Numpy��ѧϰ
���ڲ���̳̺�ƽʱѧϰ�ľ����ʵ�ټ�¼�㼯���ɡ�
0. ������������
0.1 Ndarray ����
NumPy ����Ҫ��һ���ص����� N ά������� ndarray,����һϵ��ͬ�������ݵļ���,�� 0 �±�Ϊ��ʼ���м�����Ԫ�ص�������
ndarray ���������ڴ��ͬ����Ԫ�صĶ�ά���顣
ndarray �е�ÿ��Ԫ�����ڴ��ж�����ͬ�洢��С������
ndarray �ڲ��������������:
- һ��ָ������(�ڴ���ڴ�ӳ���ļ��е�һ������)��ָ�롣
- �������ͻ� dtype,�����������еĹ̶���Сֵ�ĸ��ӡ�
- һ����ʾ������״(shape)��Ԫ��,��ʾ��ά�ȴ�С��Ԫ�顣
- һ�����Ԫ��(stride),���е�����ָ����Ϊ��ǰ������ǰά����һ��Ԫ����Ҫ"���"���ֽ�����
ndarray ���ڲ��ṹ:
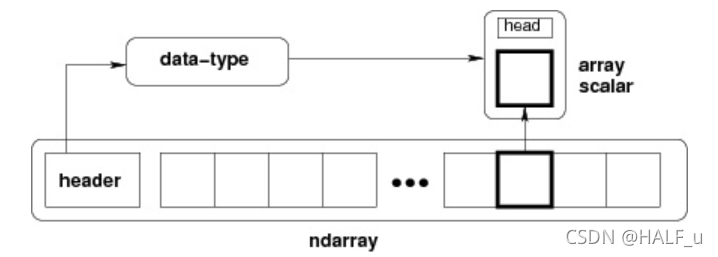
��ȿ����Ǹ���,������ʹ�������ڴ��к����ƶ�,��Ƭ�� obj[::-1] �� obj[:,::-1] ������ˡ�
����һ�� ndarray ֻ����� NumPy �� array ��������:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
| ���� | ���� |
|---|---|
| object | �����Ƕ������ |
| dtype | ����Ԫ�ص���������,��ѡ |
| copy | �����Ƿ���Ҫ����,��ѡ |
| order | �����������ʽ,CΪ�з���,FΪ�з���,AΪ���ⷽ��(Ĭ��) |
| subok | Ĭ�Ϸ���һ�����������һ�µ����� |
| ndmin | ָ�������������Сά�� |
0.2 ���� NumPy ��������
0.2.1 �������Ͷ��� (dtype)
�������Ͷ���(numpy.dtype ���ʵ��)���������������Ӧ���ڴ����������ʹ��,�����������ݵ����¼�������::
- ���ݵ�����(����,���������� Python ����)
- ���ݵĴ�С(����, ����ʹ�ö��ٸ��ֽڴ洢)
- ���ݵ��ֽ�˳��(С�˷����˷�)
�ڽṹ�����͵������,�ֶε����ơ�ÿ���ֶε��������ͺ�ÿ���ֶ���ȡ���ڴ��IJ���
�������������������,��ô������״������������ʲô��
�ֽ�˳����ͨ������������Ԥ���趨 < �� > �������ġ� < ��ζ��С�˷�(��Сֵ�洢����С�ĵ�ַ,����λ�������ǰ��)��> ��ζ�Ŵ�˷�(����Ҫ���ֽڴ洢����С�ĵ�ַ,����λ�������ǰ��)��
dtype ������ʹ������������:
numpy.dtype(object, align, copy)
- object - Ҫת��Ϊ���������Ͷ���
- align - ���Ϊ true,����ֶ�ʹ������ C �Ľṹ�塣
- copy - ���� dtype ���� ,���Ϊ false,���Ƕ������������Ͷ��������
0.3 ��������
| ���� | ˵�� |
|---|---|
| ndarray.ndim | ��,�����������ά�ȵ����� |
| ndarray.shape | �����ά��,���ھ���,n �� m �� |
| ndarray.size | ����Ԫ�ص��ܸ���,�൱�� .shape �� n*m ��ֵ |
| ndarray.dtype | ndarray �����Ԫ������ |
| ndarray.itemsize | ndarray ������ÿ��Ԫ�صĴ�С,���ֽ�Ϊ��λ |
| ndarray.flags | ndarray ������ڴ���Ϣ |
| ndarray.real | ndarray Ԫ�ص�ʵ�� |
| ndarray.imag | ndarray Ԫ�ص��鲿 |
| ndarray.data | ����ʵ������Ԫ�صĻ�����,����һ��ͨ�������������ȡԪ��,����ͨ������Ҫʹ��������ԡ� |
1. ��������
1.1 ��ͨ��������
- numpy.empty
- numpy.zeros
- numpy.ones
numpy.empty
numpy.empty ������������һ��ָ����״(shape)����������(dtype)��δ��ʼ��(��������������ֵ)������:
numpy.empty(shape, dtype = float, order = 'C')
����˵��:
| ���� | ���� |
|---|---|
| shape | ������״ |
| dtype | ��������,��ѡ |
| order | ��"C"��"F"����ѡ��,�ֱ����,�����Ⱥ�������,�ڼ�����ڴ��еĴ洢Ԫ�ص�˳�� |
numpy.zeros
����ָ����С������,����Ԫ���� 0 �����:
numpy.zeros(shape, dtype = float, order = 'C')
����˵��:
| ���� | ���� |
|---|---|
| shape | ������״ |
| dtype | ��������,��ѡ |
| order | ��C�� ���� C ��������,���� ��F�� ���� FORTRAN �������� |
numpy.ones
����ָ����״������,����Ԫ���� 1 �����:
numpy.ones(shape, dtype = None, order = 'C')
����˵��:
| ���� | ���� |
|---|---|
| shape | ������״ |
| dtype | ��������,��ѡ |
| order | ��C�� ���� C ��������,���� ��F�� ���� FORTRAN �������� |
1.2 �����е����鴴������
- numpy.asarray
- numpy.frombuffer
- numpy.fromiter
numpy.asarray
numpy.asarray ���� numpy.array,�� numpy.asarray ����ֻ������,�� numpy.array ��������
numpy.asarray(a, dtype = None, order = None)
����˵��:
| ���� | ���� |
|---|---|
| a | ������ʽ���������,������,�б�, �б���Ԫ��, Ԫ��, Ԫ���Ԫ��, Ԫ����б�,��ά���� |
| dtype | ��������,��ѡ |
| order | ��ѡ,��"C"��"F"����ѡ��,�ֱ����,�����Ⱥ�������,�ڼ�����ڴ��еĴ洢Ԫ�ص�˳�� |
numpy.frombuffer
numpy.frombuffer ����ʵ�ֶ�̬���顣
numpy.frombuffer ���� buffer �������,��������ʽ����ת���� ndarray ����
numpy.fromiter
numpy.fromiter �����ӿɵ��������н��� ndarray ����,����һά���顣
1.3 ����ֵ��Χ��������
- numpy.arange
- numpy.linspace
- numpy.logspace
numpy.arange
numpy ���е�ʹ�� arange ����������ֵ��Χ������ ndarray ����,������ʽ����:
numpy.arange(start, stop, step, dtype)
���� start �� stop ָ���ķ�Χ�Լ� step �趨�IJ���,����һ�� ndarray��
����˵��:
| ���� | ���� |
|---|---|
| start | ��ʼֵ,Ĭ��Ϊ0 |
| stop | ��ֵֹ(������) |
| step | ����,Ĭ��Ϊ1 |
| dtype | ����ndarray����������,���û���ṩ,���ʹ���������ݵ����͡� |
numpy.linspace
numpy.linspace �������ڴ���һ��һά����,������һ���Ȳ����й��ɵ�,��ʽ����:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
| ���� | ���� |
|---|---|
| start | ���е���ʼֵ |
| stop | ���е���ֵֹ,���endpointΪtrue,��ֵ������������ |
| num | Ҫ���ɵĵȲ�������������,Ĭ��Ϊ50 |
| endpoint | ��ֵΪ true ʱ,�������а���stopֵ,��֮������,Ĭ����True�� |
| retstep | ���Ϊ True ʱ,���ɵ������л���ʾ���,��֮����ʾ�� |
| dtype | ndarray ���������� |
numpy.logspace
numpy.logspace �������ڴ���һ���ڵȱ����С���ʽ����:
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
base ������˼��ȡ������ʱ�� log ���±ꡣ
| ���� | ���� |
|---|---|
| start | ���е���ʼֵΪ:base ** start |
| stop | ���е���ֵֹΪ:base ** stop�����endpointΪtrue,��ֵ������������ |
| num | Ҫ���ɵĵȲ�������������,Ĭ��Ϊ50 |
| endpoint | ��ֵΪ true ʱ,�������а���stopֵ,��֮������,Ĭ����True�� |
| base | ���� log �ĵ����� |
| dtype | ndarray ���������� |
1.4 ��Ƭ������
- ���� start, stop �� step ��������
- ͨ��slice()������[:]ð��
- ʡ�Ժ� ��,��ʹѡ��Ԫ��ij����������ά����ͬ
ndarray��������ݿ���ͨ����������Ƭ�����ʺ���,�� Python �� list ����Ƭ����һ����
ndarray ������Ի��� 0 - n ���±��������,��Ƭ�������ͨ�����õ� slice ����,������ start, stop �� step ��������,��ԭ�������и��һ�������顣
a = np.arange(10)
s = slice(2,7,2) # ������ 2 ��ʼ������ 7 ֹͣ,���Ϊ2
print (a[s])
������Ϊ:
[2 4 6]
����Ҳ����ͨ��ð�ŷָ���Ƭ���� start:stop:step ��������Ƭ����:
a = np.arange(10)
b = a[2:7:2] # ������ 2 ��ʼ������ 7 ֹͣ,���Ϊ 2
print(b)
������Ϊ:
[2 4 6]
ð�� : �Ľ���:���ֻ����һ������,�� [2],����������������Ӧ�ĵ���Ԫ�ء����Ϊ [2:],��ʾ�Ӹ�������ʼ�Ժ�������������ȡ�����ʹ������������,�� [2:7],��ô����ȡ��������(������ֹͣ����)֮����
��ά����ͬ����������������ȡ����:
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print(a)
# ��ij����������ʼ�и�
print('���������� a[1:] ����ʼ�и�')
print(a[1:])
������Ϊ:
[[1 2 3]
[3 4 5]
[4 5 6]]
���������� a[1:] ����ʼ�и�
[[3 4 5]
[4 5 6]]
��Ƭ��������ʡ�Ժ� ��,��ʹѡ��Ԫ��ij����������ά����ͬ�� �������λ��ʹ��ʡ�Ժ�,�������ذ�������Ԫ�ص� ndarray��
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print (a[...,1]) # ��2��Ԫ��
print (a[1,...]) # ��2��Ԫ��
print (a[...,1:]) # ��2�м�ʣ�µ�����Ԫ��
������Ϊ:
[2 4 5]
[3 4 5]
[[2 3]
[4 5]
[5 6]]
1.5 ������
NumPy ��һ��� Python �����ṩ�����������ʽ������֮ǰ����������������Ƭ��������,�����������������������������������ʽ������
������������
����ʵ����ȡ������(0,0),(1,1)��(2,0)λ�ô���Ԫ�ء�
x�ĵ�һ�������������������㼯������,�ڶ��������������������㼯�����顣
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
print (y)
������Ϊ:
[1 4 5]
����ʵ����ȡ�� 4X3 �����е��ĸ��ǵ�Ԫ�ء� �������� [0,0] �� [3,3],���������� [0,2] �� [0,2]��
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('���ǵ�������:' )
print (x)
print ('\n')
rows = np.array([[0,0],[3,3]])
cols = np.array([[0,2],[0,2]])
y = x[rows,cols]
print ('���������ĸ���Ԫ����:')
print (y)
������Ϊ:
���ǵ�������:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
���������ĸ���Ԫ����:
[[ 0 2]
[ 9 11]]
���صĽ���ǰ���ÿ����Ԫ�ص� ndarray ����
���Խ�����Ƭ : �� �� ������������ϡ�����������:
import numpy as np
a = np.array([[1,2,3], [4,5,6],[7,8,9]])
b = a[1:3, 1:3]
c = a[1:3,[1,2]]
d = a[...,1:]
print(b)
print(c)
print(d)
������Ϊ:
[[5 6]
[8 9]]
[[5 6]
[8 9]]
[[2 3]
[5 6]
[8 9]]
��������
���ǿ���ͨ��һ����������������Ŀ�����顣
��������ͨ����������(��:�Ƚ������)����ȡ����ָ��������Ԫ�ص����顣
����ʵ����ȡ���� 5 ��Ԫ��:
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('���ǵ�������:')
print (x)
print ('\n')
# �������ǻ��ӡ������ 5 ��Ԫ��
print ('���� 5 ��Ԫ����:')
print (x[x > 5])
������Ϊ:
���ǵ�������:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
���� 5 ��Ԫ����:
[ 6 7 8 9 10 11]
����ʵ��ʹ���� ~(ȡ�������)������ NaN��
a = np.array([np.nan, 1,2,np.nan,3,4,5])
print (a[~np.isnan(a)])
������Ϊ:
[ 1. 2. 3. 4. 5.]
����ʵ����ʾ��δ������й��˵��Ǹ���Ԫ�ء�
a = np.array([1, 2+6j, 5, 3.5+5j])
print (a[np.iscomplex(a)])
�������:
[2.0+6.j 3.5+5.j]
��ʽ����
��ʽ����ָ�������������������������
��ʽ�����������������ֵ��ΪĿ�������ij������±���ȡֵ������ʹ��һά����������Ϊ����,���Ŀ����һά����,��ô�����Ľ�����Ƕ�Ӧ�±����,���Ŀ���Ƕ�ά����,��ô���Ƕ�Ӧλ�õ�Ԫ�ء�
��ʽ��������Ƭ��һ��,�����ǽ����ݸ��Ƶ��������С�
1������˳����������
import numpy as np
x=np.arange(32).reshape((8,4))
print (x[[4,2,1,7]])
������Ϊ:
[[16 17 18 19]
[ 8 9 10 11]
[ 4 5 6 7]
[28 29 30 31]]
2�����뵹����������
import numpy as np
x=np.arange(32).reshape((8,4))
print (x[[-4,-2,-1,-7]])
������Ϊ:
[[16 17 18 19]
[24 25 26 27]
[28 29 30 31]
[ 4 5 6 7]]
3����������������(Ҫʹ��np.ix_)
import numpy as np
x=np.arange(32).reshape((8,4))
print (x[np.ix_([1,5,7,2],[0,3,1,2])])
������Ϊ:
[[ 4 7 5 6]
[20 23 21 22]
[28 31 29 30]
[ 8 11 9 10]]
x[np.ix_([1,5,7,2],[0,3,1,2])]��仰�����һ��4*4�ľ���,���е�Ԫ�طֱ���:
x[1,0] x[1,3] x[1,1] x[1,2]
x[5,0] x[5,3] x[5,1] x[5,2]
x[7,0] x[7,3] x[7,1] x[7,2]
x[2,0] x[2,3] x[2,1] x[2,2]
�൱��:
y=np.array([[x[1,0], x[1,3], x[1,1], x[1,2]],\
[x[5,0], x[5,3], x[5,1],x[5,2]],\
[x[7,0] ,x[7,3], x[7,1], x[7,2]],\
[x[2,0], x[2,3], x[2,1], x[2,2]]])
����˵,��� np.xi_ �����������б�,���һ���б�����Ǵ���ȡԪ�ص��б�,�ڶ����б�����Ǵ���ȡԪ�ص��б�,��һ���б��е�ÿ��Ԫ�ض�������ڶ����б��е�ÿ��ֵ,�����¾����һ��Ԫ�ء�
2. �������
2.1 �㲥(Broadcast)
�㲥(Broadcast)�� numpy �Բ�ͬ��״(shape)�����������ֵ����ķ�ʽ, ���������������ͨ������Ӧ��Ԫ���Ͻ��С�
����������� a �� b ��״��ͬ,������ a.shape == b.shape,��ô a*b �Ľ������ a �� b �����Ӧλ��ˡ���Ҫ��ά����ͬ,�Ҹ�ά�ȵij�����ͬ��
�������е� 2 ���������״��ͬʱ,numpy ���Զ������㲥���ơ���:
a = np.array([[ 0, 0, 0],
[10,10,10],
[20,20,20],
[30,30,30]])
b = np.array([1,2,3])
print(a + b)
������Ϊ:
[[ 1 2 3]
[11 12 13]
[21 22 23]
[31 32 33]]
�����ͼƬչʾ������ b ���ͨ���㲥�������� a ���ݡ�

4x3 �Ķ�ά�����볤Ϊ 3 ��һά�������,��Ч�ڰ����� b �ڶ�ά���ظ� 4 ��������:
a = np.array([[ 0, 0, 0],
[10,10,10],
[20,20,20],
[30,30,30]])
b = np.array([1,2,3])
bb = np.tile(b, (4, 1)) # �ظ� b �ĸ���ά��
print(a + bb)
������Ϊ:
[[ 1 2 3]
[11 12 13]
[21 22 23]
[31 32 33]]
�㲥�Ĺ���:
- �������������鶼��������״������鿴��,��״�в���IJ��ֶ�ͨ����ǰ��� 1 ���롣
- ����������״������������״�ĸ���ά���ϵ����ֵ��
- ������������ij��ά�Ⱥ��������Ķ�Ӧά�ȵij�����ͬ�����䳤��Ϊ 1 ʱ,��������ܹ���������,���������
- �����������ij��ά�ȵij���Ϊ 1 ʱ,���Ŵ�ά������ʱ���ô�ά���ϵĵ�һ��ֵ��
������:����������,�ֱ�Ƚ����ǵ�ÿһ��ά��(������һ������û�е�ǰά�������),����:
- ����ӵ����ͬ��״��
- ��ǰά�ȵ�ֵ��ȡ�
- ��ǰά�ȵ�ֵ��һ���� 1��
������������,�׳� ��ValueError: frames are not aligned�� �쳣��
����:
numpy.tile(A , reps)
����� A ��������,reps ������һ����,һ���б���Ԫ����������,��������������͡���Ҫ����ȷ,�Ȱ� A ����һ����(����һ������,��ֿ��о�ÿ��Ԫ��)��
(1)��� reps ��һ����,���ǼĽ� A ���Ҹ��� reps - 1 ���γ��µ�����,���� reps �� A ��������:
import numpy as np
a = np.array([[1,2],[3,4]],dtype='i1')
print(a,'\n')
b = np.tile(a,2) #���Ҹ���,���� A ��������
print(b)
���:
[[1 2]
[3 4]]
[[1 2 1 2]
[3 4 3 4]]
(2)��� reps ��һ�� array-like(�������,���б�,Ԫ��,����)���͵�,��������Ԫ��,�� [m , n],ʵ���Ͼ��ǽ� A ������� m * n �� A ��ɵ�������,�� m ��,n �� A:
import numpy as np
a = np.array([[1,2],[3,4]],dtype='i1')
print(a,'\n')
b = np.tile(a,(2,3)) #2 * 3 �� A ���������
print(b)
���:
[[1 2]
[3 4]]
[[1 2 1 2 1 2]
[3 4 3 4 3 4]
[1 2 1 2 1 2]
[3 4 3 4 3 4]]
2.2 ��������
NumPy ���������� numpy.nditer �ṩ��һ��������һ�����߶������Ԫ�صķ�ʽ��
�����������������Ŀ�����ɶ�����Ԫ�صķ��ʡ�
ʵ������ʹ�ñ� C ���� Fortran ˳��,ѡ���˳���Ǻ������ڴ沼��һ�µ�,��������Ϊ���������ʵ�Ч��,Ĭ������������(row-major order,����˵�� C-order)��
�ⷴӳ��Ĭ�������ֻ�����ÿ��Ԫ��,�����迼�����ض�˳�����ǿ���ͨ���������������ת����������һ��,������ C ˳���������ת�õ� copy ��ʽ���Աȡ�
a �� a.T �ı���˳����һ����,Ҳ�����������ڴ��еĴ洢˳��Ҳ��һ����,���� a.T.copy(order = ��C��) �ı�������Dz�ͬ��,������Ϊ����ǰ���ֵĴ洢��ʽ�Dz�һ����,Ĭ���ǰ��з��ʡ�
���Ʊ���˳��
- for x in np.nditer(a, order=��F��):Fortran order,������������;
- for x in np.nditer(a.T, order=��C��):C order,������������;
��������Ԫ�ص�ֵ
nditer ��������һ����ѡ���� op_flags�� Ĭ�������,nditer ���Ӵ���������������Ϊֻ������(read-only),Ϊ���ڱ��������ͬʱ,ʵ�ֶ�����Ԫ��ֵ����,����ָ�� read-write ���� write-only ��ģʽ��
ʹ���ⲿѭ��
nditer ��Ĺ�����ӵ�� flags ����,�����Խ�������ֵ:
| ���� | ���� |
|---|---|
| c_index | ���Ը��� C ˳������� |
| f_index | ���Ը��� Fortran ˳������� |
| multi_index | ÿ�ε������Ը���һ���������� |
| external_loop | ������ֵ�Ǿ��ж��ֵ��һά����,��������ά���� |
�㲥����
������������ǿɹ㲥��,nditer ��϶����ܹ�ͬʱ�������ǡ� �������� a ��ά��Ϊ 3X4,���� b ��ά��Ϊ 1X4 ,��ʹ�����µ�����(���� b ���㲥�� a �Ĵ�С)��
2.3 �������
Numpy �а�����һЩ�������ڴ�������,��ſɷ�Ϊ���¼���:
- ��������״
- ��ת����
- ��������
- ��������
- �ָ�����
- ����Ԫ�ص�������ɾ��
2.3.1 ��������״
- reshape:���ı����ݵ�����������״
- flat:����Ԫ�ص�����
- flatten:����һ�����鿽��,�Կ����������IJ���Ӱ��ԭʼ����
- ravel:����չ������
numpy.reshape
numpy.reshape ���������ڲ��ı����ݵ�����������״,��ʽ����: numpy.reshape(arr, newshape, order=��C��)
- arr:Ҫ����״������
- newshape:����������������,�µ���״Ӧ������ԭ����״
- order:��C�� �C ����,��F�� �C ����,��A�� �C ԭ˳��,��k�� �C Ԫ�����ڴ��еij���˳��
numpy.ndarray.flat
numpy.ndarray.flat ��һ������Ԫ�ص�����,ʵ������:
import numpy as np
a = np.arange(9).reshape(3,3)
print ('ԭʼ����:')
for row in a:
print (row)
#��������ÿ��Ԫ�ض����д���,����ʹ��flat����,��������һ������Ԫ�ص�����:
print ('�����������:')
for element in a.flat:
print (element)
����������:
ԭʼ����:
[0 1 2]
[3 4 5]
[6 7 8]
�����������:
0
1
2
3
4
5
6
7
8
numpy.ndarray.flatten
numpy.ndarray.flatten ����һ�����鿽��,�Կ����������IJ���Ӱ��ԭʼ����,��ʽ����:
ndarray.flatten(order='C')
numpy.ravel
numpy.ravel() չƽ������Ԫ��,˳��ͨ����"C���",���ص���������ͼ(view,�е����� C/C++����reference����ζ),�Ļ�Ӱ��ԭʼ���顣
�ú���������������:
numpy.ravel(a, order='C')
����˵��:
- order:��C�� �C ����,��F�� �C ����,��A�� �C ԭ˳��,��K�� �C Ԫ�����ڴ��еij���˳��
2.3.2 ��ת����
- transpose:�Ի������ά��
- ndarray.T �� self.transpose() ��ͬ
- rollaxis:������ָ������
- swapaxes:�Ի������������
numpy.transpose
numpy.transpose �������ڶԻ������ά��,��ʽ����:
numpy.transpose(arr, axes)
����˵��:
- arr:Ҫ����������
- axes:�����б�,��Ӧά��,ͨ������ά�ȶ���Ի���
numpy.rollaxis
numpy.rollaxis �����������ض����ᵽһ���ض�λ��,��ʽ����:
numpy.rollaxis(arr, axis, start)
����˵��:
- arr:����
- axis:Ҫ����������,����������λ�ò���ı�
- start:Ĭ��Ϊ��,��ʾ�����Ĺ�������������ض�λ�á�
import numpy as np
# ���������� ndarray
a = np.arange(8).reshape(2,2,2)
print ('ԭ����:')
print (a)
print ('��ȡ������һ��ֵ:')
print(np.where(a==6))
print(a[1,1,0]) # Ϊ 6
print ('\n')
# ���� 2 �������� 0(���ȵ����)
print ('���� rollaxis ����:')
b = np.rollaxis(a,2,0)
print (b)
# �鿴Ԫ�� a[1,1,0],�� 6 ������,��� [0, 1, 1]
# ���һ�� 0 �ƶ�����ǰ��
print(np.where(b==6))
print ('\n')
# ���� 2 �������� 1:(���ȵ��߶�)
print ('���� rollaxis ����:')
c = np.rollaxis(a,2,1)
print (c)
# �鿴Ԫ�� a[1,1,0],�� 6 ������,��� [1, 0, 1]
# ���� 0 �� ��ǰ��� 1 �Ի�λ��
print(np.where(c==6))
print ('\n')
����������:
ԭ����:
[[[0 1]
[2 3]]
[[4 5]
[6 7]]]
��ȡ������һ��ֵ:
(array([1]), array([1]), array([0]))
6
���� rollaxis ����:
[[[0 2]
[4 6]]
[[1 3]
[5 7]]]
(array([0]), array([1]), array([1]))
���� rollaxis ����:
[[[0 2]
[1 3]]
[[4 6]
[5 7]]]
(array([1]), array([0]), array([1]))
numpy.swapaxes
numpy.swapaxes �������ڽ��������������,��ʽ����:
numpy.swapaxes(arr, axis1, axis2)
- arr:���������
- axis1:��Ӧ��һ���������
- axis2:��Ӧ�ڶ����������
import numpy as np
# ���������� ndarray
a = np.arange(8).reshape(2,2,2)
print ('ԭ����:')
print (a)
print ('\n')
# ���ڽ����� 0(��ȷ���)���� 2(���ȷ���)
print ('���� swapaxes �����������:')
print (np.swapaxes(a, 2, 0))
����������:
ԭ����:
[[[0 1]
[2 3]]
[[4 5]
[6 7]]]
���� swapaxes �����������:
[[[0 4]
[2 6]]
[[1 5]
[3 7]]]
2.3.3 ��������
- broadcast:����ģ�¹㲥�Ķ���
- broadcast_to ������㲥������״
- expand_dims:��չ�������״
- squeeze:���������״��ɾ��һά��Ŀ
2.3.4 ��������
- concatenate:���������������������
- stack:�����µ������һϵ�����顣
- hstack:ˮƽ�ѵ������е�����(�з���)
- vstack:��ֱ�ѵ������е�����(�з���)
2.3.5 �ָ�����
- split:��һ������ָ�Ϊ���������
- hsplit:��һ������ˮƽ�ָ�Ϊ���������(����)
- vsplit:��һ�����鴹ֱ�ָ�Ϊ���������(����)
2.3.6 ����Ԫ�ص�������ɾ��
- resize:����ָ����״��������
- append:��ֵ���ӵ�����ĩβ
- insert:��ָ���Ὣֵ���뵽ָ���±�֮ǰ
- delete:ɾ��ij�����������,������ɾ�����������
- unique:���������ڵ�ΨһԪ��
2.4 ���
NumPy ��bitwise_�� ��ͷ�ĺ�����λ���㺯����
NumPy λ����������¼�������:
| ���� | ���� |
|---|---|
| bitwise_and | ������Ԫ��ִ��λ����� |
| bitwise_or | ������Ԫ��ִ��λ����� |
| invert | ��λȡ�� |
| left_shift | �����ƶ������Ʊ�ʾ��λ |
| right_shift | �����ƶ������Ʊ�ʾ��λ |
ע:Ҳ����ʹ�� ��&���� ��~���� ��|�� �� ��^�� �Ȳ��������м��㡣
3. ��غ���
3.1 �ַ�������
�ַ�������
3.2 ��ѧ����
��ѧ����
3.3 ��������
��������
3.4 ͳ�ƺ���
ͳ�ƺ���
3.5 ��������ˢѡ����
��������ˢѡ����
4. ����
4.1 �ֽڽ���
�ֽڽ���
4.2 ��������ͼ
��������ͼ
4.3 �����(Matrix)
�����(Matrix)
4.4 ���Դ���
���Դ���
4.5 IO
IO
4.6 Matplotlib
Matplotlib