目录
一、字符问题??
字符串的概念就是一串字符,字符的概念?在英文中,我们可以认为每个数字、字母等都是字符,在中文中,每个汉字也都是字符,还有很多很多的符号也都是字符,但是这是现实世界中的字符,为了将现实世界中的字符存储到计算机上,我们就需要一套编码标准,比如最常见的unicode标准。
? ? ? ? 在unicode标准中,主要有两个概念最重要,一个是字符的标识(码位),一个是具体的字节表述(编码得到的二进制流)。
- 字符的标识即码位,也可以认为是索引,比如我们把现实世界中的所有字符排成一列,然后按按十进制从索引0开始往后标注,则这个索引就是码位。
- 字符的具体表述取决于所用的编码。编码的作用是把码位转换成字节序列,给计算机存储用的,把字节序列再转换成码位则是解码的过程。
- 一套字符的码位就是一个字符集,一般所说的编码即是对字符集中的码位进行编码。比如ascii字符集,其编码就是直接把码位转换成对应的8位二进制数。而对于unicode标准中的字符集来说,直接转换成二进制数需要占用太多存储空间,因此另寻了其它的编码方式,比如UTF-8。
? ? ? ? 综上,每个字符都对应字符集中的一个码位(可以看成是十进制索引,是字符的编码,可如果把字符类比为学校里的学生,则码位就是学生的学号),每个码位都可以通过特定的编码方式编码成字节序列。从码位(unicode)到字节序列(bytes)是编码,从字节序列到码位是解码。在python3中,str类型即相当于python2中的unicode类型,即内存中以码位对应二进制序列存储,而没有进行编码。
? ? ? ? unicode标准将字符集与编码方式进行了解耦,而ascii和gbk等没有做解耦,因此谈起后者一般指的是字符集和编码都有,且ascii和gbk都是只有一种编码方式。unicode标准的字符集和编码方式都有多种。
????????如下例子:


str对象调用encode方法可以转换成bytes对象,bytes对象调用decode方法可以转换成str对象,其中用的转换方法都是utf8,bytes对象字面量都是以b开头的。
二、字节概要
bytes与bytearray类型
python内置了两种基本的二进制序列类型:不可变的bytes类型和可变的bytearray类型。
? ? ? ? bytes或bytearray对象的各个元素是介于0-255之间的整数,但其切片是对应bytes或bytearray类型的二进制序列类型。如下例子:
cafe = bytes("cafe", encoding='utf_8')
print("bytes类型的cafe")
print(cafe)
print(cafe[0])
print(cafe[:1])
print(cafe.decode('utf_8'))
print('\n')
print("bytearray类型的cafe")
cafe_arr = bytearray(cafe)
print(cafe_arr)
print(cafe_arr[-1])
print(cafe_arr[-1:])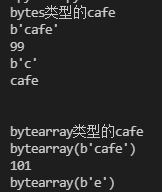
? ? ? ? bytes对象是以特定编码的形式存储在内存中,如上例中的cafe,即以utf_8编码的形式构建的bytes对象。其中第一个元素cafe[0]是c,对应码位当然也就是99,因为各个字符集都是兼容ascii的,在ascii中a是97,c自然就是99。但是其只含有一个元素的切片得到的还是一个bytes对象b'c'。把bytes对象解码成unicode对象即可用print直接打印出来。bytearray对象没有字面量的说法,如图所示是以bytes对象字面量加上bytearray()的形式打印的。且其中的元素也是0-255的整数。
? ? ? ? bytes和bytearray序列对象中各个元素都是0到255之间的整数,其实就是代表了一种8位的二进制表示。二进制序列对象中各个字节的值可能用三种不同的方式显示:

比如在例子 b'caf\xc3\xa9' 中,前三个字节的值b'caf'是在可打印的ascii范围内,第四个字节 ‘\xc3’和第五个字节 '\xa9' 则不在,即上边的第三种情况,其它字节的值,使用十六进制转义序列。
? ? ? ? 如下边例子,bytes等二进制序列类型相当于对码位进行编码,而unicode或str类型则相当于直接存储码位,下边两行都输出hello,这是因为不管是什么类型的编码,都是兼容ASCII的,而ASCII中编码就等于码位,因此下边两个的输出都是hello,但是一些不在ascii字符集中的字符,其bytes表示和str表示就不一样了。
b = b'hello'
print(b)
print(b.decode('utf_8'))![]()
? ? ? ? 二进制序列类型bytes和bytearray有很多方法都是跟str通用的,也有一个其特有的方法fromhex,作用是解析十六进制数字对,来构建一个二进制序列类型。如下所示,通过一个十六进制序列构建出的二进制序列类型对象b解码成str后是1KΩ。
b = bytes.fromhex('31 4B CE A9')
print(b)
print(b.decode('utf_8'))![]()
?构建bytes或bytearray对象可以调用构造方法,传入如下参数:
- 一个str对象和一个encoding关键字参数
- 一个可迭代对象,提供0~255之间的数值
- 一个实现了缓冲协议的对象(如bytes、bytearray、memoryview、array.array),此时把源对象中的字节序列复制到新键的二进制序列对象中。
? ? ? ? 如下例子,使用数组对象来构造bytes对象。定义数组对象的时候必须要指定类型,跟C语言数组比较相似,这里‘h’说明数组元素是16位即2字节的整数,一共有5个元素,因此最后生成的bytes对象octets是一个有10个字节的二进制序列对象。

结构体和内存视图
struct模块提供一些函数,将打包的字节序列转换成不同类型字段组成的元组,或把元组转换成打包的字节序列。struct模块具体分析如下。
? ? ? ?python之struct 模块详解_淘小欣的博客-CSDN博客_python struct模块
三、基本的编解码器
python3中,将str类型转换成对应bytes类型是编码,将bytes类型转成str是解码,这里的编解码器其实只是一个东西,比如‘utf_8’,编码解码都是它,并不存在一个编码器和一个解码器。python自带了超过100中编解码器。
? ? ? ? 下例使用三个不同编解码器来编码同一个字符串,编码得到的字节序列差异非常大。有些编解码器是不能编码所有的字符的码位的,比如ascii就只能处理有限的几百个字符,而utf编码则可以处理每一个unicode码位。

比较常见的编码有如下几个,ascii码就不说了。

?![]()
?
四、了解编解码问题
一般有三种错误,UnicodeEncodeError是把字符串转换成二进制序列时错误,UnicodeDecodeError是把二进制序列转成字符串时错误,如果在编写源码的时候,源码的编码与预期不符,则运行python模块即将.py文件加载到内存中时还可能抛出SyntaxError。
UnicodeEncodeError
把字符串转换成字节序列出错。比如多数非UTF编解码器只能处理Unicode字符集中的一小部分子集,因此编码某些字符时可能就会出现编码错误。


?

UnicodeDecodeError
有些字节序列,可能并不是有效的UTF-8或UTF-16,因此把这种二进制序列转换成文本时,如果采用utf8或utf16就会抛出UnicodeDecodeError。
? ? ? ? 另一方面,有些编解码器在遇到错误的字节序列的时候并不会抛出错误,而是得到一些无用的输出,即传说中的乱码。
????????
?
使用预期之外编码加载模块时抛出SyntaxError
把.py模块加载进内存时,python3默认以UTF-8来加载,即用UTF-8编码源码,而python2则默认以ASCII码加载。如果加载的.py模块中包含UTF-8之外的数据,且没有主动声明编码方式,则会得到以外错误信息:

 上边例子是说,在GNU/Linux和OS X系统中,.py文件在磁盘上的编码格式就是UTF-8,因此python解释器默认以UTF-8的形式加载源码当然不会出错,而在windows系统中,.py文件是以cp1252的格式编码的,而当python3解释器以UTF-8的格式来加载的时候当然会出错,因为源码在硬盘上存储时候的二进制流有些根本就不是UTF编码中的。
上边例子是说,在GNU/Linux和OS X系统中,.py文件在磁盘上的编码格式就是UTF-8,因此python解释器默认以UTF-8的形式加载源码当然不会出错,而在windows系统中,.py文件是以cp1252的格式编码的,而当python3解释器以UTF-8的格式来加载的时候当然会出错,因为源码在硬盘上存储时候的二进制流有些根本就不是UTF编码中的。
? ? ? ? 为了解决python3解释器以UTF-8格式加载源码导致的错误,我们可以在.py文件顶部添加一个coding注释,指定加载python源码时候用的编码格式,这样就不会错误了。

源码中使用非ASCII字符

找出字节序列的编码


BOM:有用的鬼符

如上,字符串u16的utf_16编码中,编码序列的开头有几个额外的字节,这是BOM,即字节序标记,指明编码时使用Intel CPU的小字节序。

五、处理文本文件
Unicode三明治

python3中内置的open函数在读取文件时会做必要的解码,写入文件时会做必要的编码,因此my_file.read()方法的返回值以及my_file.write(text)方法的参数text都是字符串对象。即硬盘上的文本文件本来时utf编码的,在用open打开该文件的时候进行了解码,得到的是字符串,写入文件的时候也是把字符串重新编码写入文件。
不能依赖默认编码


python解释器在windows平台下的时候,在打开文件时会默认文件是以windows平台的编码存储的,而上边写入文件的时候我们人为规定了编码格式,因此实际的编码格式是utf_8,但是读取的时候是俺windows 1252读取的,当然有错。当然以windows 1252的格式读取之后,在内存中的实际存储形式是unicode,即没有进行编码,是直接的str格式。
? ? ? ? 如果打开文件是为了写入内容,如果我们在写入的时候没有指定编码格式,则会使用该平台下默认的编码格式。再读取的时候也要用那个编码格式来读取。


六、为了正确比较而规范化Unicode字符串
规范化函数unicodedata.normalize


U+0301就相当于是e上边的那个撇。所以s1和s2我们的本意是相同的字符串,但是python看到的码位序列是不同的啊,为了解决这个问题,需要使用unicodedata.normalize函数提供的Unicode规范化。此函数第一个参数是以下四个字符串的一个:’NFC‘,’NFD‘,'NFKC'和’NFKD‘。

?
?
由以上例子可以看出,本来我们直接判断s1与s2是否相等,得到的结果是不相等,但是如果对s1和s2都施以同样的规范化处理,则再判断二者即相等。
? ? ? ? 使用NFC时,可以会直接把一个单字符规范化成了另一个单字符。比如下例电阻的欧姆被NFC规范化成了希腊字母大写的欧米茄。

NFKC和NFKD中K是兼容性的意思。各个兼容字符会被替换成一个或多个兼容分解字符。

兼容分解可能会改变原意:

?
?NFKC和NFKD只能在搜索和索引时使用。
大小写折叠
就是把所有文件变成小写。由str.casefold()方法支持。

?
?casefold和lower只在有限数量的码位上结果不同。

极端规范化,去掉变音符号
google搜索中很多时候就会去掉变音符号,虽然这样可能改变了原意,但是很多时候因为麻烦很多人都不会敲变音符号上去。而且去掉变音符号有时候能让URL更易于阅读。

大概知道这个概念就可,暂时不必深究。
七、Unicode文本排序

?码位就是索引,比较字符时,其实比较的是其在字符集中的索引。

python中非ASCII文本的标准排序方式是使用locale.strxfrm函数,这个函数在比较字符串时会考虑区域的影响,即在使用locale.strxfrm函数之前,必须先设定合适的区域。如下例:、

setlocale即设置区域,区域设置是全局的,应用应在进程启动时设定区域,此后不要修改。

?必须知道如何拼写区域名称,操作系统必须正确实现了所设的区域。

?标准库中的排序方案不够用,可以使用PyPI中的PyUCA库,实现unicode排序算法。

八、Unicode数据库

九、支持字符串和字节序列的双模式API
re和os模块中的某种函数,既能接受字符串,也能接受字节序列为参数,然后根据参数类型的不同展开不同的行为。因此叫双模式API嘛。
正则表达式中的字符串和字节序列

?
os函数中的字符串和字节序列
?
?
?
?
?