��ǰ����:����ּ�ڽ�������,���ذ�Ȩ����ԭ��,��ѧ����,��������Υ��;��,��ȫʹ�ü���,����ʹ�ò������²������,���˸Ų�����
������Դ
�����ѧѧӢ��,���˼����γ�,���潨�鿴������,�����Ƽ��˼�������Ӧ�û�����,��û����,����Ȥ�Ŀ��Գ��!!
Ӱ��Ŀ¼����:
- �����ȡ�
- ��ʱ��Ůħͷ��
- ���ж�Ŀ��ϣ���ա�
�����Ƽ��ˡ�����Ӱ��������Դ,��֪�������Լ��������������Ϊ��վ���������ⲿ��������ԭ��,һ�뿨����,���߲��ž���ʹ��,���Ծ�������������,˳��Ϊ������������Ķڵ����,Ϊ�˿��������Ҳ��ƴ�ˡ�
�������
�����ԡ����ȡ�Ϊ��,������ģʽ��ѯ���紫��,���ҵ�m3u8������,������˫��Ƕ��,���Ǻ���û�м���,
���ܵ���ʱûɶ�취,�����кܶస��,���˺ö�û�ɹ�
����һ��:m3u8��һ����ý���ʽ,���ļ��б�����ʽ����,�����¼�˰汾�š����ܷ�ʽ���ļ��б�����Ϣ
����ͼ��ʾ,���ҵ���һ�������ļ�
 ֱ�Ӹ�������url�������,����m3u8�ļ�,ʹ�ü��±�/notepad++��,�ļ���������,����ŵ�����ʵm3u8�ļ�·��
ֱ�Ӹ�������url�������,����m3u8�ļ�,ʹ�ü��±�/notepad++��,�ļ���������,����ŵ�����ʵm3u8�ļ�·��

����һ��,�ҵ�һ��ts,��������ǰ������·��

��ǰ�����·����ǰ���һ���m3u8·��ƴ��
�õ���ʵm3u8����
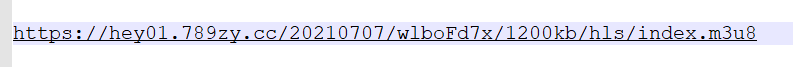
�ظ�ǰ�沽��:���������Ӹ��Ƶ�������C>����
����͵õ���ȫ����ts·����˳��,���������ϲ��Ϳ�����

����ʾ��
import requests,os
def download_ts_file(url,num,total):
"""����ts�ļ�����"""
# ����������Լ���,Ҳ����ʹ�� fake_useragent �����������ͷ
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
response=requests.get(url,headers=headers)
data = response.content
file_name = url.split("/")[-1]
ts_path = os.path.join(tmp_path,file_name)
with open(ts_path,'wb') as f:
f.write(data)
f.close()
print(f"�ڡ�{num+1}/{total}����tsƬ��{file_name}�������")
return None
# ts��ʱ�洢·��
tmp_path = os.path.join(os.getcwd(),"tmp_path")
# ��ȡ������ts����
f = open("index.m3u8","r",encoding="utf-8")
m3u8 = f.readlines()
f.close()
url_list = [url.split("\n")[0] for url in m3u8 if "https" in url]
# ѭ�����ظ���tsƬ��--�������ʹ�ö��߳�,������ڰ�ȫ����û�м���,����Ȥ�Ŀ����Լ�����
[download_ts_file(url,url_list.index(url),len(url_list)) for url in url_list]
----------��Ҫ������˵����,ע�ⰲȫע�ⰲȫע�ⰲȫ--------
----------��Ҫ������˵����,ע�ⰲȫע�ⰲȫע�ⰲȫ--------
----------��Ҫ������˵����,ע�ⰲȫע�ⰲȫע�ⰲȫ--------
����������������������������������������������������������������������������������������������������������
-----------�ָ���,���߳��ٶ�����,ע�ⰲȫŶ!----------
-----------���������ö��̵߳�,�κε��߳�ʵ��̫��----------
import requests,os
def download_ts_file(num,url_list):
"""����ts�ļ�����"""
url,total = url_list[num],len(url_list)
# ����������Լ���,Ҳ����ʹ�� fake_useragent �����������ͷ
headers={'User-Agent':'xxxxx'}
response=requests.get(url,headers=headers)
data = response.content
file_name = url.split("/")[-1]
ts_path = os.path.join(tmp_path,file_name)
with open(ts_path,'wb') as f:
f.write(data)
f.close()
print(f"�ڡ�{num+1}/{total}����tsƬ��{file_name}�������")
return None
# ts��ʱ�洢·��
tmp_path = os.path.join(os.getcwd(),"tmp_path")
# ��ȡ������ts����
f = open("index.m3u8","r",encoding="utf-8")
m3u8 = f.readlines()
f.close()
url_list = [url.split("\n")[0] for url in m3u8 if "https" in url]
# ѭ�����ظ���tsƬ��--�������ʹ�ö��߳�,������ڰ�ȫ����û�м���,����Ȥ�Ŀ����Լ�����
from concurrent.futures import ThreadPoolExecutor # �̳߳�
p = ThreadPoolExecutor(8)
for num in range(len(url_list)):
p.submit(download_ts_file, num,url_list)
��������������������������������������������һ���ָ��ߡ���������������������������
������������������������������������ô��ts�ϳɳ�MP4��ʽ��������������������
#����һ:ֱ�Ӷ�ȡд��,ע�ⰴ��m3u8�ļ�������˳���ȡд��
import os
# ts��ʱ�洢·��
tmp_path = os.path.join(os.getcwd(),"tmp_path")
# ��ȡ������ts����
f = open("index.m3u8","r",encoding="utf-8")
m3u8 = f.readlines()
f.close()
url_list = [url.split("\n")[0] for url in m3u8 if "https" in url]
with open('����2019.mp4','wb') as f2:
for url in url_list:
file_name = url.split("/")[-1]
ts_path = os.path.join(tmp_path,file_name)
f1 = open(ts_path,"rb")
data = f1.read()
f1.close()
f2.write(data)
f2.close()
�ϲ�ts����һ�ַ���,��������ֻ�ܺϲ�450��,���������Ǵ���Ƶ������,�����˽�ο���,��Ȼ�з���������bug,���ﲻϸ����,����Ȥ���Լ���������
���չʾ



