
📢📢📢📣📣📣
🌻🌻🌻Hello,��Һ��ҽ���Dreamѽ,һ����Ȥ��Python����,С��һö,������😜😜😜
🏅🏅🏅CSDN Python�������Ǵ�����,����ڶ�,��ӭ������Һ���ѧϰ
💕������֪:��Ƭ���Ӳ�ȱ�����,Ŭ��������������볡ȯ!🚀🚀🚀
💓���,Ը���Ƕ����ڿ������ĵط���������,һ����ͽ���🍺🍺🍺
🍉🍉🍉��һ��α���,��Ȼ����Dream,��һֱ������ů�ĵط����㡱,���ľ�����!������~🌈🌈🌈
🌟🌟🌟???
�����ǽ�һ���˽�һ������,Ϊurllib��������β��~
����post���� cookie��¼ handler������
һ��post����ϵ»�����
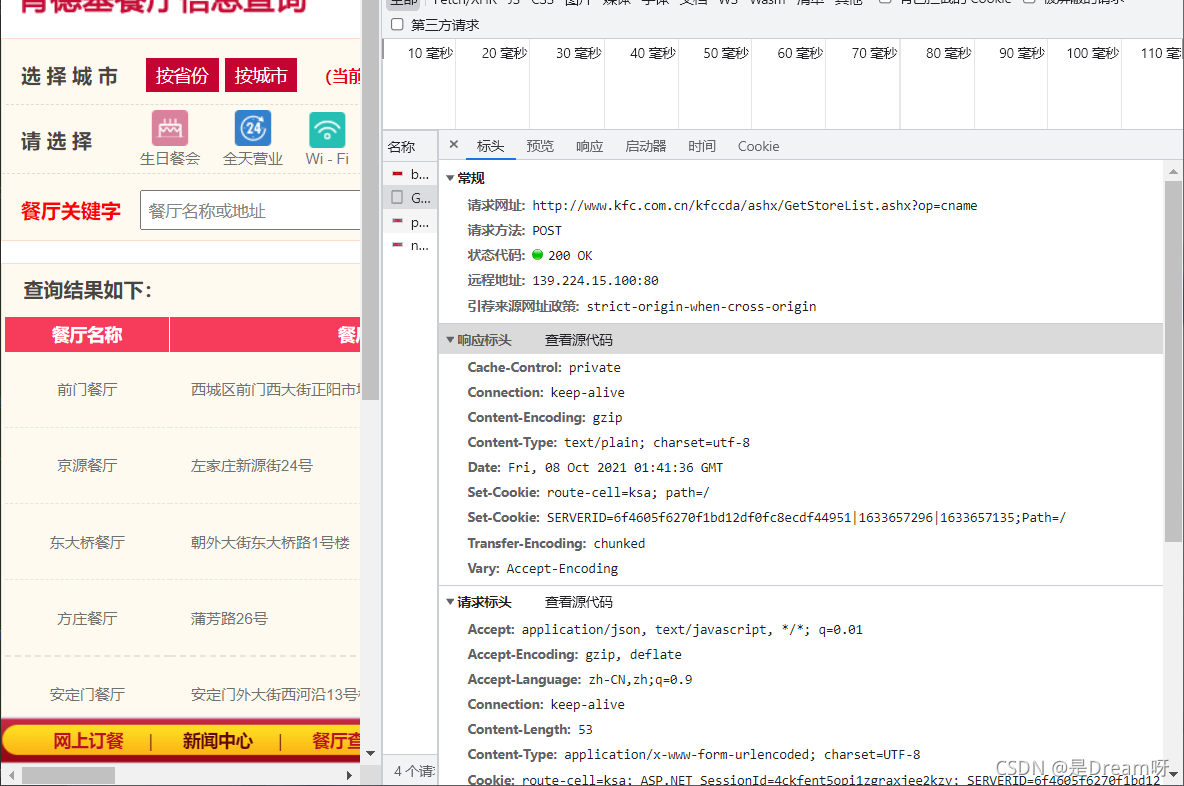
�� �ϵ»����� ���ҵ�������ѯ,�ҳ�ָ��λ�����е��ŵꡣ
1.����ҳ��
��һҳ:
������ַ: http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname��
����: POST
Data:
cname: ����
pid:
pageIndex: 1
pageSize: 10
�ڶ�ҳ:
> ������ַ: http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname��
> ����: POST
> `Data:`
> cname: ����
pid:
pageIndex: 2
pageSize: 10
���Է���,ҳ��֮��ֻ��data��ͬ,����˵����ֻ��Ҫ����data�Ϳ����ˡ�
2.�����д
1.�������
if __name__=='__main__':
start_page = int(input(''))
end_page = int(input(''))
for page in range(start_page,end_page+1):
# �������Ķ���
request=creat_request(page)
# ��ȡҳ��Դ��
content=get_content(request)
# ����
down_load(page,content)
2.���������
post����Ҫ����data���ݵĽ���:encode('utf-8')
def creat_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data={
'cname': '����',
'pid':'',
'pageIndex':page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
request=urllib.request.Request(url=base_url,headers=headers,data=data)
return request
return һ����Ҫ����д,ÿ��������Ҫ��������һ�����ݡ�
3.��ȡҳ��Դ��
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
4.����ҳ������
def down_load(page,content):
with open('kfc_'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
5.Դ��
# -*-coding:utf-8 -*-
# @Author:������,��������
# ��������!!!
# post����
# ��һҳ:
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: ����
# pid:
# pageIndex: 1
# pageSize: 10
# �ڶ�ҳ
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: ����
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request
import urllib.parse
# base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
def creat_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data={
'cname': '����',
'pid':'',
'pageIndex':page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
request=urllib.request.Request(url=base_url,headers=headers,data=data)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('kfc_'+str(page)+'.json','w',encoding='utf-8') as fp:
fp.write(content)
if __name__=='__main__':
start_page = int(input(''))
end_page = int(input(''))
for page in range(start_page,end_page+1):
# �������Ķ���
request=creat_request(page)
# ��ȡҳ��Դ��
content=get_content(request)
# ����
down_load(page,content)
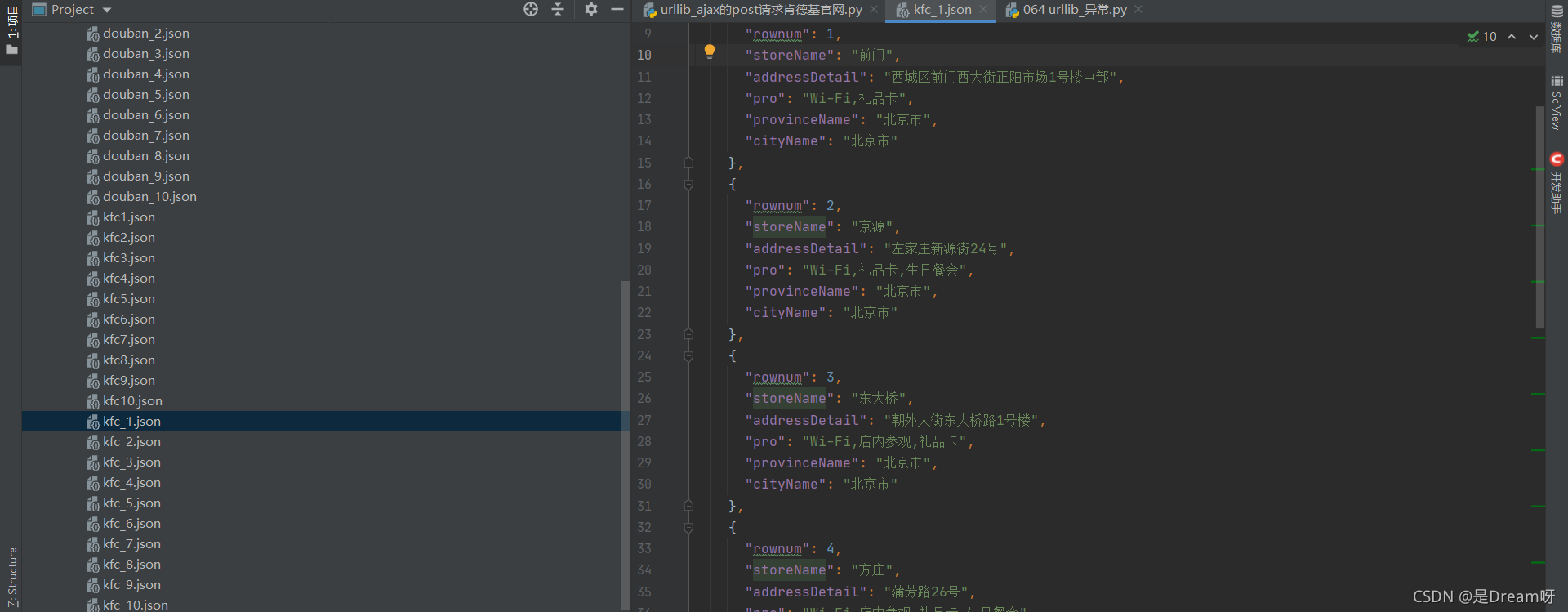
6.��ȡ���
��ȡ1-10ҳ:
�� ��URLError\HTTPError�쳣����
HTTPError����URLError�������
# -*-coding:utf-8 -*-
# @Author:������,��������
# ��������!!!
import urllib.request
import urllib.error
url = 'https://blog.csdn.net/m0_37816922/article/details/120'
# url = 'http://xuxuxu.com'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
try:
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# print(content)
# except urllib.error.HTTPError:
# print('ϵͳ��������������')
except urllib.error.URLError:
print('�Ҷ�˵��,ϵͳ��������������')
ͨ��urllib���������ʱ��,�п��ܻᷢ��ʧ��,���ʱ�����������Ĵ�����ӵĽ�׳,����ͨ��try�\ except���в����쳣,�쳣������,URLError\HTTPError
����cookie���QQ�ռ��¼
1.������ȡ
����ҳ��: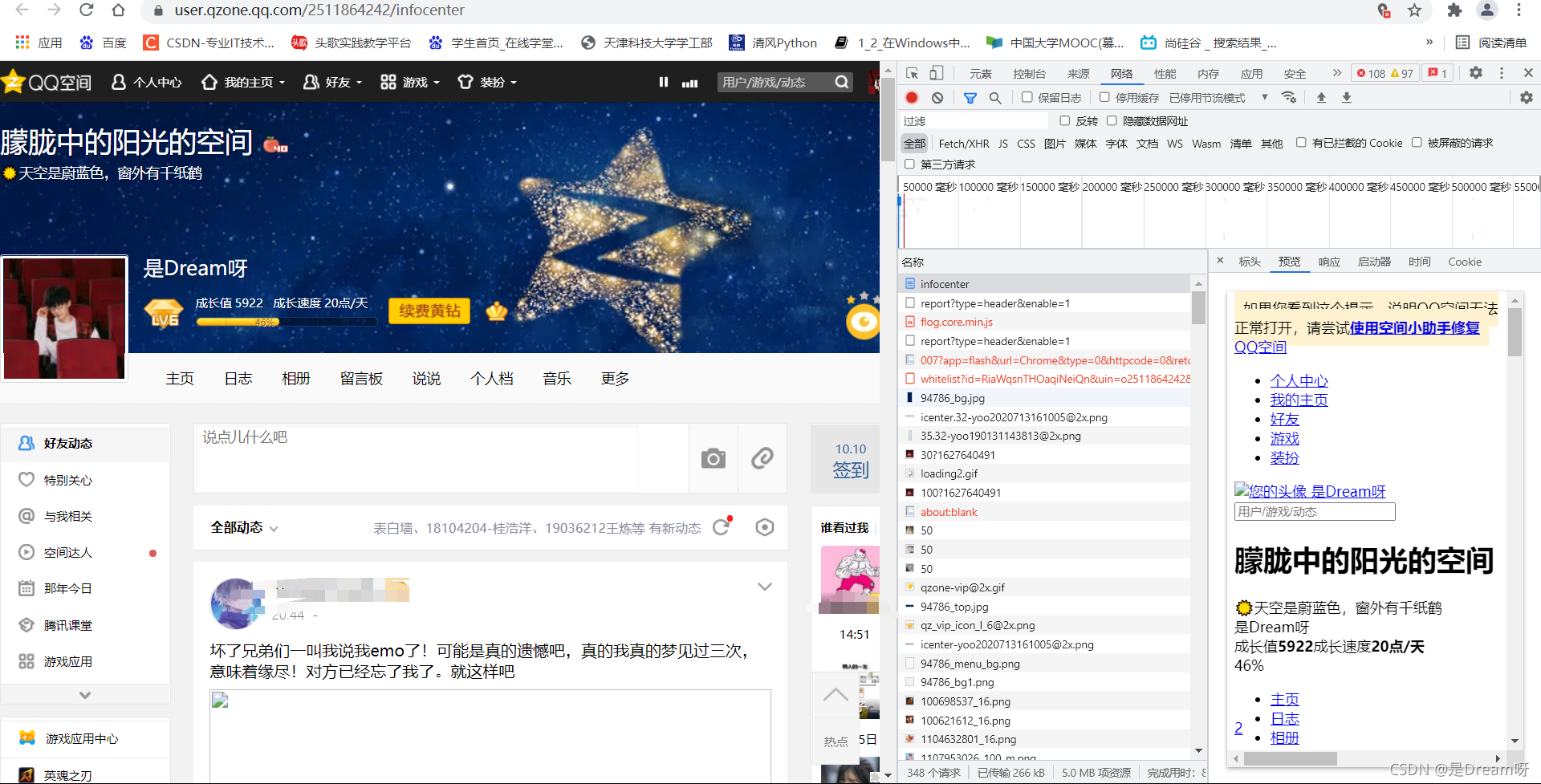
�ҵ���ͷ,��ȡ���е�headers,��ȡҳ������:
# -*-coding:utf-8 -*-
# @Author:������,��������
# ��������!!!
import urllib.request
url = 'https://user.qzone.qq.com/2511864242/infocenter'
headers={
# ':authority':' user.qzone.qq.com',
# ':method':' GET',
# ':path':' /2511864242/infocenter',
# ':scheme':' https',
# 'accept':' text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding':' gzip, deflate, br',
# 'accept-language':' zh-CN,zh;q=0.9',
# 'cache-control':' max-age=0',
# 'cookie':' 2511864242_totalcount=13496; 2511864242_todaycount=2; RK=ECihmXLCuq; ptcz=641b0fe4634b74d761ce9c469c93f3766a6ad2639d4490f37aeb876008c0eba7; tvfe_boss_uuid=1261d53129453d07; o_cookie=2511864242; eas_sid=X0nkgoLJGuyN43gKCxXdODxpVi; QZ_FE_WEBP_SUPPORT=1; cpu_performance_v8=0; nutty_uuid=b2d3e37a-bdbd-488e-9f21-3b53e541dfee; __Q_w_s_hat_seed=1; _ga=GA1.2.118587915.1626953898; fqm_pvqid=39ed0947-c27f-433b-b69a-f45b9890024c; luin=o2511864242; lskey=00010000de072c8e6e48fa1574db17cc9090c4a164266c5036e26a0c559f714d2b597dfb256d9a9440358b1d; pgv_pvid=6039633865; ptui_loginuin=tustaixueshenghui@163.com; _gid=GA1.2.1366085169.1633784022; uin=o2511864242; _qpsvr_localtk=0.7957179321058889; skey=@Ysdnvfow4; p_uin=o2511864242; pt4_token=IPJ09cE1ONrApR1DDtSPKXtObrnyYWHykLFRh5JRyKc_; p_skey=aKyCTikz4zFyYTIAZ4OAdlzt77pg0t8h3EImRUrZGDI_; Loading=Yes; pgv_info=ssid=s4493287755; qz_screen=1536x864; qzmusicplayer=qzone_player_2511864242_1633869885141; qqmusic_uin=; qqmusic_key=; qqmusic_fromtag=',
# 'if-modified-since: Sun, 10 Oct 2021 12:44':'32 GMT',
# 'sec-ch-ua':' "Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"',
# 'sec-ch-ua-mobile':' ?0',
# 'sec-ch-ua-platform':' "Windows"',
# 'sec-fetch-dest':' document',
# 'sec-fetch-mode':' navigate',
# 'sec-fetch-site':' none',
# 'sec-fetch-user':' ?1',
# 'upgrade-insecure-requests':' 1',
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
# �������Ķ���
request = urllib.request.Request(url=url,headers = headers)
# ģ����������������������
response = urllib.request.urlopen(request)
# ��ȡ��Ӧ������
# content = response.read().decode('utf-8')
content = response.read().decode('utf-8')
# �����ݱ��浽����
with open('qq1.html','w',encoding='utf-8') as fp:
fp.write(content)
�õ����:
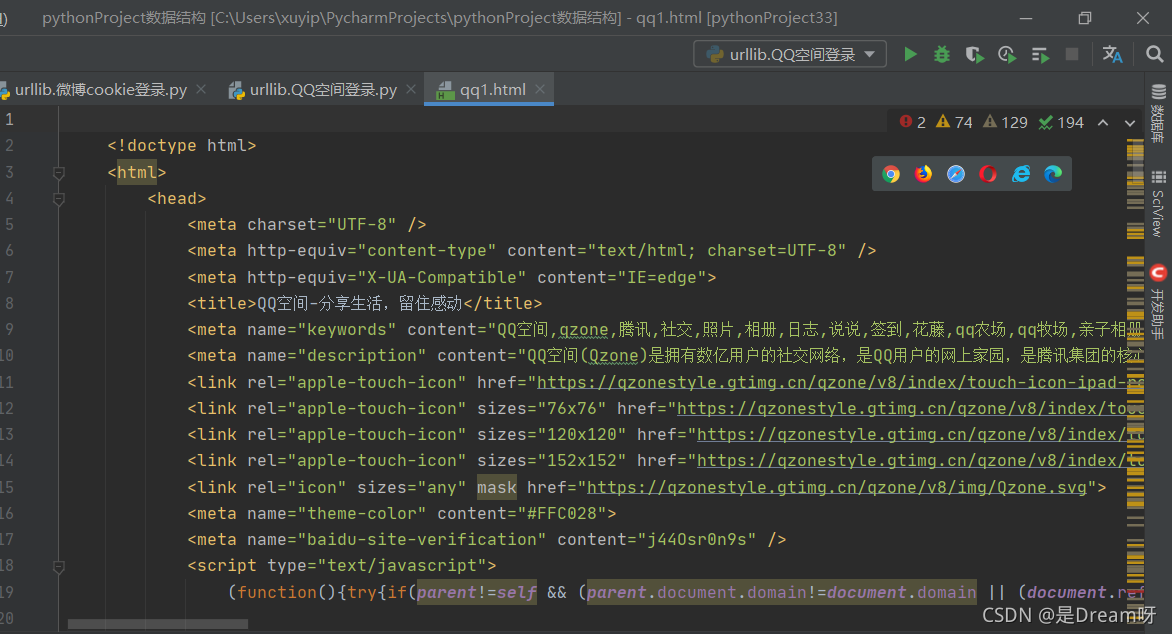
����֮��ᷢ��,ֻ�ǽ����˵�¼����,��û�е�½��ȥ:

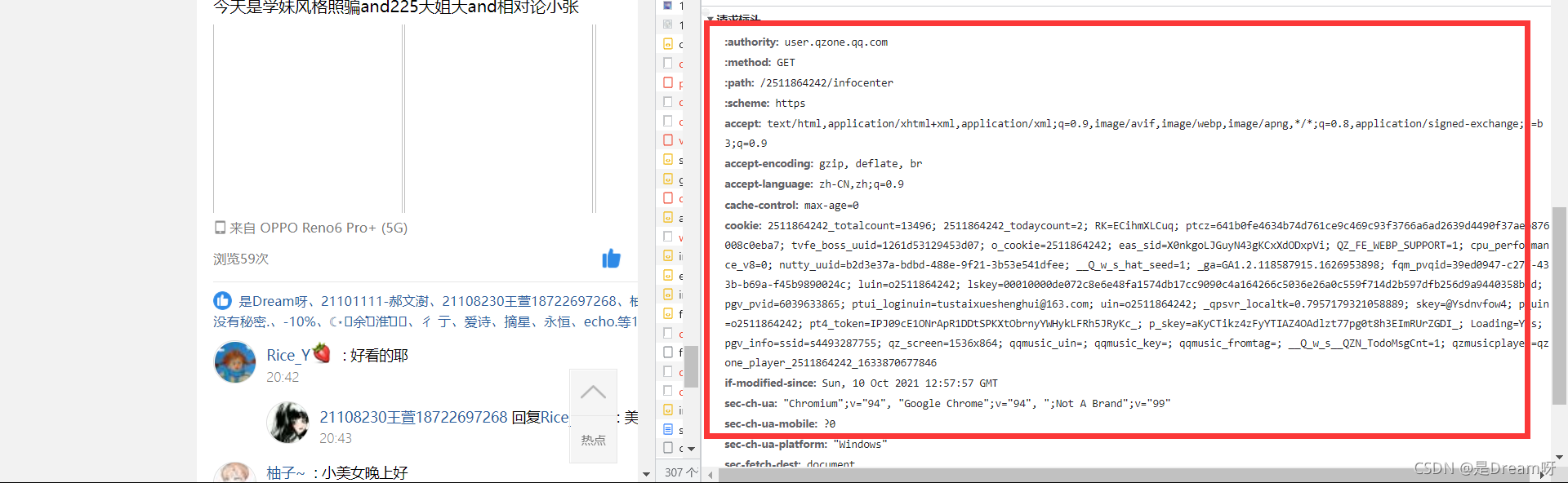
2.����cookie�������:
�������ͷ�е�ȫ�����ݶ�д��headers��:
':authority':' user.qzone.qq.com',
':method':' GET',
':path':' /2511864242/infocenter',
':scheme':' https',
'accept':' text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-encoding':' gzip, deflate, br',
'accept-language':' zh-CN,zh;q=0.9',
'cache-control':' max-age=0',
'cookie':' 2511864242_totalcount=13496; 2511864242_todaycount=2; RK=ECihmXLCuq; ptcz=641b0fe4634b74d761ce9c469c93f3766a6ad2639d4490f37aeb876008c0eba7; tvfe_boss_uuid=1261d53129453d07; o_cookie=2511864242; eas_sid=X0nkgoLJGuyN43gKCxXdODxpVi; QZ_FE_WEBP_SUPPORT=1; cpu_performance_v8=0; nutty_uuid=b2d3e37a-bdbd-488e-9f21-3b53e541dfee; __Q_w_s_hat_seed=1; _ga=GA1.2.118587915.1626953898; fqm_pvqid=39ed0947-c27f-433b-b69a-f45b9890024c; luin=o2511864242; lskey=00010000de072c8e6e48fa1574db17cc9090c4a164266c5036e26a0c559f714d2b597dfb256d9a9440358b1d; pgv_pvid=6039633865; ptui_loginuin=tustaixueshenghui@163.com; _gid=GA1.2.1366085169.1633784022; uin=o2511864242; _qpsvr_localtk=0.7957179321058889; skey=@Ysdnvfow4; p_uin=o2511864242; pt4_token=IPJ09cE1ONrApR1DDtSPKXtObrnyYWHykLFRh5JRyKc_; p_skey=aKyCTikz4zFyYTIAZ4OAdlzt77pg0t8h3EImRUrZGDI_; Loading=Yes; pgv_info=ssid=s4493287755; qz_screen=1536x864; qzmusicplayer=qzone_player_2511864242_1633869885141; qqmusic_uin=; qqmusic_key=; qqmusic_fromtag=',
'if-modified-since: Sun, 10 Oct 2021 12:44':'32 GMT',
'sec-ch-ua':' "Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"',
'sec-ch-ua-mobile':' ?0',
'sec-ch-ua-platform':' "Windows"',
'sec-fetch-dest':' document',
'sec-fetch-mode':' navigate',
'sec-fetch-site':' none',
'sec-fetch-user':' ?1',
'upgrade-insecure-requests':' 1',
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
����Щ������,:��ͷ�����ݿ϶�����û�õ�,ȥ��������,��ʵҲ����ֻ��cookie����,����˵���ǽ�cookie���ݱ���:
cookie��Я������ĵ�¼��Ϣ ����е�¼֮���cookie,�������ǾͿ���Я����cookie�����κν��档
# -*-coding:utf-8 -*-
# @Author:������,��������
# ��������!!!
import urllib.request
url = 'https://user.qzone.qq.com/2511864242/infocenter'
headers={
# ':authority':' user.qzone.qq.com',
# ':method':' GET',
# ':path':' /2511864242/infocenter',
# ':scheme':' https',
# 'accept':' text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding':' gzip, deflate, br',
# 'accept-language':' zh-CN,zh;q=0.9',
# 'cache-control':' max-age=0',
# 'cookie':' 2511864242_totalcount=13496; 2511864242_todaycount=2; RK=ECihmXLCuq; ptcz=641b0fe4634b74d761ce9c469c93f3766a6ad2639d4490f37aeb876008c0eba7; tvfe_boss_uuid=1261d53129453d07; o_cookie=2511864242; eas_sid=X0nkgoLJGuyN43gKCxXdODxpVi; QZ_FE_WEBP_SUPPORT=1; cpu_performance_v8=0; nutty_uuid=b2d3e37a-bdbd-488e-9f21-3b53e541dfee; __Q_w_s_hat_seed=1; _ga=GA1.2.118587915.1626953898; fqm_pvqid=39ed0947-c27f-433b-b69a-f45b9890024c; luin=o2511864242; lskey=00010000de072c8e6e48fa1574db17cc9090c4a164266c5036e26a0c559f714d2b597dfb256d9a9440358b1d; pgv_pvid=6039633865; ptui_loginuin=tustaixueshenghui@163.com; _gid=GA1.2.1366085169.1633784022; uin=o2511864242; _qpsvr_localtk=0.7957179321058889; skey=@Ysdnvfow4; p_uin=o2511864242; pt4_token=IPJ09cE1ONrApR1DDtSPKXtObrnyYWHykLFRh5JRyKc_; p_skey=aKyCTikz4zFyYTIAZ4OAdlzt77pg0t8h3EImRUrZGDI_; Loading=Yes; pgv_info=ssid=s4493287755; qz_screen=1536x864; qzmusicplayer=qzone_player_2511864242_1633869885141; qqmusic_uin=; qqmusic_key=; qqmusic_fromtag=',
# 'if-modified-since: Sun, 10 Oct 2021 12:44':'32 GMT',
# 'sec-ch-ua':' "Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"',
# 'sec-ch-ua-mobile':' ?0',
# 'sec-ch-ua-platform':' "Windows"',
# 'sec-fetch-dest':' document',
# 'sec-fetch-mode':' navigate',
# 'sec-fetch-site':' none',
# 'sec-fetch-user':' ?1',
# 'upgrade-insecure-requests':' 1',
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
}
# �������Ķ���
request = urllib.request.Request(url=url,headers = headers)
# ģ����������������������
response = urllib.request.urlopen(request)
# ��ȡ��Ӧ������
# content = response.read().decode('utf-8')
content = response.read().decode('utf-8')
# �����ݱ��浽����
with open('qq1.html','w',encoding='utf-8') as fp:
fp.write(content)
�鿴���:
��Ȼ��ȥ��QQ�ռ�:
�ġ�Handler������
ΪʲôҪѧϰhandler?
urllib.request.urlopen(url) :���ܶ�������ͷ urllib.request.Request(url,headers,data) :���Զ�������ͷ
Handler :���Ƹ���������ͷ(����ҵ�����ĸ��� �������Ķ����Ѿ����㲻�����ǵ�����(��̬cookie�ʹ��� ����ʹ���������Ķ���)
# -*-coding:utf-8 -*-
# @Author:������,��������
# ��������!!!
import urllib.request
url = 'https://www.baidu.com'
# �������Ķ���Ϊ�˽�������ĵ�һ���ֶ�
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers)
# handler build_opener open
# (1)��ȡhandler����
handler = urllib.request.HTTPHandler()
# (2)��ȡopener����
opener = urllib.request.build_opener(handler)
# ����open����
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)
�塢��������ʹ��
�����Լ�ip:ip
1.�����ij��ù���?
ͻ������IP��������,���ʹ���վ�㡣����һЩ��λ�������ڲ���Դ��չ:ij��ѧFTP(ǰ���Ǹô�����ַ�ڸ���Դ���������ʷ�Χ֮��),ʹ�ý������ڵ�ַ����Ѵ������� ��,�Ϳ������ڶԽ��������ŵĸ���FTP�����ϴ�,�Լ��������ϲ�ѯ�����ȷ�����߷����ٶ���չ:ͨ������������������һ���ϴ��Ӳ�̻�����,����������Ϣͨ��ʱ,ͬʱҲ���䱣�浽���� ����,�������û��ٷ�����ͬ����Ϣʱ, ��ֱ���ɻ�������ȡ����Ϣ,�����û�,����߷����ٶȡ�������ʵIP��չ:������Ҳ����ͨ�����ַ��������Լ���IP,���ܹ�����
2.��������
- ����Reuqest����
- ����ProxyHandler����
- ��handler����opener����
- ʹ��opener.open������������
1.�������ʴ�ҳ��:
# -*-coding:utf-8 -*-
# @Author:������,��������
# ��������!!!
import urllib.request
url='https://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# ���������
request = urllib.request.Request(url=url,headers=headers)
# ģ����������ʷ�����
response = urllib.request.urlopen(request)
# ��ȡ��Ӧ��Ϣ
content = response.read().decode('utf-8')
# ����
with open('daili.html','w',encoding='utf-8') as fp:
fp.write(content)
2.ʹ��handler����
ʹ�ô���ip���з���:��������IP
ʹ�ô���ip�����Լ�������ip��
# -*-coding:utf-8 -*-
# @Author:������,��������
# ��������!!!
import urllib.request
url='https://www.baidu.com/s?wd=ip'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# ���������
request = urllib.request.Request(url=url,headers=headers)
proxies={
'http':'118.24.219.151:16817'
}
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
# ģ����������ʷ�����
# response = urllib.request.urlopen(request)
response = opener.open(request)
# ��ȡ��Ӧ��Ϣ
content = response.read().decode('utf-8')
# ����
with open('yincangdaili1.html','w',encoding='utf-8') as fp:
fp.write(content)
📢📢📢���ĸ���
??????���һ��С�����������:������������python��С�����,�����ϸ����PPT����Ѹ�ٰ�����Ҵ���python����,��Ҫ��С����ǿ�������һ�� Python���Ż����̳�ȫ��+С���ٳ�+ѧ����������! 🍻🍻🍻
�������Ʊ�������,��Ҫ��ȡ:
Python��������,Դ��+����+������������+������ӱ 🍻🍻🍻

🌲🌲🌲 ����,����ǽ���Ҫ��������ҵ�ȫ��������
??????�����ϲ���Ļ�,�Ͳ�Ҫ��ϧ���һ��������~

