1,异常处理机制
Python的异常处理机制可以让程序具有极好的容错性,让程序更加健壮。当程序运行出现意外情况时,系统会自动生成一个Error对象来通知程序,从而实现将“业务实现代码”和“错误处理代码”分离,提供更好的可读性。???
1.1,使用try...except捕捉异常
Python提出一种假设:如果程序可以顺利完成,那就“一切正常”,把系统的业务实现代码放在try块中定义,把所有的异常处理逻辑放在except块中进行处理。
在异常处理语法结构中,只有try块是必须的,也就是说,如果没有try块,则不能有后面的except块和finally块;except块和finally块都是可选的,但except块和finally块至少出现其中之一,也可以同时出现;可以有多个except块,但捕获父类异常的except块应该位于捕获子类异常的except块的后面;不能只有try块,既没有except块,也没有finally块;多个except块必须位于try块之后,finally块必须位于所有的except块之后。
try: #业务实现代码 ... except(Error1, Error2, ...) as e: alter 输入不合法 goto retryPython异常处理机制:?
- 如果在执行try块里的业务逻辑代码时出现异常,系统自动生成一个异常对象,该异常对象被提交给Python解释器,这个过程被称为引发异常。
- 当Python解释器收到异常对象时,会寻找能处理该异常对象的except块,如果找到合适的except块,则把异常交给该except块处理,这个过程被称为捕获异常。如果Python解释器找不到捕获异常的except块,则运行时环境终止,Python解释器也将退出。
- 不管程序代码是否处于try块中,甚至包括except块中代码,只要执行该代码块时出现了异常,系统总会自动生成一个Error对象。如果程序没有为这段代码定义任何except块,则Python解释器无法找到处理该异常的except块,程序就在此退出。
try: print(1 / 0) except ZeroDivisionError: print("You are wrong") ========================== You are wrong
1.2,异常类
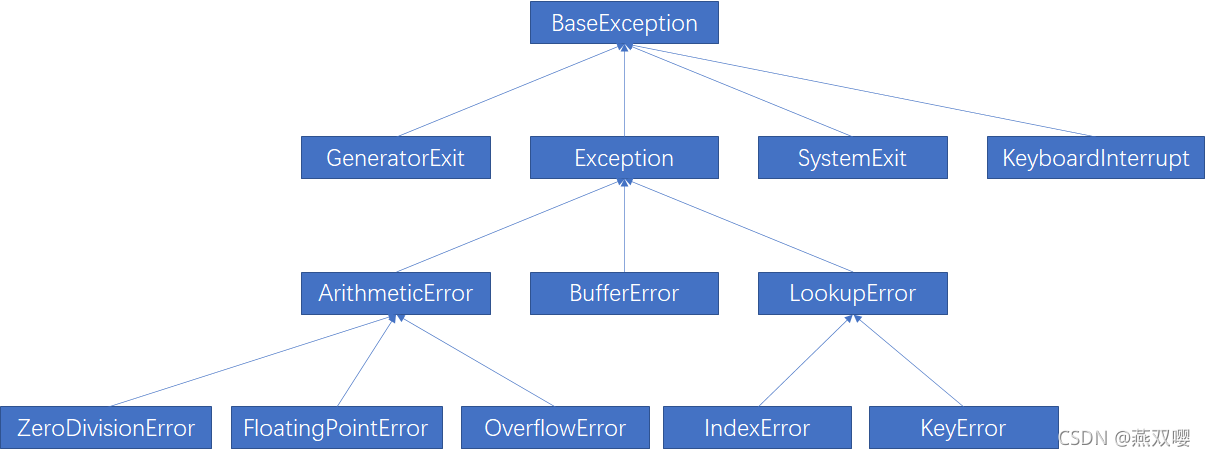
Python的所有异常类都从BaseException派生而来,提供了丰富的异常类,这些异常类之间有严格的继承关系。
类名 描述 类名 描述 BaseException 所有异常类的基类 Exception 常规异常基类 AttributeError 对象不存在此属性 IndexError 序列中无此索引 IOError 输入/输出操作失败 KeyboardInterrupt 用户中断执行 KeyError 映射中不存在此键 NameError 找不到名字变量 SyntaxError Python语法错误 TypeError 对类型无效的操作 ValueError 传入无效的参数 ZeroDivisionError 除0操作
1.3,多异常捕获、访问异常信息
Python的一个except块可以捕获多种类型的异常,在使用一个except块捕获多种类型的异常时,只要将多个异常类用圆括号括起来,中间用逗号隔开即可――其实就是构建了一个多异常类的元组。
try: print(1 / 0) except (ZeroDivisionError, ValueError, IndexError): print("You are wrong") except: print("未知异常")如果程序中的excpet后面没有跟任何异常类型表示可以捕获所有类型的异常。
如果程序需要在except块中访问异常对象的相关信息,则可通过为异常对象声明变量来实现。当Python解释器决定调用某个except块来处理该异常对象时,会将异常对象赋值给except块后的异常变量,程序即可通过该变量来获得异常对象的相关信息。
所有的异常对象都包括了如下常用属性和方法:
- args:该属性返回异常的错误编号和描述字符串。
- errno:该属性返回异常的错误编号。
- strerror:该属性返回异常的描述字符串。
- with_traceback():通过该方法可处理异常的传播轨迹信息。
try: fis = open("a.txt") except Exception as e: #访问异常的错误编号和详细信息 print(e.args) #访问异常的错误编号 print(e.errno) #访问该异常的详细信息 print(e.strerror) =============================== (2, 'No such file or directory') 2 No such file or directory
1.4,else块
在Python的异常处理流程中还可添加一个else块,当try块没有出现异常时,程序会执行else块。
s = input("请输入整数:") try: result = 20 / int(s) print(result) except ValueError: print("值错误!") except ArithmeticError: print("算术错误") else: print("没有异常")既然只有当try块没有异常时才会出现异常时才会执行else块,那么直接把else块的代码放在try块的最后不就行了?
实际上大部分语言处理的异常处理都没有else块,它们确实是将else块代码放在try块的代码的后面的,因为对于大部分场景而言,直接将else块的代码放在try块的代码的后面即可。
但Python异常处理使用else绝不是多余的语法,当try块没有异常,而else块有异常时,就能体现出else的作用了。
def else_test(): s = input("请输入除数:") result = 20 / int(s) print("20除以%s的结果是:%g" % (s, result)) def right_main(): try: print("try块的代码,没有异常") except: print("程序出现异常") def wrong_main(): try: print("try的代码,没有异常") else_test() except: print("程序出现异常") wrong_main() right_main()运行程序不会发生错误,用户输入的都是0,这样会导致else_test()函数出现异常。如果将else_test()函数放在try代码的后面,此时else_test()函数运行产生的异常将会被try对应的except捕获,这正是Python异常处理机制的执行流程;但如果将else_test()函数放在else块中,当else_test()函数出现异常时,程序没有except块来处理该异常,该异常将会传播给Python解释器导致程序中止。
放在else块中的代码所引发的异常不会被except块捕获。所以,如果希望某段代码的异常能被后面的except块捕获,那么就应该将这段代码放在try块的代码之后;如果希望某段代码的异常能向外传播,那么就应该将这段代码放在else块中。
1.5,使用finally回收资源
有些时候,程序在try块里打开一些物理资源(例如数据库连接、网络连接和磁盘文件等),这些物理资源都必须被显式回收。
为了保证一定能回收在try块中打开的物理资源,异常处理机制提供了finally块。不管try块中的代码是否出现异常,也不管哪一个except块被执行,甚至在try块或except块中执行了return语句,finally块总会被执行。
def test(): try: print("123") return finally: print("123") test() ==================== 123 123除非在try块、except块中调用了退出Python解释器的方法,否则不管在try块、except()块中执行怎样的代码,出现怎样的情况,异常处理的finally块总会被执行。调用sys.exit()方法退出程序不能阻止finally块的执行,这是因为sys.exit()方法本身就是通过引发SystemExit异常来退出程序的。
Python程序在执行try块、except块时遇到了return或raise语句,这两条语句都会导致该方法立即结束,那么系统执行这两条语句并不会结束该方法,而是去寻找该异常处理流程中的finally块,如果没有找到finally块,程序立即执行return或raise语句,方法中止;如果找到finally块,系统立即开始执行finally块――只有当finally块执行完成后,系统才会再次跳回来执行try块、except块里的return或raise语句;如果在finally块里也使用了return或raise等导致方法中止的语句,finally块已经中止了方法,系统将不会跳回去执行try块、except块里的任何代码。
2,使用raise引发异常
当程序出现错误时,系统会自动引发异常。除此之外,Python也允许程序使用raise自行引发。
2.1,引发异常
如果需要在程序中自行引发异常,则应该使用raise语句。raise语句有如下三种常用用法:
- raise:单独一个raise。该语句引发当前上下文中捕获异常(比如在except块中),或默认引发RuntimeError异常。
- raise 异常类:raise后带一个异常类。该语句引发指定异常类的默认实例。
- raise 异常对象:引发指定的异常对象。
raise ZeroDivisionError
在except中使用raise:在实际应用中对异常可能需要更复杂的处理方法――当一个异常出现时,单靠某个方法无法完全处理该异常,必须由几个方法协作才可完全处理该异常。也就是说,在异常出现的当前方法中,程序只对异常进行部分处理,还有些处理需要在该方法的调用者中才能完成,所以应该再次引发异常,让该方法的调用者能捕获异常。
def test(): try: print(1 / 0) except ZeroDivisionError: print("你除0了") raise Exception try: test() except: print("程序有错误")这种except和raise结合使用的情况在实际应用中非常常用。实际应用对异常的处理通常分为两个部分:
- 应用后台需要通过日志来记录异常发生的详细情况。
- 应用需要根据异常向应用使用者传达某种提示。在这种情况下,所有异常都需要两个方法共同完成,也就必须将except和raise结合使用。
使用raise语句时可不带参数,此时raise语句处于except块中,它将会自动引发当前上下文激活的异常;否则,通常默认引发RuntimeError异常。
try: print(1/0) except ZeroDivisionError: print("你除0了") raise ========================= 你除0了 Traceback (most recent call last): File "E:/Pycharm/WorkSpace/Study/main.py", line 2, in <module> print(1/0) ZeroDivisionError: division by zero
2.2,自定义异常
自定义异常,大部分情况下都需要继承自Exception类。
class MyException(Exception): def __init__(self, code): self.code = code raise MyException(102)
3,模块和包
3.1,概述
对于一个庞大的Python程序,我们不可能自己完成所有的工作,也不能在一个源文件中编写整个程序的源代码,通常需要借助第三方库。
在Python中,一个.py文件就被称为一个模块(Module)。模块提高了代码的可维护性,同时模块还可以被其他地方引用。一个包括许多Python代码的文件夹就是一个包。一个包可以包含模块和子文件夹。在Python中,模块是搭建程序的一种方式。
模块通常分为:
- 内置函数:例如os、random、time和sys模块。
- 第三方模块:别人写好的模块,可以拿来使用,但是使用第三方模块前,需要使用pip进行安装。
- 自定义模块:程序员自己写的模块。
pip:在Python中,使用pip作为Python的标准包管理器,使用pip命令可以安装和管理不属于Python标准库的其他软件包。软件包管理极其重要,所以,自Python2.7.9版本开始,pip一直被直接包括在Python安装包内,同样被用于Python的其他项目中,这使得pip成为每一个Python用户必备工具。?
3.2,导入模块
在Python中使用import或者from...import...来导入相应的模块:
- 将整个模块导入:import somemodule。
- 从某个模块中导入某个函数:from somemodule import somefunction。
- 从某个模块中导入多个函数:from somemodule import firstfunc, secondfunc, thirdfunc。
- 将某个模块的全部函数导入:from somemodule import *。
- 起别名导入:import random as rr 或 from random import randint as rint。
import sys from sys import argv from sys import argv, stderr, dllhandle from sys import * import sys as s from sys import argv as a
3.3,定义模块
模块就是一个.py结尾的Python程序,任何Python程序都可以作为模块导入。使用模块的好处在于:如果将程序需要使用的程序单元函数、定义在模块中,后面不管哪个程序只要导入该模块,该程序即可使用该模块所包含的程序单元,这样就可以提供很好的复用――导入模块,使用模块,从而避免每个程序都需要重新定义这些程序单元。
-------main.py------- from test import test -------test.py------- def test(): print("你好")
3.4,定义包、导入包
为了更好地管理多个模块源文件,Python提供了包的概念:
- 从物理上看:包就是一个文件夹,在该文件夹下包含了一个__init__.py文件,该文件可用于包含多个模块源文件。
- 从逻辑上看:包的本质依然是模块。
包的作用是包含多个模块,但包的本质依然是模块,因此包也可用于包含包。
定义包的步骤:只需要在当前目录建立一个文件夹,文件夹中包含一个__init__.py文件和若干模块文件,其中__init__.py可以是一个空文件,但还是建议将包中所有需要导出的变量放到__all__中,这样可以确保包的接口清晰明了、易于使用。
??????????????导入包与导入模块方法类似:
import MyPackage import MyPackage.OtherPackageModule from MyPackage import OtherPackageModule

4,常见模块
标准库:操作系统(os)、系统相关的参数和函数(sys)、警告控制(warning)、时间(time)、随机数(random)、数据库连接(pymysql)、线程(threading)以及进程(multiprocessing)等。
三方库:科学计算(Numpy、Scipy和Pandas等)、绘图(Matplotlib、Pillow和Seaborn等)、经典Web框架(Django和Flask)、爬虫框架(Scrapy)、机器学习框架(Keras、Tensorflow和Caffe等)以及requests、urllib、BeautifulSoup和Queue等。
4.1,sys模块
sys模块代表了Python解释器,主要负责与Python解释器的交互,提供了一系列的函数和变量,用于操控Python时运行的环境变量。
sys模块中常用属性和函数:
- sys.argv:获取运行Python程序的命令行参数。其中sys.argv[0]通常就是指该Python程序,sys.argv[1]代表为Python程序提供第一个参数,sys.argv[2]代表为Python程序提供的第二个参数......以此类推。
- sys.byteorder:显示本地字节的指示符。如本地字节序是大端模式,则该属性返回big;否则返回little。
- sys.copyright:该属性返回与Python解释器有关的版权信息。
- sys.executable:该属性返回Python解释器在磁盘上的存储路径。
- sys.exit():通过引发SystemExit异常来退出程序。将其放在try块中不能阻止finally块的执行。
- sys.flags:该只读属性返回运行Python命令时指定的旗标。
- sys.getfilesystemencoding():返回在当前系统中保存文件所用的字符集。
- sys.getrefcount(object):返回指定对象的引用计数。当object对象的引用计数为0时,系统会回收该对象。
- sys.gettrecursionlimit():返回Python解释器当前支持的递归深度。该属性可通过setrecursionlimit()方法重新设置。
- sys.getswitchinterval():返回在当前Python解释器中线程切换的时间间隔。该属性可通过setswitchinterval()函数改变。
- sys.implementation:返回当前Python解释器的实现。
- sys.maxsize:返回Python整数支持的最大值。在32位平台上,该属性值为2**31-1;在64位平台上,该属性值为2**63-1.
- sys.modules:返回模块名和载入模块对应关系的字典。
- sys.path:该属性指定Python查找模块的路径列表。程序可通过修改该属性来动态增加Python加载模块的路径。
- sys.platform:返回Python解释器所在平台的标识符。
- sys.stdin:返回系统的标准输入流――一个类文件对象。
- sys.stdout:返回系统的标准输出流――一个类文件对象。
- sys.stderr:返回系统的错误输出流――一个类文件对象。
- sys.version:返回当前Python解释器的版本信息。
- sys.winver:返回当前Python解释器的主版本号。
4.2,os模块
os模块代表了程序所在的操作系统,主要用于获取程序运行时所在操作系统的相关信息。
os模块中常用属性和函数:
- os.name:返回导入依赖模块的操作系统名称,通常可返回“posix、nt、java等”其中之一。
- os.environ:返回在当前系统上所有环境变量组成的字典。
- os.fsencode(filename):该函数对类路径(path-like)的文件名进行编码。
- os.fsdecode(filename):该函数对类路径(path-like)的文件名进行解码。
- os.PathLike:这是一个类,代表一个类路径(path-like)对象。
- os.getenv(key, default=None):获取指定环境变量的值。
- os.getlogin():返回当前系统的登录用户名。与该函数对应的还有os.gtuid()、os.getgroups()、os.getgid()等函数,用于获取用户ID、用户组、组ID等,这些函数通常只在UNIX系统上有效。
- os.getpid():获取当前进程ID。
- os.getppid():获取当前进程的父进程ID。
- os.putenv(key,value):该函数用于设置环境变量。
- os.cpu_count():返回当前系统的CPU数量。
- os.sep:返回路径分隔符。
- os.pathsep:返回当前系统上多条路径之间的分隔符。
- os.linesep:返回当前系统的换行符。
- os.urandom(size):返回适合作为加密使用的、最多由N个字节组成的bytes对象。该函数通过操作系统特定的随机性来源返回随机字节,不可预测,适合大部分加密场景。
在os模块下还包含大量操作文件和目录的功能函数(IO)也就是文件处理。
此外,在os模块下还包含大量操作文件和目录的功能函数,它们用于启动新进程、中止已有进程等。在os模块下与进程管理相关的函数如下:
- os.abort():生成一个SIGABRT信号给当前进程。在UNIX系统上,默认行为是生成内核转储;在Windows系统上,进程立即返回退出代码-3。
- os.execl(path, arg0, arg1,....):该函数还有一些列功能类似的函数(os.execle()、os.execlp()等),这些函数都是使用参数列表arg0,arg1, ...... 来执行path所代表的执行文件的。
- os.kill(pid, sig):将sig信号发送到pid对应的过程,用于结束该进程。
- os.killpg(pgid,sig):将sig信号发送到pgid对应的进程组。
- os.popen(cmd, mode="r", buffering = -1):用于向cmd命令打开读写管道(当model为r时为只读管道,当mode为rw时为读写管道),buffering缓冲区参数与内置的open()函数有相同的含义。该函数返回的文件对象用于读写字符串,而不是字节。
- os.spawnl(model, path, ...):该函数还有一系列功能类似的函数,比如os.spawnle()、os.spawnlp()等,这些函数都用于在新进程中执行新程序。
- os.startfile(path[[,operation]):对指定文件使用该文件关联的工具执行operation对应的操作。如果不指定operation操作,则默认打开操作。operation参数必须是有效的命令行操作项目,比如open、edit、print等。
- os.system(command):运行操作系统上的指令命令。
4.3,random模块
random模块主要包含生成伪随机数的各种功能变量和函数。os模块中常用函数:
- random.seed(a=None,version=2):指定种子来初始化伪随机数生成器。
- random.randrange(start, stop[,step]):返回从start开始到stop结束、步长为step的随机数。
- random.randint(a, b):生成一个范围为a<=N<=b的随机数。其等同于randrange(a, b+1)的效果。
- random.choice(seq):从seq中随机抽取一个元素,如果seq为空,则引发IndexError异常。
- random.choices(seq, weights=None,*,cum_weights=None, k=1):从seq序列中抽取k个元素,还可通过weights指定各元素被抽取的权重。
- random.shuffle(x[,random]):对x序列执行洗牌“随机排列”操作。
- random.sample(population, k):从population序列执行洗牌“随机排列”操作。
- random.random():生成一个从0.0(包含)到1.0(不包含)之间的伪随机浮点数。
- random.uniform(a, b):生成一个范围为a<=N<=b的随机数。
- random.expovariate(lambd):生成呈指数分布的随机函数。其中lambda参数为1除以期望平均值。如果lambda是正值,则返回的随机数是0到无穷大。如果lambda是负值,则返回的随机数是从负无穷大到0。
4.4,time模块
time模块主要包含各种提供日期、时间功能的类和函数。该模块既提供了把日期转化为字符串的功能,也提供了从字符串恢复日期、时间的功能。
time模块内提供了一个time.struct_time类,该类代表一个时间对象,它主要包含9个属性:
字段名 字段含义 值 tm_year 年 2017、2018 tm_mom 月 2、3,1~12 tm_mday 日 2、3,1~31 tm_hour 时 2、3,0~23 tm_min 分 2、3,0~59 tm_sec 秒 2、3,0~59 tm_wday 周 周一为0,0~6 tm_yday 一年内第几天 如65,1~366 tm_isdst 夏令时 0、1、-1 Python可以用time.struct_time(tm_year=2021, tm_mom=5, tm_tday=2, tm_hour=8, tm_min=0, tm_sec=30, tm_wday=3, tm_yday=1, tm_isdst=0)很清晰的代表时间。此外,Python还可以用一个包含9各元素的元组来代表时间,该元组的9个元素和struct_time对象中9个属性的含义是一一对应的。比如(2021,5,2,8,0,30,3,1,0)。
在日期、时间模块内常用的功能函数:
- time.asctime([t]):将时间元组或struct_time转换为时间字符串。如果不指定参数t,则默认转换当前时间。
- time.ctime([secs]):将以秒数代表的时间转换为时间字符串。
- time.gmtime([secs]):将以秒数代表的时间转换为struct_time对象。如果不传入参数,则使用当前时间。
- time.localtime([secs]):将以秒数代表的时间转换为代表当前时间的struct_time对象。如果不传入参数,则使用当前时间。
- time.mktime(t):它是localtime的反转函数,用于将strutct_time对象或元组代表的时间转换为从1970年1月1日0点整到现在过了多少秒。
- time.perf_counter():返回性能计数器的值。以秒为单位。
- time.process_time():返回当前进程使用CPU的时间。以秒为单位。
- time.sleep(secs):暂停secs秒,什么都不干。
- time.strftime(format[, t]):将时间元组或struct_time对象格式化为指定格式的时间字符串。如果不指定参数t,则默认转换当前时间。
- time.strptime(string,[,format]):将字符串格式的时间解析成struct_time对象。
- time.time():返回从1970年1月1日0点整到现在过了多少秒。
- time.timezone:返回本地时区的时间偏移,以秒为单位。
- time.tzname:返回本地时区的名字。
time模块中的strftime()和strptime()两个函数互为逆函数,其中strftime()用于将struct_time对象或时间元组转换为时间字符串;而strptime()函数用于将时间字符串转换为struct_time对象。这两个函数都涉及编写格式模板。
指令 含义 指令 含义 %a 本地化的星期几缩写,比如Sun代表星期天。 %p 上午或下午本地化方式。 %A 本地化星期几的完整名。 %S 代表分钟的数值,00~61。 %b 本地化的月份的缩写名,比如Jan代表一月。 %U 代表一年中的第几周。 %B 本地化的月份的完整名。 %w 代表星期几的数值,0~6。 %c 本地化的日期和时间的表达式。 %W 代表一年中第几周,以星期一为每周第一天,00~53。 %d 代表一个月中第几天的数值,0~31。 %x 本地化的日期的表示形式。 %H 代表24小时制的小时,00~23。 %X 本地化的时间的表示形式。 %I 代表12小时制的小时,01~12。 %y 年份的缩写,00~99。 %j 一年中第几天,001~366。 %Y 年份的完整形式。 %m 代表月份的数值,01~12。 %z 显示时区偏移。 %M 代表分钟的数值。 %Z 时区名。
5,正则表达式
正则表达式使用单个字符串来描述、匹配一系列满足某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索或替换某些匹配某个模式的文本。例如,匹配电话、邮箱或URL等字符串信息。
5.1,正则表达式语法
正则表达式修饰符:正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位OR(|它们来指定,例如,re.I|re.M被设置成I和M标志:
修饰符 描述 re.I 使匹配对大小写不敏感。 re.L 做本地化识别匹配。 re.M 多行匹配。 re.S 使.匹配包含换行在内的所有字符。 re.U 根据Unicode字符集解析字符。这个标志影响\w、\W、\b、\B。 re.X 该标志通过给予更灵活的格式以便将正则表达式写得更易于理解。
正则表达式模式:模式字符串使用特殊的语法来表示一个正则表达式。
- 字母和数字表示它们自身。一个正则表达式模式中的字母和数字匹配同同样的字符串。
- 多数字母和数字前加一个反斜杠时会拥有不同的含义。
- 标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
- 反斜杠本身需要使用反斜杠转义。
- 由于正则表达式通常都包含反斜杠,所以最好使用原始字符串来表示它们。模式元素匹相应的特殊字符。
模式 描述 ^ 匹配字符串的开头 $ 匹配字符串的末尾。 . 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 [...] 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' [^...] 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 re* 匹配0个或多个的表达式。 re+ 匹配1个或多个的表达式。 re? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 re{ n} 精确匹配 n 个前面表达式。例如,?o{2}?不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的两个 o。 re{ n,} 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。"o{1,}" 等价于 "o+"。"o{0,}" 则等价于 "o*"。 re{ n, m} 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 a|b 匹配a或b (re) 对正则表达式分组并记住匹配的文本 (?imx) 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 (?-imx) 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 (?: re) 类似 (...), 但是不表示一个组 (?imx: re) 在括号中使用i, m, 或 x 可选标志 (?-imx: re) 在括号中不使用i, m, 或 x 可选标志 (?#...) 注释. (?= re) 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 (?! re) 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 (?> re) 匹配的独立模式,省去回溯。 \w 匹配字母数字及下划线 \W 匹配非字母数字及下划线 \s 匹配任意空白字符,等价于?[ \t\n\r\f]。 \S 匹配任意非空字符 \d 匹配任意数字,等价于 [0-9]. \D 匹配任意非数字 \A 匹配字符串开始 \Z 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 \z 匹配字符串结束 \G 匹配最后匹配完成的位置。 \b 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 \B 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 \n, \t, 等. 匹配一个换行符。匹配一个制表符。等 \1...\9 匹配第n个分组的内容。 \10 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 案例
实例 描述 [Pp]ython 匹配 "Python" 或 "python" rub[ye] 匹配 "ruby" 或 "rube" [aeiou] 匹配中括号内的任意一个字母 [0-9] 匹配任何数字。类似于 [0123456789] [a-z] 匹配任何小写字母 [A-Z] 匹配任何大写字母 [a-zA-Z0-9] 匹配任何字母及数字 [^aeiou] 除了aeiou字母以外的所有字符 [^0-9] 匹配除了数字外的字符
5.2,re模块常用函数
re模块使 Python 语言拥有全部的正则表达式功能。re模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。???????
re模块常见的函数有:match、search、findall、finditer、compile、sub、split函数。
re.match函数:re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回None。
函数语法:re.match(pattern, string, flags=0)
函数参数说明:
参数 描述 pattern 匹配的正则表达式 string 要匹配的字符串。 flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方法 描述 group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 import re print(re.match('www', 'www.baidu.com').span()) # 在起始位置匹配 print(re.match('com', 'www.baidu.com')) # 不在起始位置匹配 ======================================= (0, 3) None
re.search:search()方法用于在整个字符串中搜索第一个匹配的值,如果搜索到匹配项,返回match对象,否则返回None???????,语法与match一样。
search与match的区别:re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None,也就是说match()只有在0位置匹配成功的话才有返回;而re.search匹配整个字符串,直到找到一个匹配。
import re print(re.search('www', 'www.baidu.com').span()) # 在起始位置匹配 print(re.search('com', 'com.www.baidu.com').span()) # 不在起始位置匹配 =============================================== (0, 3) (0, 3)
re.findall:findall()方法用于在整个字符串中搜索所有符合正则表达式的字符串,并以列表形式返回。如果匹配成功,则返回包含匹配结构的列表,否则返回空列表。
注意:?match 和 search 是匹配一次 findall 匹配所有。
语法格式:???????findall(string[, pos[, endpos]])???????
- string?: 待匹配的字符串。
- pos?: 可选参数,指定字符串的起始位置,默认为 0。
- endpos?: 可选参数,指定字符串的结束位置,默认为字符串的长度。
import re pattern =r'shao' string1='shao12138_shao12138' string2='ashao12138' match1=re.findall(pattern,string1) match2=re.findall(pattern,string2) print(match1,"\t",match2) ================================= ['shao', 'shao'] ['shao']
re.finditer:和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
it = re.finditer(r"\d+","12a32bc43jf3") for match in it: print (match.group()) ========================================= 12 32 43 3
re.compile:compile函数用于编译正则表达式,生成一个正则表达式(Pattern)对象,供 match() 和 search() 这两个函数使用。
语法格式:???????re.compile(pattern[, flags])???????
pattern?: 一个字符串形式的正则表达式。
flags?: 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I?忽略大小写。
- re.L?表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境。
- re.M?多行模式。
- re.S?即为?.?并且包括换行符在内的任意字符(.?不包括换行符)。
- re.U?表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库。
- re.X?为了增加可读性,忽略空格和?#?后面的注释。
>>>import re >>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字 >>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配 >>> print m None >>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配 >>> print m None >>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配 >>> print m # 返回一个 Match 对象 <_sre.SRE_Match object at 0x10a42aac0> >>> m.group(0) # 可省略 0 '12' >>> m.start(0) # 可省略 0 3 >>> m.end(0) # 可省略 0 5 >>> m.span(0) # 可省略 0 (3, 5)在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …])?方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用?group()?或?group(0);start([group])?方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;end([group])?方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;span([group])?方法返回?(start(group), end(group))。
re.sub:用于实现字符串的替换,相当于先靠匹配,然后替换。
语法格式:re.sub(pattern, repl, string, count=0, flags=0)
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
import re pattern=r'1[34578]\d{9}' string='中奖号码为:84978981 联系电话:13611111111' result=re.sub(pattern,'1xxxxxxxxxx',string) print(result) ================================================ 中奖号码为:84978981 联系电话:1xxxxxxxxxxrepl也可以是一个函数。
import re # 将匹配的数字乘以 2 def double(matched): value = int(matched.group('value')) return str(value * 2) s = 'A23G4HFD567' print(re.sub('(?P<value>\d+)', double, s)) ========================================== A46G8HFD1134
re.split:split()用于实现正则表达式的分割字符串,并以列表形式返回。
语法格式:re.split(pattern, string[, maxsplit=0, flags=0])
参数 描述 pattern 匹配的正则表达式 string 要匹配的字符串。 maxsplit 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。 flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 import re string='@燕双嘤@shao12138' pattern=r'@' list=re.split(pattern,string) print(list) ============================ ['', '燕双嘤', 'shao12138']
5.3,贪婪模式和勉强模式
在默认情况,正则表达式的频度限定是贪婪模式。贪婪模式指的是表达式中的模式会尽可能多地匹配字符。
import re print(re.search(r'@.+\.',"shao12138@nudt.edu.cn")) ================================================== <_sre.SRE_Match object; span=(9, 19), match='@nudt.edu.'>上面正则表达式是:r'@.+\.',该表达式就是匹配@符号和点号之间的全部内容。但由于在@和点号之间用的是“.+”,其中“.”可以代表任意字符,而且此时是贪婪模式,因此“.+”会尽可能多地进行匹配,只要它最后有一个“.”结尾即可,所以匹配结果是“@nudt.edu.”。
只要在频率限定之后添加一个英文问号,贪婪模式就变成了勉强模式,所谓勉强模式,指的是表达式中的模式会尽可能少地匹配字符。
import re print(re.search(r'@.+?\.',"shao12138@nudt.edu.cn")) =================================================== <_sre.SRE_Match object; span=(9, 15), match='@nudt.'>