�˳������Էdz����ȶ�,������״̬�»���ʾ,���������Ϳ�����ȡ,ÿ�����50ҳ,�ɸ�����Ҫѡ��������Ǵ�������߳�,�������ۻ�����,����ֻ�����Լ��ܿ���,ˮƽ����,�����ˡ����������������ϰ���ۺϵ�ʵսӦ��,����ҳ��Լ���Ѻ�,��������Ҳ�������쳣����,��Ȼһ�����в������Ƶĵط�,Ҳ���λͬ������ָ����
��������:
?
?��������(��������IP��API):
from tkinter import *
import requests
from lxml import html
import random
import xlwt
import time
from requests.adapters import HTTPAdapter
from retry import *
from tkinter.filedialog import askdirectory
import threading
import tkinter.messagebox # ������
root = Tk()
global list_title
import os
'''
�ļ�·��ѡ��
'''
xVariable = tkinter.IntVar()
def selectPath():
path_ = askdirectory(title="·��ѡ��")
if path_ == "":
path.get()
else:
path_ = path_.replace("/", "\\") # ʵ���ڴ�����ִ�е�·��Ϊ��\�� �����滻һ��
path.set(path_)
def openPath():
dir = os.path.dirname(path.get() + "\\")
os.system('start ' + dir) # start+�ո� �൱��windows��CMD������ļ���
path = StringVar()
path.set(os.path.abspath("."))
text = Listbox(root, font=('���ź�', 15), width=52, height=13)
text.grid_configure(row=1, columnspan=6)
sc = Scrollbar(root, command=text.yview)
sc.grid_configure(row=1, column=7, sticky=S + E + N)
sc1 = Scrollbar(root, orient="horizontal", command=text.xview,)
sc1.grid_configure(row=2, columnspan=6, sticky=EW)
text.config(yscrollcommand=sc.set)
text.config(xscrollcommand=sc1.set)
def download():
try:
response = requests.get("http://www.xiongmaodaili.cn/").status_code
if response == 200:
lujing["state"] = DISABLED
spbox["state"] = DISABLED
button["text"] = "������ȡ"
button["state"] = DISABLED
savapath = path.get()
page = xVariable.get()
def get_ip():
try:
url1 = '����IP�ĵ�ַ,����ɾ����...'
response = requests.get(url1)
if response.status_code == 200:
while response.text[0] == '{' or response.text[0] == "":
time.sleep(2)
response = requests.get(url1)
return [x for x in response.text.split('\r')]
# print('��ȡipʧ��')
# �˴����ص������Ƕ��е��ַ���,ʹ���б�����ʽʹ���ֳ���ϳ��б�
else:
text.insert(END, '����ʧ��')
except Exception as e:
text.insert(END, e)
i = 0
@retry(tries=4, delay=1, backoff=1, jitter=0, max_delay=1)
def my_request(url):
requests.adapters.DEFAULT_RETRIES = 15
s = requests.session()
s.keep_alive = False # �ر�֮ǰ������,�������ӹ���
global r
try:
ips = get_ip()
proxy = {'https': ips[0]}
text.insert(END, proxy)
r = requests.get(url, headers=head, proxies=proxy, verify=False, timeout=5)
r.encoding = 'utf-8'
except BaseException: # �����쳣��ʱ��,������Ե�д��BaseException,������Ҫ��д�ĸ����塣
text.insert(url, "����ʧ��,��ʼ����")
ips = get_ip()
proxy = {'https': ips[0]}
text.insert(proxy)
r = requests.get(url, headers=head, proxies=proxy, verify=False, timeout=5)
r.encoding = 'utf-8'
return r
global r
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36",
"accept": "application/json, text/plain, */*", "accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9"}
work_book = xlwt.Workbook(encoding="utf-8")
sheet = work_book.add_sheet("���ݶ��ַ���Ϣ")
sheet.write(0, 3, "������")
sheet.write(0, 4, "����1")
sheet.write(0, 5, "����2")
sheet.write(0, 6, "��ַ")
sheet.write(0, 7, "�ܼ�(��Ԫ)")
sheet.write(0, 8, "����(Ԫ/�O)")
sheet.write(0, 2, "���Ӵ�С(�O)")
sheet.write(0, 1, "����")
sheet.write(0, 0, "����")
row_num = 1
z = 0
v = 0
# page = xVariable.get()
for i in range(0, page):
v += 1
i += 1
try:
url = "https://bygl.58.com/ershoufang/p" + str(i) + "/"
text.insert(END, url)
text.see(END)
text.update()
my_request(url)
except Exception as e:
text.insert(END, e)
text.insert(END, "��" + str(i) + "ҳ����!")
text.insert(END, "--------------------------")
continue
else:
preview_html = html.fromstring(r.text)
list_title = preview_html.xpath("//div[@class='property-content-title']/h3/text()|//p["
"@class='property-content-info-comm-name']/text()|//p[ "
"@class='property-content-info-comm-address']//span/text()|//span[ "
"@class='property-price-total-num']/text()|//p["
"@class='property-price-average']/text()|//p["
"@class='property-content-info-text'][1]/text()|//p["
"@class='property-content-info-text property-content-info-attribute']//span//text()")
list_title = [str(x) for x in list_title]
while not list_title:
text.insert(END, "�б�Ϊ��,���»�ȡ����IP:")
my_request(url)
list_title = preview_html.xpath("//div[@class='property-content-title']/h3/text()|//p["
"@class='property-content-info-comm-name']/text()|//p[ "
"@class='property-content-info-comm-address']//span/text()|//span[ "
"@class='property-price-total-num']/text()|//p["
"@class='property-price-average']/text()|//p["
"@class='property-content-info-text'][1]/text()|//p["
"@class='property-content-info-text property-content-info-attribute']//span//text()")
list_title = [str(x) for x in list_title]
time.sleep(random.random() * 2)
break
text.insert(END, "�ɹ���ȡ��" + str(i) + "ҳ����")
z += 1
text.insert(END, "ץȡ�ɹ���:{:.2%}".format(z / v))
text.insert(END, "----------------------------")
text.see(END)
text.update()
for j in range(len(list_title)):
if j % 14 == 0:
title = list_title[j + 8]
area1 = list_title[j + 9]
biaoti = list_title[j]
area2 = list_title[j + 10]
area3 = list_title[j + 11]
totalnum = list_title[j + 12]
avg = list_title[j + 13]
size = list_title[j + 7].strip().strip('\n')
house_type = list_title[j + 1] + list_title[j + 2] + list_title[j + 3] + list_title[j + 4] + \
list_title[
j + 5] + list_title[j + 6]
# print(type(list_title[j + 6]))
sheet.write(row_num, 3, title)
sheet.write(row_num, 4, area1)
sheet.write(row_num, 5, area2)
sheet.write(row_num, 6, area3)
sheet.write(row_num, 7, totalnum)
sheet.write(row_num, 8, avg)
sheet.write(row_num, 2, size)
sheet.write(row_num, 1, house_type)
sheet.write(row_num, 0, biaoti)
row_num += 1
time.sleep(3)
# file_name = r"F:\���ݶ��ַ���ȡ.xls"
file_name = savapath + "\\" + time.strftime("%Y-%m-%d") + "��" + str(page) + "ҳ����.xls"
print(file_name)
if os.path.exists(file_name):
k = 1
name, suffix = file_name.split(".") # ���ݴ���,�Ե�Ž���ǰ��ָ�
name = name + "(" + str(k) + ")"
file_name = name + "." + suffix
if os.path.exists(file_name):
print(file_name)
while os.path.exists(file_name):
name2 = name.split("(")
name1 = name2[1].split(")")
k = int(name1[0]) + k
file_name = name2[0] + "(" + str(k) + ")" + "." + suffix
# print(name1)
# print(name)
# print(k)
print(file_name)
work_book.save(file_name)
else:
work_book.save(file_name)
else:
work_book.save(file_name)
lujing["state"] = ACTIVE
text.insert(END, "�ļ����ɳɹ�:" + file_name)
text.insert(END, "\n")
tkinter.messagebox.showinfo("��ʾ", "�ļ����ɳɹ�:" + file_name)
button["text"] = "��ʼ����"
button["state"] = ACTIVE
spbox["state"] = "readonly"
except:
text.insert(END,"�����쳣,���������")
text.see(END)
def spiderok():
page = xVariable.get()
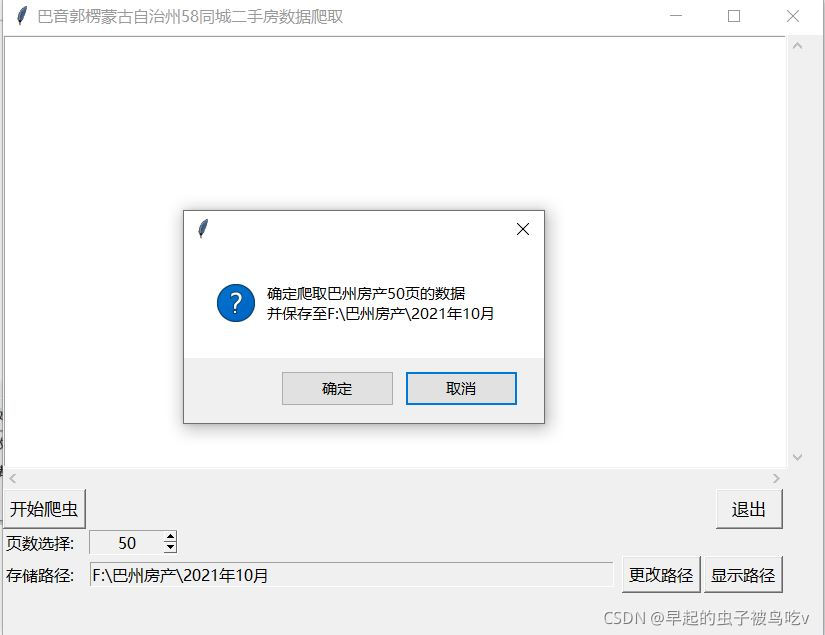
if tkinter.messagebox.askokcancel("", "ȷ����ȡ���ݷ���" + str(page) + "ҳ������\n��������" + path.get(), default="cancel"):
download()
def thread_it(func):
t = threading.Thread(target=func)
t.setDaemon(True)
t.start()
root.title("���������ɹ�������58ͬ�Ƕ��ַ�������ȡ")
root.geometry("820x600+600+230")
def tuichu():
if tkinter.messagebox.askokcancel(title="��ʾ", message="��ȷ��Ҫ�˳���?", default="cancel"):
root.quit()
root.protocol("WM_DELETE_WINDOW", tuichu)
button = Button(root, text="��ʼ����", font=("���ź�", 10), command=lambda: thread_it(spiderok))
button.grid(row=3, sticky=W)
lb = Label(root, text="ҳ��ѡ��:")
lb.grid(row=4, column=0, sticky=W)
spbox = Spinbox(root, from_=1, to=50, increment=1, justify="center", textvariable=xVariable, state="readonly", width=8)
spbox.grid(row=4, column=1, sticky=W)
button1 = Button(root, text="�˳�", padx=10, font=("���ź�", 10), command=tuichu)
button1.grid(row=3, column=4, sticky=E)
Label(root, text="�洢·��:").grid(row=5, column=0, sticky=W)
Entry(root, textvariable=path, state="readonly").grid(row=5, column=1, ipadx=170)
lujing = Button(root, text="����·��", command=selectPath)
lujing.grid(row=5, column=3, sticky=E)
Button(root, text="��ʾ·��", command=openPath).grid(row=5, column=4, sticky=E)
root.update()
root.mainloop()