前言
上周接到一个活,说是分析一下机房新设备的告警日志,我没当回事,直到周五的时候看到40W+的告警日志之后,我炸了。
老设备平常一周也不过上万条,涉及规则20来个,一天就分析完了,新设备上来就是40W+的告警次数,涉及规则300+,最最痛苦的还是,虽然我能看到告警事件排名,虽然设备还不支持导出排名信息,虽然我还能接受手工复制每页的排名信息,但是,300+的规则好几页,设备无法完成翻页操作,卡出翔了!!!唯一的突破口,就是直接处理40W+的日志,python在手,冲冲冲
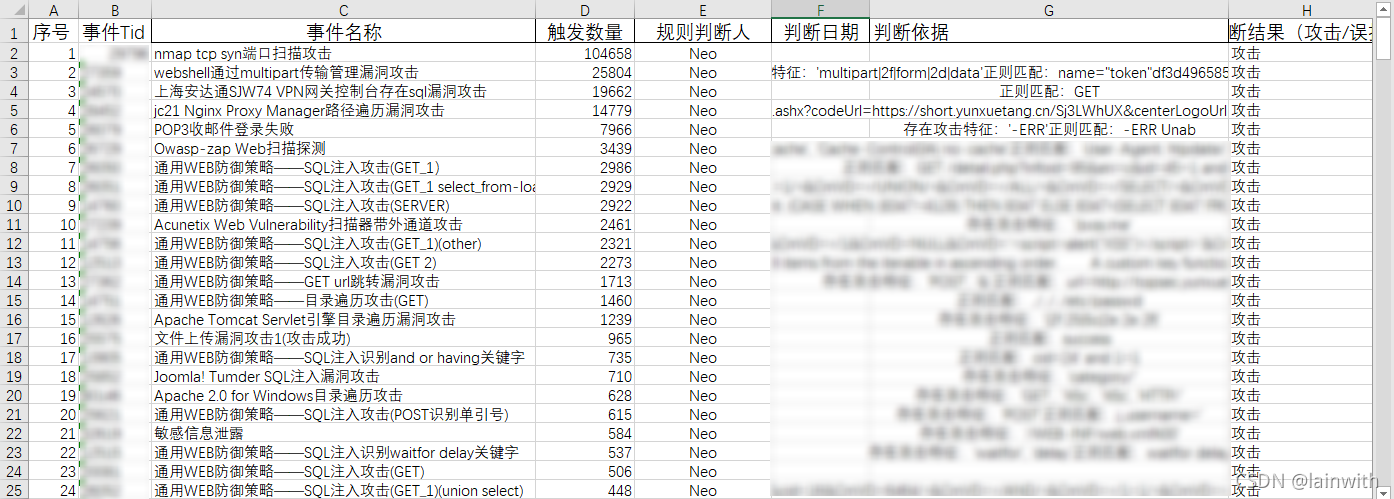
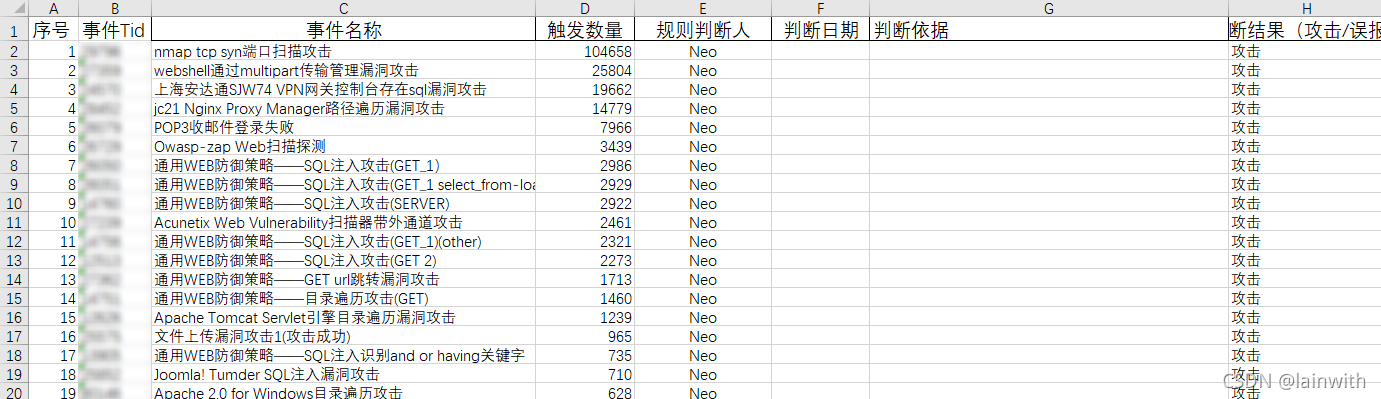
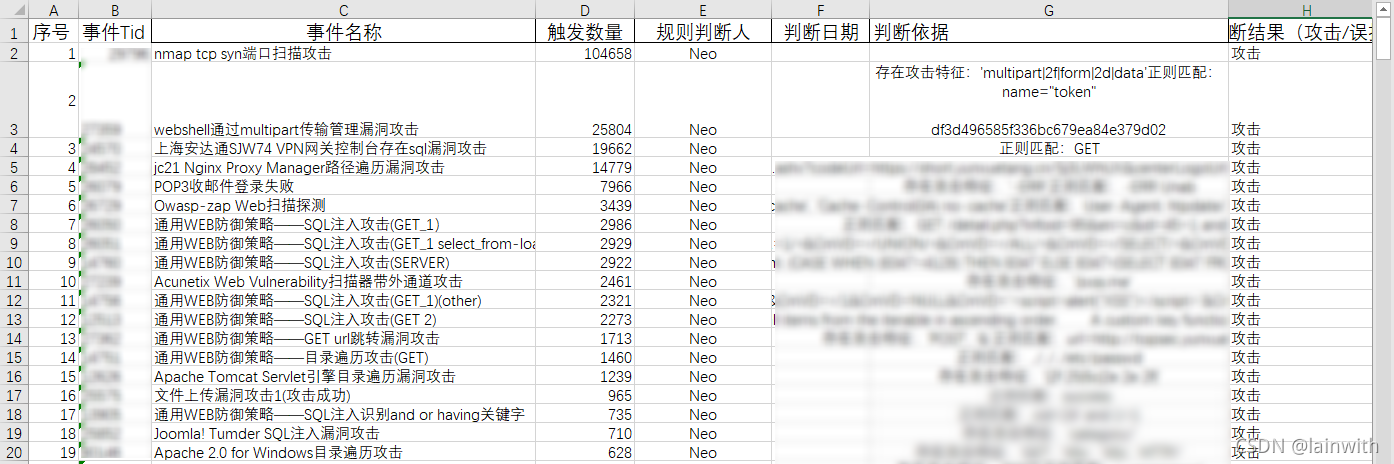
最终要提交的,举个例子,是如下的样子
要提交的报告,从图片中可以看出:
- 事件Tid、事件名称、触发数量、判断依据,这4列的顺序是绑定的
- 表格制作思路是:
- 先获取到所有的tid,并进行次数统计
- 根据tid找到对应的事件名称
- 根据tid找到对应的数据包,对数据包进行分析
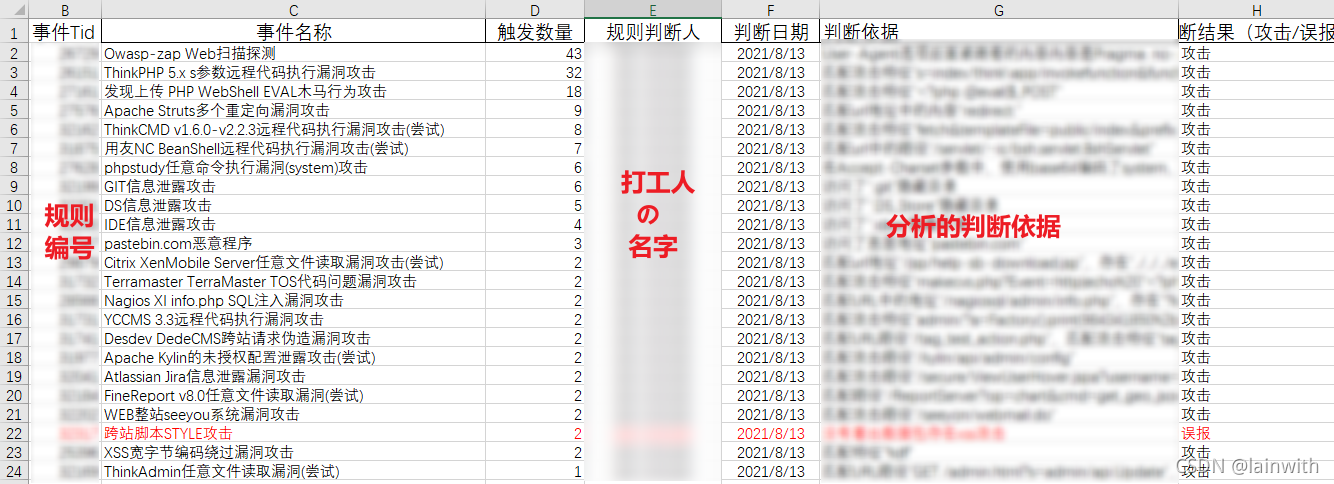
需求分析:
- 脚本要实现对原始的40W+告警信息做一个排名处理,获知究竟涉及哪些规则,以及触发数量
- 对于判断依据,最好可以使用脚本,实现规则明文与取证包匹配,并拿到匹配结果
获取攻击统计排名
首先下载所有的告警事件,有4个CSV文件,手工复制出所有的规则编号,存放到一个txt本文中即可跑脚本了。
注意:需要手动在第19行指明文件路径,脚本会在桌面生成测试结果
from collections import Counter
import os
import re
'''
脚本主要是针对超大规模的txt文档
'''
# 使用正则处理排序之后的结果
def deal_result(demo):
a = re.sub(r'Counter\({', '', demo)
b = re.sub(r'}\)', '', a)
c = re.sub(r'\'', '', b)
d = re.sub(r'\\n\x3a\s+', '\t', c)
e = re.sub(r',\s+', '\n', d)
return e
word = [] # 存储用户输入的内容
with open(r'C:\Users\asuka\Desktop\alltid.txt', encoding='utf-8') as f:
for line in f:
if line == '':
continue
word.append(line)
# print(line, end='')
result = Counter(word) # 拿到原始的排序结果
str_result = str(result)
print('对你输入的内容进行次数统计:')
new_result = deal_result(str_result) # 拿到经过处理之后的结果
print(new_result)
# 把结果写入到txt文档中
desktop_path = os.path.join(os.path.expanduser("~"), 'Desktop')
write_path = os.path.join(desktop_path, '内容去重_结果统计.txt')
a = open(write_path, 'w', encoding='utf8')
a.write(new_result)
a.close()
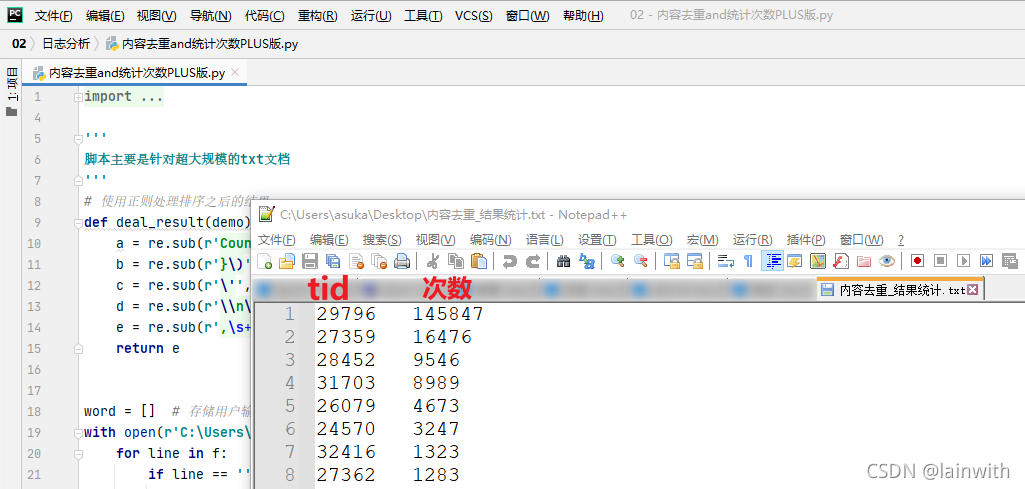
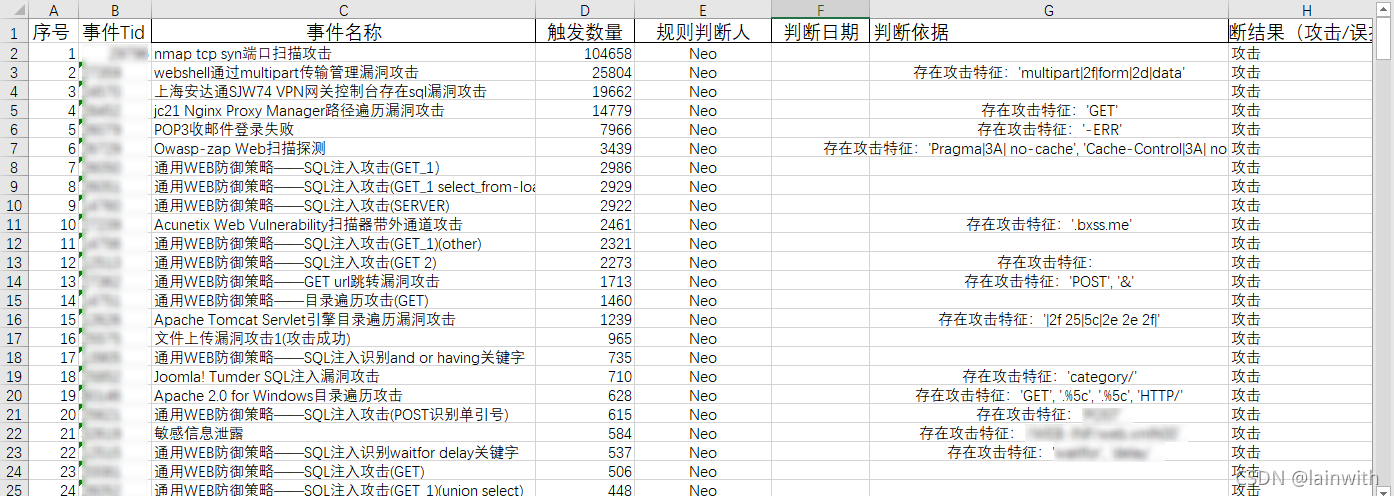
接下来就是一些简单的后续处理了,再利用Excel排序的一点技巧,就能获取如下图所示的图表了。
获取“判断依据”
核心逻辑,就是使用python读取规则明文,然后去跟取证包匹配,并把匹配的结果写到Excel表中。相当于是一个安全开发的工具了。
content版
一种思路是,从规则中提取出content关键字里的内容,将其填写到Excel表中。
脚本的逻辑是:
- 拿到所有规则对应的规则明文
- 遍历规则明文的每一行,分离出content和规则编号tid,存储到一个字典中。键:tid;值:content
- 拿着excel表第2列中的tid去遍历字典中的键,一旦匹配,就写入对应的值
通过修改第31、32行的代码,指明规则和excel的路径即可。
import re
import openpyxl
import pprint
all_message = {} # 用来存储tid及它的content内容
# 用来从规则明文中提取出tid和content中的内容
def get_tid_content():
with open(rules_path, 'rb') as f:
contents = f.readlines()
for line in contents: # 按行读取
line = line.decode('gbk')
if line == '':
continue
if "content" in line: # 对包含content关键字的规则进行处理
message = re.findall(r'content\x3a\x22(.*?)\x22', line) # 获取content中的内容
tid = re.findall(r'tid\x3a(\d+)', line) # 获取tid
# 获取到字符串格式的tid
re_tid = tid[0]
# 提取到字符串格式的message
message1 = str(message).replace('[', '').replace(']', '')
re_message = "存在攻击特征:" + message1
all_message[re_tid] = re_message # 加入到字典中
return all_message
rules_path = r'C:\Users\asuka\Desktop\xxx.txt'
excel_path = r'C:\Users\asuka\Desktop\test.xlsx'
get_tid_content()
workbook = openpyxl.load_workbook(excel_path) # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('当前活动表是:' + str(sheet))
rows = sheet.max_row # 获取行数,值是int型
print('tid位于第2列')
tid_column = 2 # tid所在的列
evidence_column = 7 # "判断依据所在的列"
for i in range(1, rows + 1):
if sheet.cell(i, tid_column).value in all_message.keys(): # 如果单元格中的值在all_message中找到了
# 把键对应的值写到"判断依据所在的列",如果值不存在,就写入“NULL”
sheet.cell(i, evidence_column, all_message.get(sheet.cell(i, tid_column).value, 'NULL'))
workbook.save(excel_path) # 保存excel表
workbook.close() # 关闭Excel表格
print('操作结束')
正则版
脚本的逻辑:
-
运行脚本,它首先从规则中提取出规则tid和第一个pcre(如果存在多个正则的话),将其存放到字典info中。
键:tid;值:pcre
-
根据提取到的tid,去遍历所有的数据包,获取其绝对路径
考虑到一个tid对应多个数据包,这里会做去重,一个tid只记录一个数据包的绝对路径到字典info中
-
拿着数据包的绝对路径和pcre,去匹配出数据包的内容,并把匹配结果添加到字典info中
此时,一个合格的tid,对应的值必须有三个元素:pcre、数据包绝对路径、正则匹配的结果
-
将结果写入到excel表中
正则版的脚本,很贴心的一点是写入excel之前,会检查单元格中是否有数据,没得话直接写,有的话会合并之前的数据。
修改97~99行,指定文件路径即可:
import urllib.parse
from scapy.all import *
import re
import openpyxl
logging.getLogger("scapy.runtime").setLevel(logging.ERROR) # 清除报错
# 从数据包中,使用正则提取出内容,加入到字典中
def pcap_parser(filename, keyword):
flag = True # 一个标志位,用于处理正则测试数据包
pkts = rdpcap(filename)
for pkt in pkts.res:
try: # decode编码实体内容的时候容易出错,使用异常处理
pkt_load = pkt.getlayer('Raw').fields['load'].decode().strip() # 提取负载内容,即wireshatk追踪流看到的东西
pkt_load = urllib.parse.unquote(pkt_load) # 全文做url解码
re_keyword = keyword # 使用正则过滤出数据
if re.search(re_keyword, pkt_load, re.I):
match_re = re.search(re_keyword, pkt_load, re.I).group() # 匹配上的内容
print(os.path.basename(filename) + '\t' + '匹配成功:' + '\t' + match_re)
pcap_path_tid = filename.split('.', 1)[0].split('Event')[-1] # 从数据包的绝对路径中提取出tid编号
info[pcap_path_tid].append(match_re) # 将匹配上的内容加入到info字典中
flag = False
break
except:
pass
if flag:
print(os.path.basename(filename) + '\t' + '匹配失败!')
# 从字典中提取正则匹配的结果,写入到excel表中
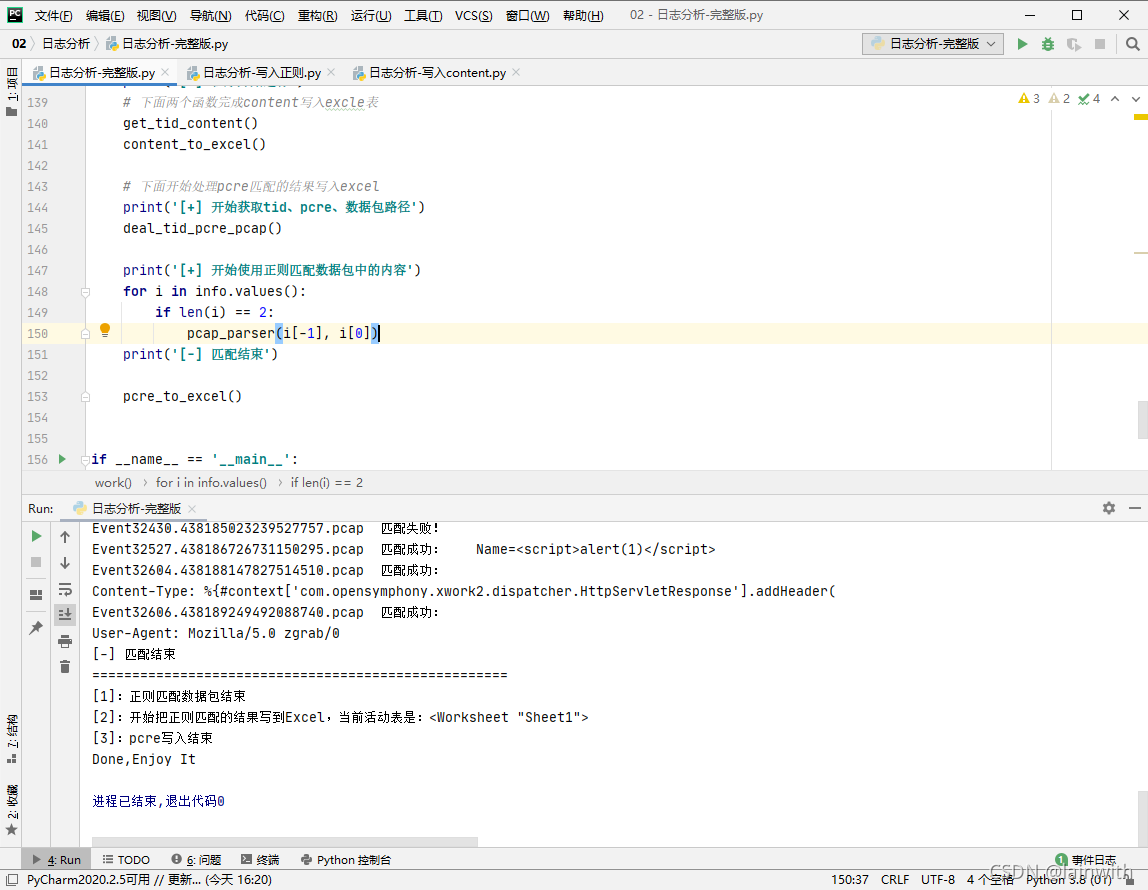
def pcre_to_excel():
workbook = openpyxl.load_workbook(excel_path) # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('====================================================')
print('[1]:正则匹配数据包结束')
print('[2]:开始把正则匹配的结果写到Excel,当前活动表是:' + str(sheet))
rows = sheet.max_row # 获取行数,值是int型
for i in range(1, rows + 1):
if sheet.cell(i, tid_column).value in info.keys(): # 如果单元格中的tid值在info字典中找到了
# 把键对应的值写到"判断依据所在的列"
if len(info[sheet.cell(i, tid_column).value]) == 3: # info字典"值"长度为3,说明正则匹配的有结果
# info字典"值"的最后一个是正则匹配的结果,将"判断依据"中包含的内容,与正则匹配的内容合并到一个单元格中
if sheet.cell(i, evidence_column).value is None: # 如果单元格是空白的,就直接写数据
# print('##############写入数据:')
# print('正则匹配:' + info[sheet.cell(i, tid_column).value][-1])
sheet.cell(i, evidence_column, '正则匹配:' + info[sheet.cell(i, tid_column).value][-1])
else: # 如果单元格有内容,合并内容
excel_value = str(sheet.cell(i, evidence_column).value) + '正则匹配:' + \
info[sheet.cell(i, tid_column).value][-1]
# print('%%%%%%%%%%%%%%合并数据:')
# print(excel_value)
sheet.cell(i, evidence_column, excel_value)
workbook.save(excel_path) # 保存excel表
workbook.close() # 关闭Excel表格
print('[3]:pcre写入结束')
# 预处理,下面三个for循环实现:将tid和正则、数据包绝对路径绑定到一个字典中
def deal_tid_pcre_pcap():
abs_pcap_filepath = [] # 用一个列表用来存储获取到的所有数据包的绝对路径
with open(rules_path, 'rb') as f: # 读取规则文件
contents = f.readlines()
# 获取到tid对应的正则
for line in contents:
line = line.decode('gbk')
tid = re.findall(r'tid\x3a(\d+)', line) # 获取tid
pcre = re.findall(r'pcre\x3a\x22\x2f(.*?)\x2f\w{0,4}\x22\x3b', line) # 获取pcre中的内容
if len(pcre) == 0: # 如果不加这样一个判断,正则可能取值是空,会导致写入字典失败
continue
info[tid[0]] = [pcre[0]] # 正则不要太多,取其中1个就行了。将正则与tid绑定
# print('=======================')
# print(pcre)
# 获取到tid对应的数据包
for current_folder, list_folders, files in os.walk(files_path):
for f in files: # 用来遍历所有的文件,只取文件名,不取路径名
if f.endswith('pcap') or f.endswith('pcapng'): # 操作数据包
file_path = current_folder + '\\' + f # 获取数据包的绝对路径
abs_pcap_filepath.append(file_path)
# 由于一个tid可能存在多个数据包,这里对abs_pcap_filepath去重,一个tid只保留一个数据包
for re_tid in info.keys(): # 遍历字典tid_pcre
for i in abs_pcap_filepath:
pcap_name = os.path.basename(i) # 获取数据包的基本名称,即文件名
if re_tid in pcap_name.split('.', 1)[0]: # 如果tid出现在数据包的文件名中
info[re_tid].append(i)
break
info = {}
files_path = r"C:\Users\asuka\Desktop\all" # 数据包所在的文件夹
excel_path = r'C:\Users\asuka\Desktop\test.xlsx' # excel表的路径
rules_path = r'C:\Users\asuka\Desktop\xxx.txt'
tid_column = 2 # tid所在的列
evidence_column = 7 # "判断依据所在的列"
print('[+] 程序开始运行')
print('[+] 开始获取tid、pcre、数据包路径')
deal_tid_pcre_pcap()
# print('结束')
print('[+] 开始使用正则匹配数据包中的内容')
for i in info.values():
if len(i) == 2:
pcap_parser(i[-1], i[0])
print('[-] 匹配结束')
pcre_to_excel()
print('Enjoy It')
由于使用过content版的脚本之后,没有清空单元格,所以正则版的脚本会追加内容到content中来
完整版
完整版就是综合了上述二者。
脚本的逻辑是:首先读取规则库,单独提取出content,直接写到excel中,然后单独提取出正则,与经过url解码的数据包明文匹配,将匹配结果追加到Excel表中
import openpyxl
import re
import pprint
import logging
import urllib.parse
from scapy.all import *
logging.getLogger("scapy.runtime").setLevel(logging.ERROR) # 清除报错
# 用来从规则明文中提取出tid和content中的内容
def get_tid_content():
with open(rules_path, 'rb') as f:
contents = f.readlines()
for line in contents: # 按行读取
line = line.decode('gbk')
if line == '':
continue
if "content" in line: # 对包含content关键字的规则进行处理
message = re.findall(r'content\x3a\x22(.*?)\x22', line) # 获取content中的内容
tid = re.findall(r'tid\x3a(\d+)', line) # 获取tid
# 获取到字符串格式的tid
for i in tid:
re_tid = i
# 提取到字符串格式的message
message1 = str(message).replace('[', '').replace(']', '')
re_message = "存在攻击特征:" + message1
all_message[re_tid] = re_message # 加入到字典中
return all_message
# 用来执行收集到的content写入到excel表操作
def content_to_excel():
workbook = openpyxl.load_workbook(excel_path) # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('[+] 开始写入content匹配的结果,当前活动表是:' + str(sheet))
rows = sheet.max_row # 获取行数,值是int型
for i in range(1, rows + 1):
if sheet.cell(i, tid_column).value in all_message.keys(): # 如果单元格中的值在all_message中找到了
# 把键对应的值写到"判断依据所在的列",如果值不存在,就写入“NULL”
sheet.cell(i, evidence_column, all_message.get(sheet.cell(i, tid_column).value, 'NULL'))
workbook.save(excel_path) # 保存excel表
workbook.close() # 关闭Excel表格
print('[-] content写入结束')
# 从数据包中,使用正则提取出内容,加入到字典中
def pcap_parser(filename, keyword):
flag = True # 一个标志位,用于处理正则测试数据包
pkts = rdpcap(filename)
for pkt in pkts.res:
try: # decode编码实体内容的时候容易出错,使用异常处理
pkt_load = pkt.getlayer('Raw').fields['load'].decode().strip() # 提取负载内容,即wireshatk追踪流看到的东西
pkt_load = urllib.parse.unquote(pkt_load) # 全文做url解码
re_keyword = keyword # 使用正则过滤出数据
if re.search(re_keyword, pkt_load, re.I):
match_re = re.search(re_keyword, pkt_load, re.I).group() # 匹配上的内容
print(os.path.basename(filename) + '\t' + '匹配成功:' + '\t' + match_re)
pcap_path_tid = filename.split('.', 1)[0].split('Event')[-1] # 从数据包的绝对路径中提取出tid编号
info[pcap_path_tid].append(match_re) # 将匹配上的内容加入到info字典中
flag = False
break
except:
pass
if flag:
print(os.path.basename(filename) + '\t' + '匹配失败!')
# 从字典中提取正则匹配的结果,写入到excel表中
def pcre_to_excel():
workbook = openpyxl.load_workbook(excel_path) # 返回一个workbook数据类型的值
sheet = workbook.active # 获取活动表
print('====================================================')
print('[1]:正则匹配数据包结束')
print('[2]:开始把正则匹配的结果写到Excel,当前活动表是:' + str(sheet))
rows = sheet.max_row # 获取行数,值是int型
for i in range(1, rows + 1):
if sheet.cell(i, tid_column).value in info.keys(): # 如果单元格中的tid值在info字典中找到了
# 把键对应的值写到"判断依据所在的列"
if len(info[sheet.cell(i, tid_column).value]) == 3: # info字典"值"长度为3,说明正则匹配的有结果
# info字典"值"的最后一个是正则匹配的结果,将"判断依据"中包含的内容,与正则匹配的内容合并到一个单元格中
if sheet.cell(i, evidence_column).value is None: # 如果单元格是空白的,就直接写数据
# print('##############写入数据:')
# print('正则匹配:' + info[sheet.cell(i, tid_column).value][-1])
sheet.cell(i, evidence_column, '正则匹配:' + info[sheet.cell(i, tid_column).value][-1])
else: # 如果单元格有内容,合并内容
excel_value = str(sheet.cell(i, evidence_column).value) + '正则匹配:' + \
info[sheet.cell(i, tid_column).value][-1]
# print('%%%%%%%%%%%%%%合并数据:')
# print(excel_value)
sheet.cell(i, evidence_column, excel_value)
workbook.save(excel_path) # 保存excel表
workbook.close() # 关闭Excel表格
print('[3]:pcre写入结束')
# 预处理,下面三个for循环实现:将tid和正则、数据包绝对路径绑定到一个字典中
def deal_tid_pcre_pcap():
abs_pcap_filepath = [] # 用一个列表用来存储获取到的所有数据包的绝对路径
with open(rules_path, 'rb') as f: # 读取规则文件
contents = f.readlines()
# 获取到tid对应的正则
for line in contents:
line = line.decode('gbk')
tid = re.findall(r'tid\x3a(\d+)', line) # 获取tid
pcre = re.findall(r'pcre\x3a\x22\x2f(.*?)\x2f\w{0,4}\x22\x3b', line) # 获取pcre中的内容
if len(pcre) == 0: # 如果不加这样一个判断,正则可能取值是空,会导致写入字典失败
continue
info[tid[0]] = [pcre[0]] # 正则不要太多,取其中1个就行了。将正则与tid绑定
# 获取到tid对应的数据包
for current_folder, list_folders, files in os.walk(files_path):
for f in files: # 用来遍历所有的文件,只取文件名,不取路径名
if f.endswith('pcap') or f.endswith('pcapng'): # 操作数据包
file_path = current_folder + '\\' + f # 获取数据包的绝对路径
abs_pcap_filepath.append(file_path)
# 由于一个tid可能存在多个数据包,这里对abs_pcap_filepath去重,一个tid只保留一个数据包
for re_tid in info.keys(): # 遍历字典tid_pcre
for i in abs_pcap_filepath:
pcap_name = os.path.basename(i) # 获取数据包的基本名称,即文件名
if re_tid in pcap_name.split('.', 1)[0]: # 如果tid出现在数据包的文件名中
info[re_tid].append(i)
break
# 负责调动上面所有函数
def work():
print('[+] 程序开始运行')
# 下面两个函数完成content写入excle表
get_tid_content()
content_to_excel()
# 下面开始处理pcre匹配的结果写入excel
print('[+] 开始获取tid、pcre、数据包路径')
deal_tid_pcre_pcap()
print('[+] 开始使用正则匹配数据包中的内容')
for i in info.values():
if len(i) == 2:
pcap_parser(i[-1], i[0])
print('[-] 匹配结束')
pcre_to_excel()
if __name__ == '__main__':
all_message = {} # 用来存储tid及它的content内容
info = {} # 一个用来存储tid、tid对应的正则、tid对应的数据包的字典
tid_column = 2 # tid所在的列
evidence_column = 7 # "判断依据所在的列"
excel_path = r'C:\Users\asuka\Desktop\test.xlsx' # excel表的路径
rules_path = r'C:\Users\asuka\Desktop\xxx.txt'
files_path = r"C:\Users\asuka\Desktop\all" # 数据包所在的文件夹
work()
print('Done,Enjoy It')