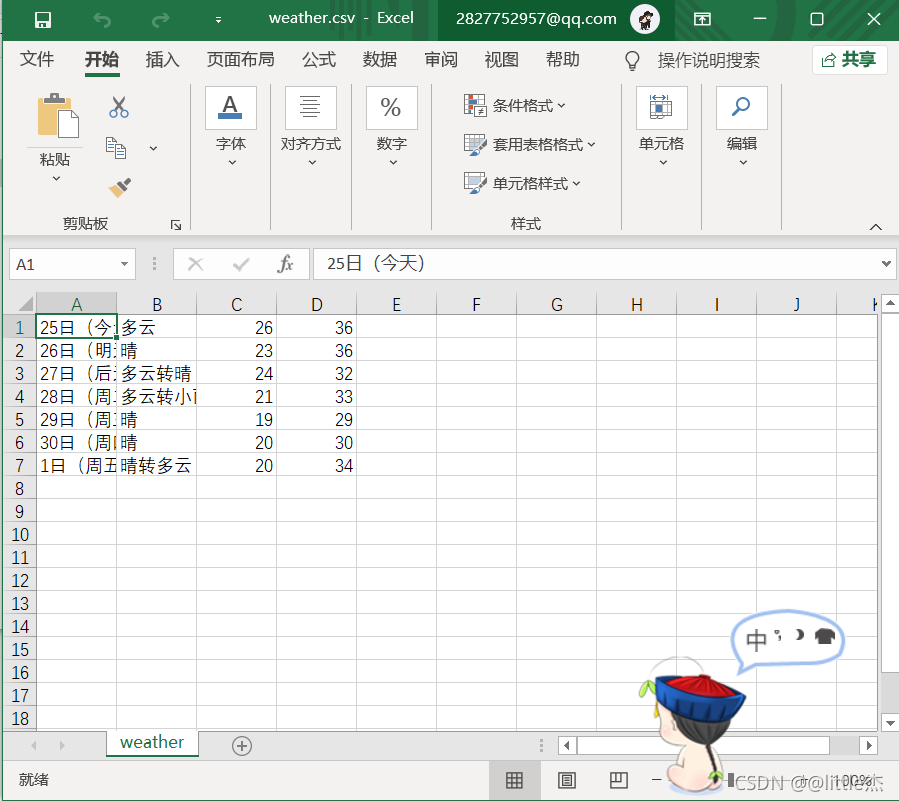
дЫааГЬађЩњГЩЕФweather.csvЮФМўШчЯТЭМЫљЪО: