import sys
import random
import math
import os
import numpy as np
import pandas as pd
from operator import itemgetter
from collections import defaultdictrandom.seed(0)class UserBasedCF(object):
"""
TopN recommendation - User Based Collaborative Filtering
"""
def __init__(self):
self.trainset = {}
self.testset = {}
self.n_sim_user = 20
self.n_rec_movie = 5
self.user_sim_mat = {}
self.movie_popular = {}
self.movie_count = 0
print('Similar user number = %d' % self.n_sim_user, file=sys.stderr)
print('recommended movie number = %d' %
self.n_rec_movie, file=sys.stderr)
@staticmethod
def loadfile(filename):
"""
load a file, return a generator.
"""
fp = open(filename, 'r')
for i, line in enumerate(fp):
yield line.strip('\r\n')
if i % 100000 == 0:
print('loading %s(%s)' % (filename, i), file=sys.stderr)
fp.close()
print('load %s successfully' % filename, file=sys.stderr)
def generate_dataset(self, filename, pivot=0.7):
"""
load rating data and split it to training set and test set
"""
trainset_len = 0
testset_len = 0
for line in self.loadfile(filename):
user, movie, rating, _ = line.split('::')
# split the data by pivot
if random.random() < pivot:
self.trainset.setdefault(user, {})
self.trainset[user][movie] = int(rating)
trainset_len += 1
else:
self.testset.setdefault(user, {})
self.testset[user][movie] = int(rating)
testset_len += 1
print('split training set and test set successfully', file=sys.stderr)
print('train set = %s' % trainset_len, file=sys.stderr)
print('test set = %s' % testset_len, file=sys.stderr)
def calc_user_sim(self):
"""
calculate user similarity matrix
"""
# build inverse table for item-users
# key=movieID, value=list of userIDs who have seen this movie
print('building movie-users inverse table...', file=sys.stderr)
movie2users = dict()
for user, movies in self.trainset.items():
for movie in movies:
# inverse table for item-users
if movie not in movie2users:
movie2users[movie] = set()
movie2users[movie].add(user)
# count item popularity at the same time
if movie not in self.movie_popular:
self.movie_popular[movie] = 0
self.movie_popular[movie] += 1
print('build movie-users inverse table successfully', file=sys.stderr)
# save the total movie number, which will be used in evaluation
self.movie_count = len(movie2users)
print('total movie number = %d' % self.movie_count, file=sys.stderr)
# count co-rated items between users
usersim_mat = self.user_sim_mat
print('building user co-rated movies matrix...', file=sys.stderr)
for movie, users in movie2users.items():
for u in users:
usersim_mat.setdefault(u, defaultdict(int))
for v in users:
if u == v:
continue
usersim_mat[u][v] += 1
print('build user co-rated movies matrix successfully', file=sys.stderr)
# calculate similarity matrix
print('calculating user similarity matrix...', file=sys.stderr)
simfactor_count = 0
PRINT_STEP = 2000000
for u, related_users in usersim_mat.items():
for v, count in related_users.items():
usersim_mat[u][v] = count / math.sqrt(
len(self.trainset[u]) * len(self.trainset[v]))
simfactor_count += 1
if simfactor_count % PRINT_STEP == 0:
print('calculating user similarity factor(%d)' %
simfactor_count, file=sys.stderr)
print('calculate user similarity matrix(similarity factor) successfully',
file=sys.stderr)
print('Total similarity factor number = %d' %
simfactor_count, file=sys.stderr)
print(pd.DataFrame(usersim_mat))
def recommend(self, user):
"""
Find K similar users and recommend N movies.
"""
K = self.n_sim_user
N = self.n_rec_movie
rank = dict()
watched_movies = self.trainset[user]
for similar_user, similarity_factor in sorted(self.user_sim_mat[user].items(),
key=itemgetter(1), reverse=True)[0:K]:
for movie in self.trainset[similar_user]:
if movie in watched_movies:
continue
# predict the user's "interest" for each movie
rank.setdefault(movie, 0)
rank[movie] += similarity_factor
# return the N best movies
rec_movies = sorted(rank.items(), key=itemgetter(1), reverse=True)[0:N]
return rec_movies
def evaluate(self):
"""
print evaluation result: precision, recall, coverage and popularity
"""
print('Evaluation start...', file=sys.stderr)
N = self.n_rec_movie
# varables for precision and recall
hit = 0
rec_count = 0
test_count = 0
# varables for coverage
all_rec_movies = set()
# varables for popularity
popular_sum = 0
for i, user in enumerate(self.trainset):
if i % 500 == 0:
print('recommended for %d users' % i, file=sys.stderr)
test_movies = self.testset.get(user, {})
rec_movies = self.recommend(user)
for movie, _ in rec_movies:
if movie in test_movies:
hit += 1
all_rec_movies.add(movie)
popular_sum += math.log(1 + self.movie_popular[movie])
rec_count += N
test_count += len(test_movies)
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
popularity = popular_sum / (1.0 * rec_count)
print('precision=%.4f\trecall=%.4f\tcoverage=%.4f\tpopularity=%.4f' %
(precision, recall, coverage, popularity), file=sys.stderr)读取数据:
ratingfile = os.path.join('ml-1m', 'ratings.dat')现假定给用户i推荐电影,那么方案是:在用户i未观看过的电影中,以和用户i最相似的前20个用户为准,预测用户i会对这些电影的评分值,然后选出评分值最高的前5部电影。
usercf = UserBasedCF()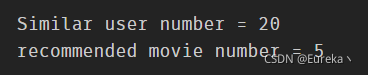
划分训练集和测试集:?
usercf.generate_dataset(ratingfile) ?
?
计算用户-用户相似度矩阵:
usercf.calc_user_sim()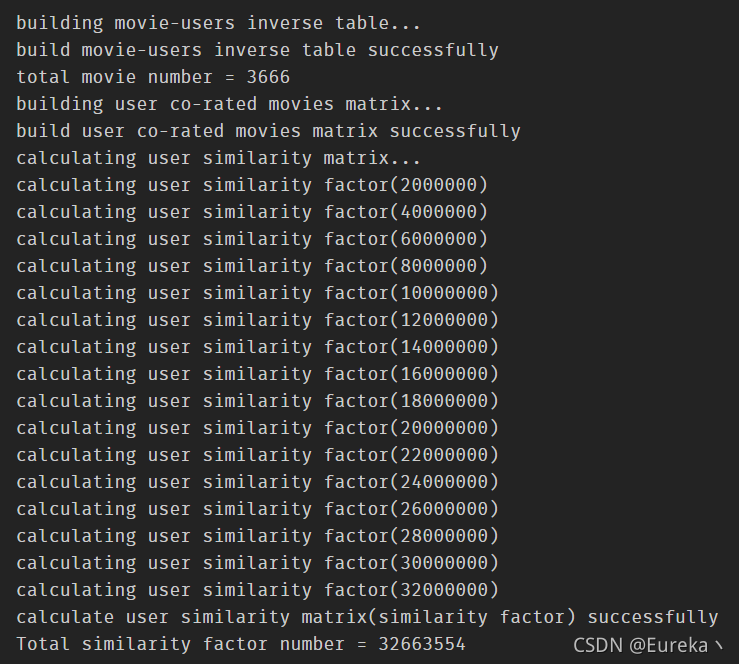
模型评估:
usercf.evaluate()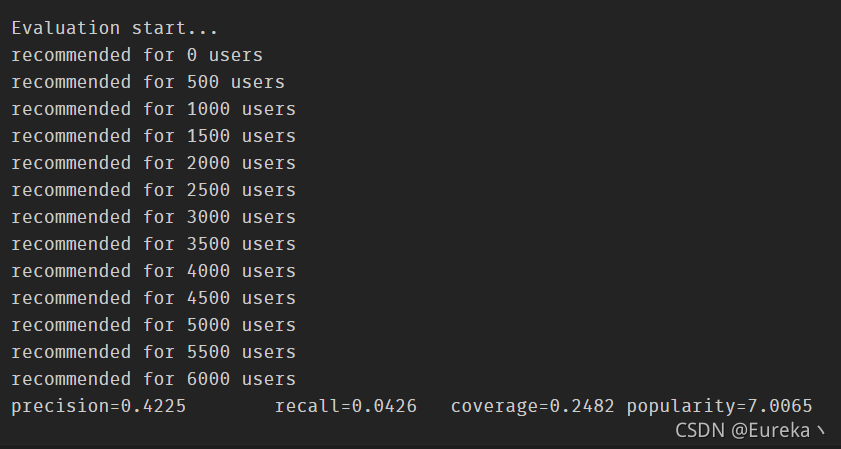
推荐示例:
Recommendations = usercf.recommend('2')
print(Recommendations)
括号中第一个值表示电影编号,第二个值表示预测评分值。