直接上代码
import requests
from bs4 import BeautifulSoup
import urllib
import urllib.request
def cbk(a, b, c):
'''''回调函数
@a:已经下载的数据块
@b:数据块的大小
@c:远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100:
per = 100
print('%.2f%%' % per)
print(" ")
url = 'https://www.ivsky.com/tupian/dumogu_t28446/' # 取一个图片目录 有毒蘑菇
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.3427.400 QQBrowser/9.6.12513.400',
'Referer': 'http://www.ivsky.com/tupian/qita/index_11.html'}
html = requests.get(url, headers=headers, timeout=800) # 获取网页内容
soup = BeautifulSoup(html.text, 'html.parser')
def spidertupian():
for i in range(1, 11):
link = url + '/index_' + str(i) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.3427.400 QQBrowser/9.6.12513.400',
'Referer': 'http://www.ivsky.com/tupian/qita/index_11.html'}
html = requests.get(link, headers=headers)
mess = BeautifulSoup(html.text, 'html.parser')
# 查找标签为'ul', class属性为'pli'的标签元素,因为class是python的关键字,所以这里需要加个下划线'_'
for page in mess.find_all('ul', class_='pli'):
x = 0
for img in page.find_all('img'): # 文件夹的url
# print(img)
imgurl = img.get('src') # 获取src字段
save_path = "E:/the_data/mogo/" + str(i) + "_" + str(x) + ".jpg" # 拼接图片保存路径
imghttp = 'https:' + imgurl # 拼按图片的url路径
urllib.request.urlretrieve(imghttp, save_path, cbk)
x = x + 1
if __name__ == '__main__':
spidertupian()
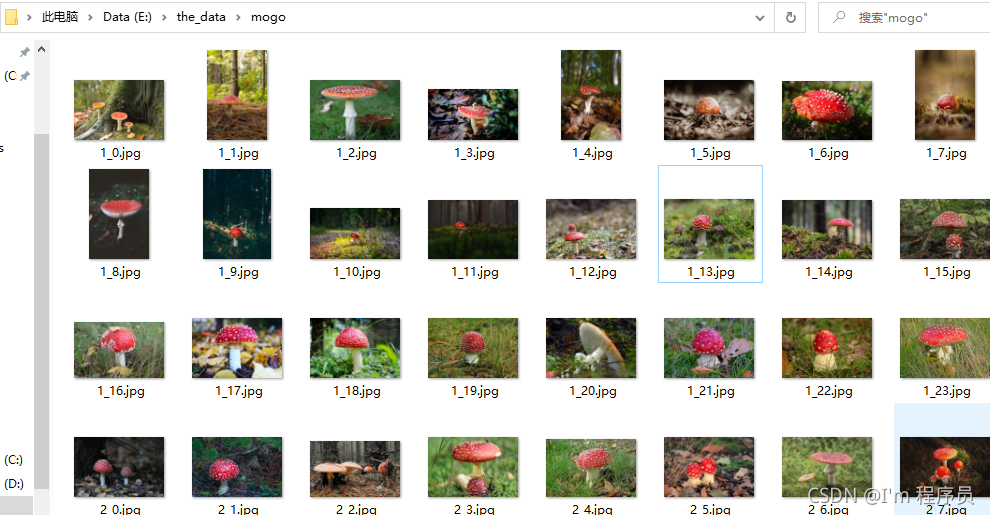
效果展示:
补充:
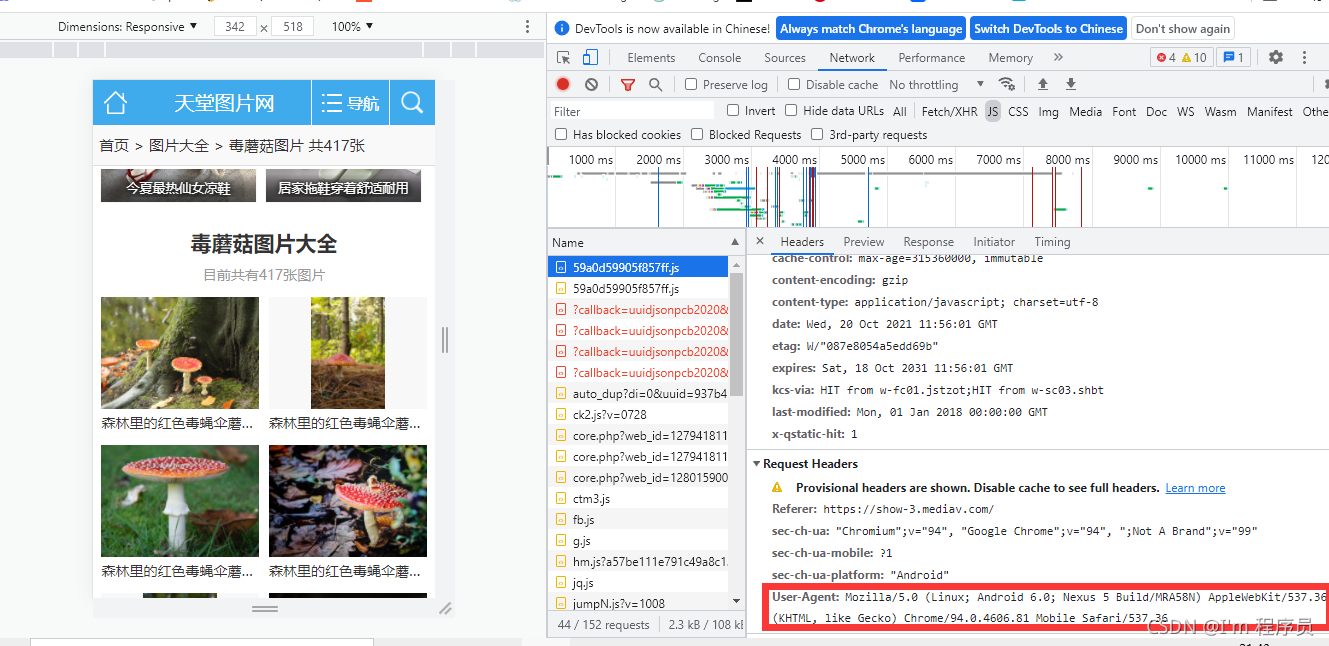
1:headers
2:x = x + 1
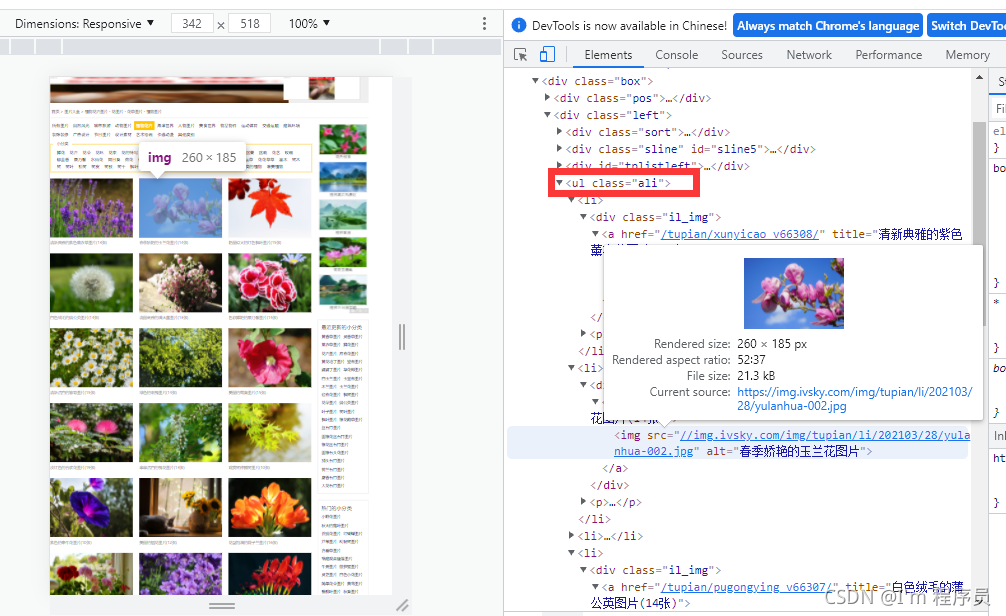
3:寻找需要爬的对象
比如植物花蕊(爬完有毒蘑菇打开开发者工具有些信息就变了,所以以植物花蕊为例找吧)
欢迎来玩爬虫哦