对课本原有代码加入循环,从1到10改变Knn的k值,进一步测试当k取哪个值时代码效果最好
结果如下:
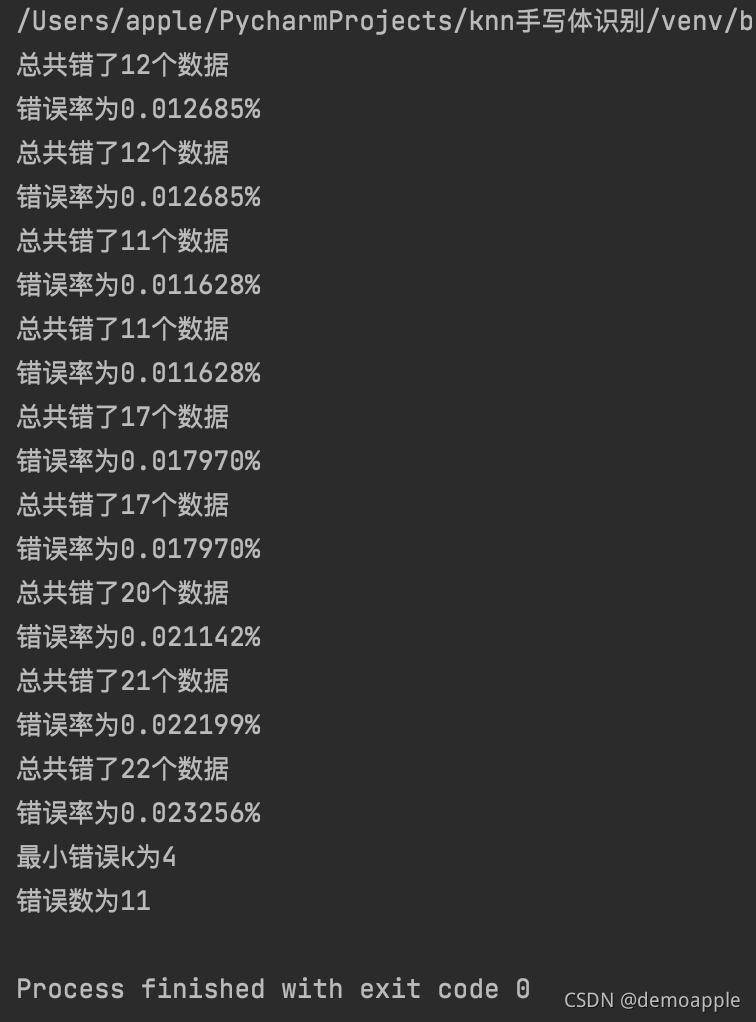
结果显示,当K取3或4时代码效果最好,猜测原因为K取1,2时参考的样本偏少,故结果不如3,4的要好,而取太多时失去近邻性,其他样本反而干扰正确率
3和4时测试结果一样,考虑时间效率取3最优
这与百度的结果相符合
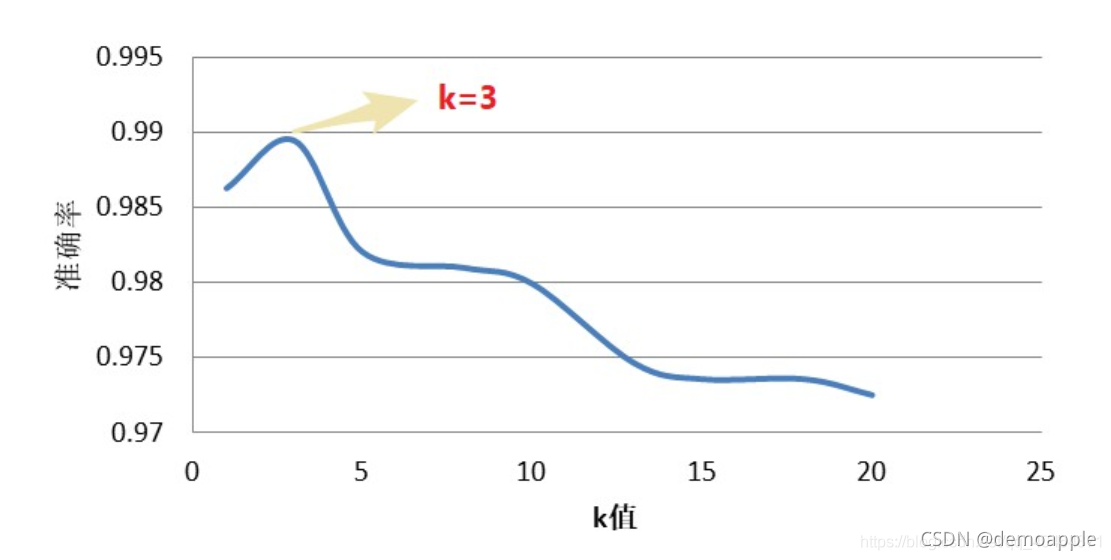
?
?
加入循环后的代码:
# -*- coding: UTF-8 -*-
import numpy as np
import operator
from os import listdir
"""
函数说明:kNN算法,分类器
Parameters:
?? ?inX - 用于分类的数据(测试集)
?? ?dataSet - 用于训练的数据(训练集)
?? ?labes - 分类标签
?? ?k - kNN算法参数,选择距离最小的k个点
Returns:
?? ?sortedClassCount[0][0] - 分类结果
Modify:
?? ?2017-03-25
"""
def classify0(inX, dataSet, labels, k):
? ? # numpy函数shape[0]返回dataSet的行数
? ? dataSetSize = dataSet.shape[0]
? ? # 在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
? ? diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
? ? # 二维特征相减后平方
? ? sqDiffMat = diffMat ** 2
? ? # sum()所有元素相加,sum(0)列相加,sum(1)行相加
? ? sqDistances = sqDiffMat.sum(axis=1)
? ? # 开方,计算出距离
? ? distances = sqDistances ** 0.5
? ? # 返回distances中元素从小到大排序后的索引值
? ? sortedDistIndices = distances.argsort()
? ? # 定一个记录类别次数的字典
? ? classCount = {}
? ? for i in range(k):
? ? ? ? # 取出前k个元素的类别
? ? ? ? voteIlabel = labels[sortedDistIndices[i]]
? ? ? ? # dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
? ? ? ? # 计算类别次数
? ? ? ? classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
? ? # python3中用items()替换python2中的iteritems()
? ? # key=operator.itemgetter(1)根据字典的值进行排序
? ? # key=operator.itemgetter(0)根据字典的键进行排序
? ? # reverse降序排序字典
? ? sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
? ? # 返回次数最多的类别,即所要分类的类别
? ? return sortedClassCount[0][0]
"""
函数说明:将32x32的二进制图像转换为1x1024向量。
Parameters:
?? ?filename - 文件名
Returns:
?? ?returnVect - 返回的二进制图像的1x1024向量
Modify:
?? ?2017-03-25
"""
def img2vector(filename):
? ? # 创建1x1024零向量
? ? returnVect = np.zeros((1, 1024))
? ? # 打开文件
? ? fr = open(filename)
? ? # 按行读取
? ? for i in range(32):
? ? ? ? # 读一行数据
? ? ? ? lineStr = fr.readline()
? ? ? ? # 每一行的前32个元素依次添加到returnVect中
? ? ? ? for j in range(32):
? ? ? ? ? ? returnVect[0, 32 * i + j] = int(lineStr[j])
? ? # 返回转换后的1x1024向量
? ? return returnVect
"""
函数说明:手写数字分类测试
Parameters:
?? ?无
Returns:
?? ?无
Modify:
?? ?2017-03-25
"""
def handwritingClassTest(kx):
? ? # 测试集的Labels
? ? hwLabels = []
? ? # 返回trainingDigits目录下的文件名
? ? trainingFileList = listdir('trainingDigits')
? ? # 返回文件夹下文件的个数
? ? m = len(trainingFileList)
? ? # 初始化训练的Mat矩阵,测试集
? ? trainingMat = np.zeros((m, 1024))
? ? # 从文件名中解析出训练集的类别
? ? for i in range(m):
? ? ? ? # 获得文件的名字
? ? ? ? fileNameStr = trainingFileList[i]
? ? ? ? # 获得分类的数字
? ? ? ? classNumber = int(fileNameStr.split('_')[0])
? ? ? ? # 将获得的类别添加到hwLabels中
? ? ? ? hwLabels.append(classNumber)
? ? ? ? # 将每一个文件的1x1024数据存储到trainingMat矩阵中
? ? ? ? trainingMat[i, :] = img2vector('trainingDigits/%s' % (fileNameStr))
? ? # 返回testDigits目录下的文件名
? ? testFileList = listdir('testDigits')
? ? # 错误检测计数
? ? errorCount = 0.0
? ? # 测试数据的数量
? ? mTest = len(testFileList)
? ? # 从文件中解析出测试集的类别并进行分类测试
? ? for i in range(mTest):
? ? ? ? # 获得文件的名字
? ? ? ? fileNameStr = testFileList[i]
? ? ? ? # 获得分类的数字
? ? ? ? classNumber = int(fileNameStr.split('_')[0])
? ? ? ? # 获得测试集的1x1024向量,用于训练
? ? ? ? vectorUnderTest = img2vector('testDigits/%s' % (fileNameStr))
? ? ? ? # 获得预测结果
? ? ? ? classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, kx)
? ? ? ? # print("分类返回结果为%d\t真实结果为%d" % (classifierResult, classNumber))
? ? ? ? if (classifierResult != classNumber):
? ? ? ? ? ? errorCount += 1.0
? ? print("总共错了%d个数据\n错误率为%f%%" % (errorCount, errorCount / mTest))
? ? return errorCount
"""
函数说明:main函数
Parameters:
?? ?无
Returns:
?? ?无
Modify:
?? ?2017-03-25
"""
if __name__ == '__main__':
? ? kmini = 10000
? ? kmx = 0
? ? for kx in range(1, 10):
? ? ? ? knew = handwritingClassTest(kx)
? ? ? ? if kmini >= knew:
? ? ? ? ? ? kmini = knew
? ? ? ? ? ? kmx = kx
print("最小错误k为%d\n错误数为%d" % (kmx, kmini))
?
?