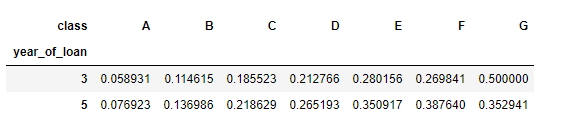
用Python里的Pandas可以实现,虽然感觉Excel更方便
1.groupby + agg
不够直观,不好看
对贷款年份,贷款种类创建数据透视
train_data.groupby(['year_of_loan', 'class']).agg(d_roat =('isDefault', 'mean'))
2. crosstab
pandas.crosstab(index, columns,values, rownames=None, colnames,
aggfunc, margins, margins_name, dropna, normalize)
主要用到的参数:
index:选哪个变量做数据透视表的行
columns:选哪个变量做数据透视表的列
values:要聚合的值
aggfunc:使用的聚合函数
margins:是否添加汇总列/行
margins_name:汇总行/列的名字
例子
对贷款年份,贷款种类创建数据透视
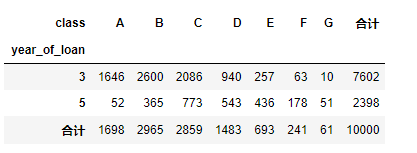
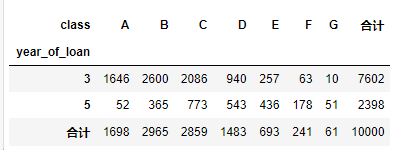
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['loan_id'], aggfunc='count',margins = True, margins_name = '合计')
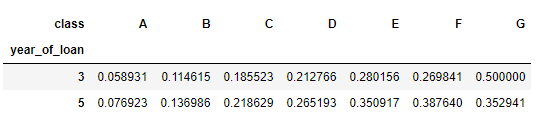
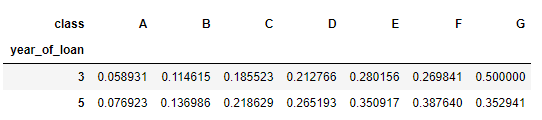
可以直接看出交叉组合之后违约比例
pd.crosstab(train_data['year_of_loan'], train_data['class'], train_data['isDefault'], aggfunc='mean')
3.groupby + pivot
train_data.groupby(['year_of_loan', 'class'], as_index = False)['isDefault'].mean().pivot('year_of_loan', 'class', 'isDefault')
pivot_table
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value,
margins, dropna, margins_name, observed, sort)
常用参数与crosstab一致
例子
实现同样的数据透视表
pd.pivot_table(train_data[['year_of_loan', 'class', 'isDefault']],
values='isDefault', index=['year_of_loan'], columns=['class'],
aggfunc='count', margins = True, margins_name = '合计')
pd.pivot_table(train_data[['year_of_loan', 'class', 'isDefault']],
values='isDefault', index=['year_of_loan'], columns=['class'],
aggfunc='mean')