用python爬取中国保护知识产权网
参考原文:https://blog.csdn.net/hua_you_qiang/article/details/114893483
爬取目标
本次爬取的是国际新闻部分。需要爬取的是文章标题,对应的url、日期和内容。
步骤
导库
import re
import os
import requests
import lxml
from bs4 import BeautifulSoup
import csv
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36 FS"}
找寻爬取规律
我们可以发现改变网址的对应1可以翻页

而获取新闻列表的方式我们选用post获取XML获取对应json。

而这个post方式需要提交数据
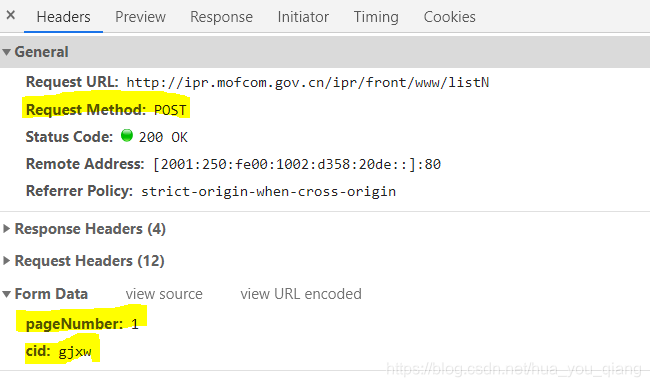
所以我们可以写一个get_json函数来获取对应每页列表的内容内容
data = {'pageNumber':str(i),
'cid':'gjxw'
}
def get_json(data):
url = 'http://ipr.mofcom.gov.cn/ipr/front/www/listN'
r = requests.post(url=url,headers=headers,data=data)
r.status_code = r.apparent_encoding
return r.json()
# return r
# requests模块中,r.json()为Requests中内置的JSON解码器
返回的就是json格式的数据
然后我们研究他的json数据可以发现:

我们要找的数据在pageInfo下的rows,里面每一个键值对记录的就是对应的标题文章的信息:
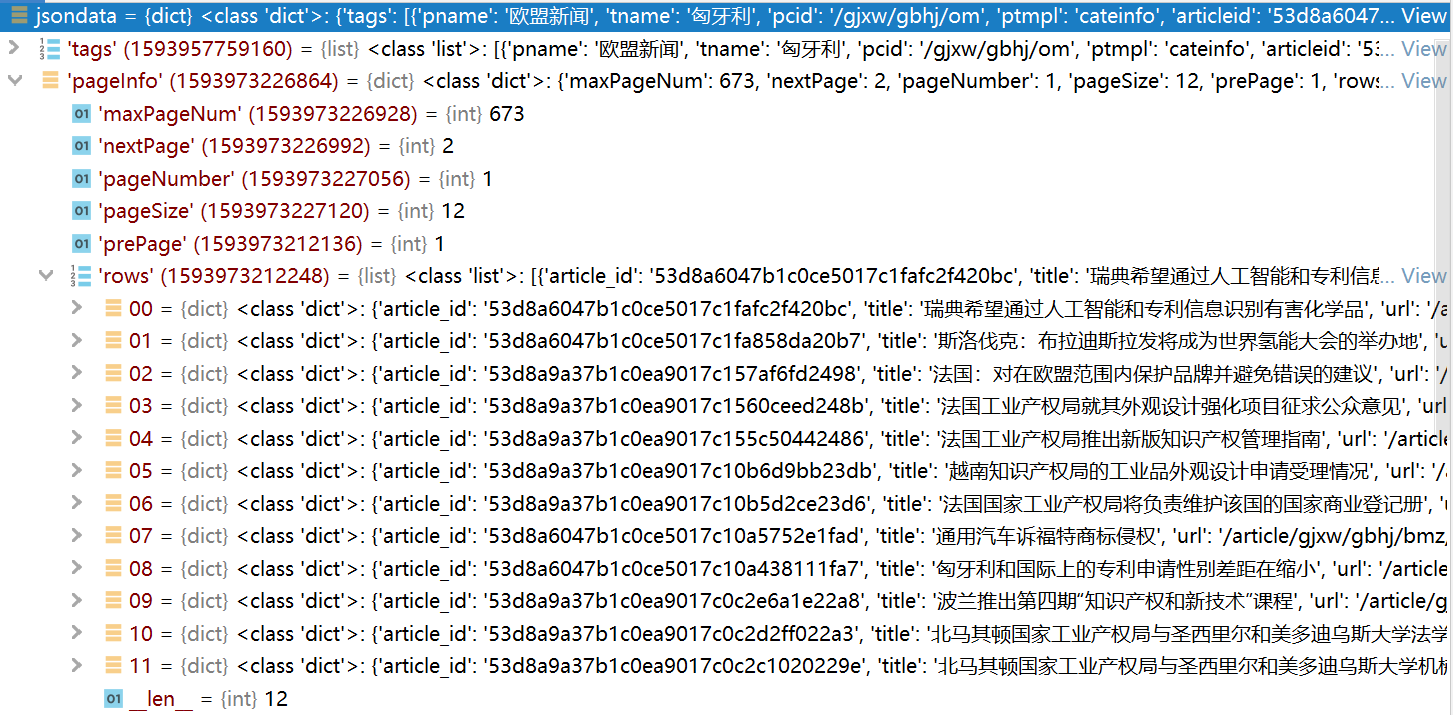
之后我们写一个get_detail_data函数去把对应值中的title,详情内容url和时间保存在list列表中返回
def get_detail_data(jsondata):
# print(jsondata)
list = []
head_url ='http://ipr.mofcom.gov.cn/'
for each in jsondata['pageInfo']['rows']:
list.append((each['title'], head_url+each['url'], str(each['publishTimeStr'])))
# print(list)
return list

这样我们就得到了一个包含对应页数的文章列表的简要信息(标题,时间,内容网址)
通过内容网址找内容
我们获取到了list列表每个网址的内容可以通过for循环去遍历寻找文章内容,然后保存下来。此时我们使用get就可以获取到相应文章内容。
我们写了一个get_html函数去获取对应url的文章内容:
def get_html(url):
try:
r = requests.get(url=url,headers=headers)
r.encoding = r.apparent_encoding
return r.text
except Exception as result:
print('错误原因:',result)
return ''
定位到文章内容,可以发现在section class=“artCon” 包含我们所爬取的内容
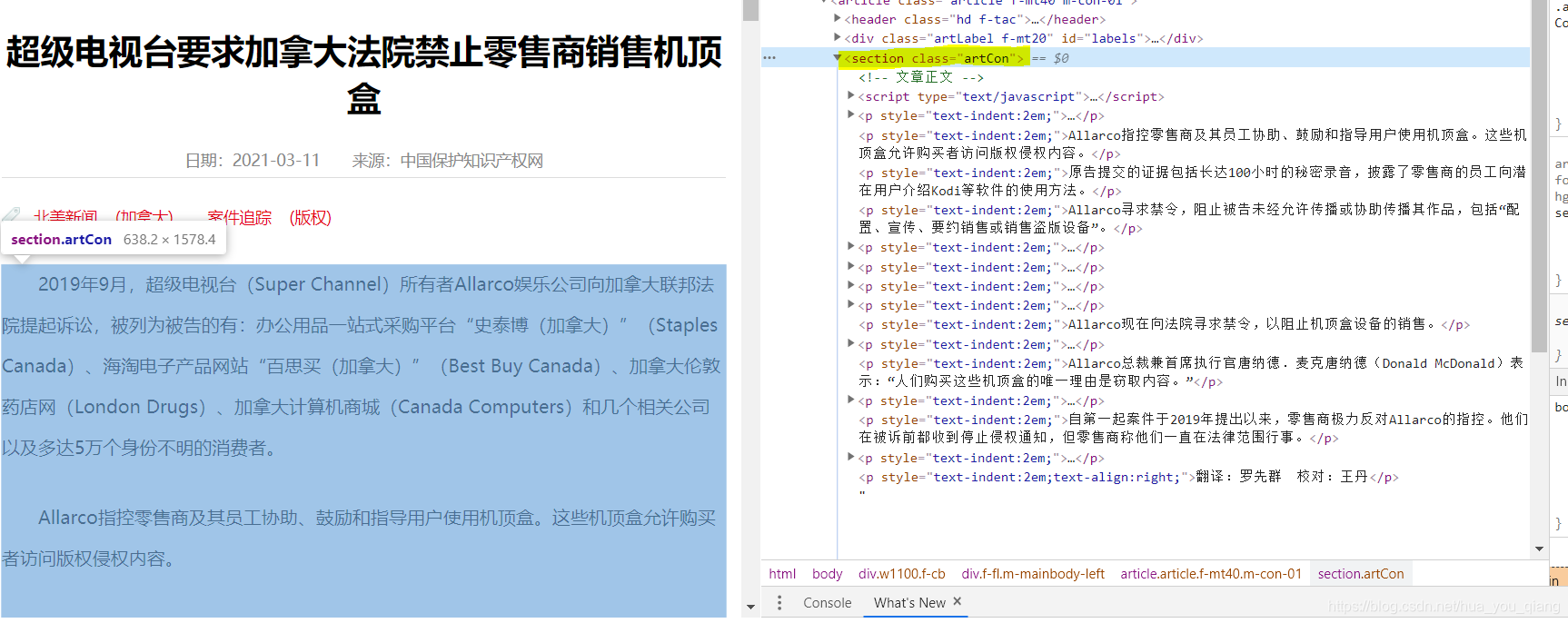
我们写了一个get_article去获取对应的文章内容并写入文章保存:
# text是get_html返回的内容,fp是保存文章的指针
def get_article(text,fp):
# print(text)
soup = BeautifulSoup(text,'lxml')
article = soup.find('section',attrs={'class':'artCon'})
for each in article.find_all('p'):
if each.string:
fp.writelines(each.string)
# print('写入成功')
fp.close()
大致的思路就是如上,然后通过循环遍历去爬取list中每个文章的内容。如果需要爬取多页则多次post提交。
实验完整代码
import re
import os
import requests
import lxml
from bs4 import BeautifulSoup
import csv
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36 FS"}
'''
获取列表信息
'''
# 发送post请求得到相应json信息
def get_json(data):
url = 'http://ipr.mofcom.gov.cn/ipr/front/www/listN'
r = requests.post(url=url,headers=headers,data=data)
r.status_code = r.apparent_encoding
# print(r.json())
return r.json()
# return r
# requests模块中,r.json()为Requests中内置的JSON解码器
# 根据json数据信息得到想要的标题,文章内容地址,时间三个信息
def get_detail_data(jsondata):
# print(jsondata)
list = []
head_url ='http://ipr.mofcom.gov.cn/'
for each in jsondata['pageInfo']['rows']:
list.append((each['title'], head_url+each['url'], str(each['publishTimeStr'])))
print(list)
return list
'''
获取对应文章信息
'''
# 保存csv文件
def save_title_url_time(all_list):
path = '../file/'
header = ['标题', 'url', '日期']
if not os.path.exists(path):
os.makedirs(path)
# print("开始写入")
with open(path+'国际新闻.csv', 'w', newline="") as fp:
f_csv = csv.writer(fp)
f_csv.writerow(header)
f_csv.writerows(all_list)
print("OK")
# 获取文章内容
def get_article(text,fp):
# print(text)
soup = BeautifulSoup(text,'lxml')
article = soup.find('section',attrs={'class':'artCon'})
for each in article.find_all('p'):
if each.string:
fp.writelines(each.string)
# print('写入成功')
fp.close()
# 获取相应文章的html
def get_html(url):
try:
r = requests.get(url=url,headers=headers)
r.encoding = r.apparent_encoding
return r.text
except Exception as result:
print('错误原因:',result)
return ''
# 保存内容文件
def savefile(url,title):
key ='国际新闻'
if not os.path.exists(f'../file/{key}'):
os.mkdir(f'../file/{key}')
try:
everytext = get_html(url)
if not everytext:
print("为空,写入失败")
else:
# 文章标题非法字符替换
title = filename_is_leagal(title)
# 打开文件
fp = open(f'../file/{key}/{title}.txt','w',encoding='utf-8')
# 获取article内容
get_article(everytext,fp)
except Exception as result:
print('错误原因:',result)
# 非法字符替换
def filename_is_leagal(filename):
unstr = ['?','<','>','"',':','|','/','\\','*']
for i in unstr:
if i in filename:
filename = filename.replace(i,',')
return filename
'''
main
'''
# 创建一个空列表
listdetail = []
# 爬取1到3页的列表内容
for i in range(1,4):
data = {'pageNumber':str(i),
'cid':'gjxw'
}
jsondata = get_json(data)
# 将获取的get_detail_data添加到list列表中
listdetail += get_detail_data(jsondata)
# 此时的列表获取了1到3页的所有有关(标题,文章内容地址,时间)内容
# 保存一个csv文件里面包含列表内的标题,文章内容地址,时间
save_title_url_time(listdetail)
# 每一个list里的数据都要保存相应的文章内容详情地址的文件
for each in listdetail:
# each[1]是each里对应的内容地址,each[0]是标题,如有疑问,自行打印查看
savefile(each[1],each[0])