Ŀ¼
ѧϰ�ʼ�
һ���������ʽ�CԪ�ַ�
re ģ��ʹ Python ����ӵ��ȫ�����������ʽ����

1. ������
# ��ȡ��Сд��ĸ��ϵĵ���
import re
a = 'Excel 12345Word23456PPT12Lr'
r = re.findall('[a-zA-Z]{3,5}',a)
# ��ȡ��ĸ������3����5��
print(r)
# ['Excel', 'Word', 'PPT']
# ̰�� �� ��̰�� ��PythonĬ��ʹ��̰��ģʽ��
# ̰��:'[a-zA-Z]{3,5}'
# ��̰��:'[a-zA-Z]{3,5}?' �� '[a-zA-Z]{3}'
# ����ʹ�ú���,��Ҫʹ��?��,��������������?�Ż���
# ƥ��0�λ������ *��,*��ǰ����ַ�����0�λ�����
import re
a = 'exce0excell3excel3'
r = re.findall('excel*',a)
r = re.findall('excel.*',a) # ['excell3excel3']
# excel û��l �кܶ�l������ƥ�����
print(r)
# ['exce', 'excell', 'excel']
# ƥ��1�λ�������� +��,+��ǰ����ַ����ٳ���1��
import re
a = 'exce0excell3excel3'
r = re.findall('excel+',a)
print(r)
# ['excell', 'excel']
# ƥ��0�λ�1�� ?��,?�ž�������ȥ�ظ�
import re
a = 'exce0excell3excel3'
r = re.findall('excel?',a)
print(r)
# ['exce', 'excel', 'excel']
2. �ַ�ƥ��

line = 'xyz,xcz.xfc.xdz,xaz,xez,xec'
r = re.findall('x[de]z', line)
# pattern ��x��ʼ,z����,��d��e
print(r)
# ['xdz', 'xez']
r = re.findall('x[^de]z', line)
# pattern ��x��ʼ,z����,���Ǻ�d��e
print(r)
# ['xyz', 'xcz', 'xaz']
# \w ������ȡ����,Ӣ��,���ֺ��»���,������ȡ�����ַ�
import re
a = 'Excel 12345Word\n23456_PPT12lr'
r = re.findall('\w',a)
print(r)
# ['E', 'x', 'c', 'e', 'l', '1', '2', '3', '4', '5', 'W', 'o', 'r', 'd', '2', '3', '4', '5', '6', '_', 'P', 'P', 'T', '1', '2', 'l', 'r']
# \W ��ȡ�����ַ�,�ո� \n \t
import re
a = 'Excel 12345Word\n23456_PPT12lr'
r = re.findall('\W',a)
print(r)
# [' ', '\n']
3. �߽�ƥ��
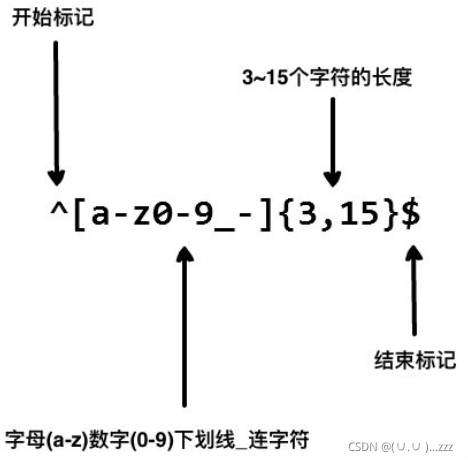
# ���Ƶ绰�����λ�ñ�����8-11λ������ȡ
import re
tel = '13811115888'
r = re.findall('^\d{8,11}$',tel)
print(r)
# ['13811115888']
4. ��
# ��abc���һ����,{2}ָ�����ظ�����,ƥ��abcabc
import re
a = 'abcabcabcxyzabcabcxyzabc'
r = re.findall('(abc){2}',a) # ��
# ['abc', 'abc']
print(r)
r = re.findall('(abc){3}',a)
# ['abc']
5. ƥ��ģʽ����

# findall�������� re.I���Դ�Сд
import re
a = 'abcFBIabcCIAabc'
r = re.findall('fbi',a,re.I)
print(r)
# ['FBI']
# ���ģʽ֮���� | ������һ��
import re
a = 'abcFBI\nabcCIAabc'
r = re.findall('fbi.{1}',a,re.I | re.S)
# ƥ��fbiȻ��ƥ������һ���ַ�����\n
print(r)
# ['FBI\n']
��������
re.findall
- ƥ����ַ��������� ���ƶ�ֵ��ص�ֵ
- ���б�����ʽ����
- δƥ���ؿ��б�
import re
re.findall(pattern, string, flags=0)
pattern.findall(string[ , pos[ , endpos]])
import re
line = "111aaabbb222���������"
r = re.findall('[0-9]',line)
print(r)
# ['1', '1', '1', '2', '2', '2']
re.match
- re.match ���Դ��ַ�������ʼλ��ƥ��һ��ģʽ
- ���������ʼλ��ƥ��ɹ��Ļ�,match()�ͷ���none��
re.match(pattern, string, flags=0)
# (��,Ҫƥ���,��־λ)
print(re.match('www','www.xxxx.com'))
print(re.match('www','www.xxxx.com').span())
print(re.match('com','www.xxxx.com'))
<re.Match object; span=(0, 3), match='www'>
(0, 3)
None
groupƥ�����
import re
a = 'life is short,i use python,i love python'
r = re.search('life(.*)python(.*)python',a)
print(r.group(0)) # ��������ƥ�� ,life is short,i use python,i love python
print(r.group(1)) # ��1������֮���ȡֵ is short,i use
print(r.group(2)) # ��2������֮���ȡֵ ,i love
print(r.group(0,1,2)) # ��Ԫ����ʽ����3�����ȡֵ ('life is short,i use python,i love python', ' is short,i use ', ',i love ')
print(r.groups()) # ���ؾ���group(1)��group(2) (' is short,i use ', ',i love ')
import re
# .* ��ʾ����ƥ������з�(\n��\r)֮����κε��������ַ�
# (.*?) ��ʾ"��̰��"ģʽ,ֻ�����һ��ƥ�䵽���Ӵ�
# re.M ����ƥ��,Ӱ�� ^ �� $
# re.I ʹƥ��Դ�Сд������
line = "Cats are smarter than dogs"
matchObj1 = re.match(r'(.*) are (.*?) .*', line, re.M|re.I)
matchObj2 = re.match(r'(.*) smarter (.*?) .*', line, re.M|re.I)
matchObj3 = re.match(r'(.*) than (.*)', line, re.M|re.I)
print(matchObj1)
print(matchObj2)
print(matchObj3)
# <re.Match object; span=(0, 26), match='Cats are smarter than dogs'>
# <re.Match object; span=(0, 26), match='Cats are smarter than dogs'>
# None
if matchObj1:
print ("matchObj1.group() : ", matchObj1.group())
print ("matchObj1.group(1) : ", matchObj1.group(1))
print ("matchObj1.group(2) : ", matchObj1.group(2))
else:
print ("No match!!")
if matchObj2:
print ("matchObj2.group() : ", matchObj2.group())
print ("matchObj2.group(1) : ", matchObj2.group(1))
print ("matchObj2.group(2) : ", matchObj2.group(2))
else:
print ("No match!!")
if matchObj3:
print ("matchObj3.group() : ", matchObj3.group())
print ("matchObj3.group(1) : ", matchObj3.group(1))
print ("matchObj3.group(2) : ", matchObj3.group(2))
else:
print ("No match!!")
# matchObj1.group() : Cats are smarter than dogs
# matchObj1.group(1) : Cats
# matchObj1.group(2) : smarter
# matchObj2.group() : Cats are smarter than dogs
# matchObj2.group(1) : Cats are
# matchObj2.group(2) : than
# matchObj3.group() : Cats are smarter than dogs
# matchObj3.group(1) : Cats are smarter
# matchObj3.group(2) : dogs
import re
# �� ��ƥ�䵥���ַ�
# ����ǰ��Ķ�������0�λ�������
# ���Ǿ��������ַ�����0�λ�������
str = "a b a b"
matchObj1 = re.match(r'a(.*)b', str, re.M|re.I)
matchObj2 = re.match(r'a(.*?)b', str, re.M|re.I)
print("matchObj1.group() : ", matchObj1.group())
print("matchObj2.group() : ", matchObj2.group())
# matchObj1.group() : a b a b
# matchObj2.group() : a b
re.search
ɨ�������ַ��������ص�һ���ɹ���ƥ�䡣
re.search(pattern, string, flags=0)
import re
line = "cats are smarter than dogs"
matchObj = re.match(r'dogs',line,re.M|re.I)
matchObj1= re.search(r'dogs',line,re.M|re.I)
matchObj2= re.match(r'(.*) dogs',line,re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
if matchObj1:
print ("match --> matchObj1.group() : ", matchObj1.group())
else:
print ("No match!!")
if matchObj2:
print ("match --> matchObj2.group() : ", matchObj2.group())
else:
print ("No match!!")
# No match!!
# match --> matchObj1.group() : dogs
# match --> matchObj2.group() : cats are smarter than dogs
re.compile
- re.compile�ǽ��������ʽת��Ϊģʽ����
- �������Ը���Ч��ƥ�䡣ʹ��compileת��һ��֮��,�Ժ�ÿ��ʹ��ģʽʱ�Ͳ��ý���ת��
�����������滻
re.sub �滻�ַ���
re.sub('���滻��','�滻�ɵ�',a)
# ��FBI�滻��BBQ
import re
a = 'abcFBIabcCIAabc'
r = re.sub('FBI','BBQ',a)
print(r)
# ��FBI�滻��BBQ,��4����д1,֤��ֻ�滻��һ��,Ĭ����0(�����滻)
import re
a = 'abcFBIabcFBIaFBICIAabc'
r = re.sub('FBI','BBQ',a,1)
print(r)
# abcBBQabcCIAabc
# abcBBQabcFBIaFBICIAabc
# �Ѻ�������������sub���б���,ʵ�ְ�ҵ������ȥ����,���罫FBI�滻��$FBI$
import re
a = 'abcFBIabcFBIaFBICIAabc'
def ������(�β�):
�ֶλ�ȡ = �β�.group() # group()���������ʽ�����ڻ�ȡ�ֶνػ���ַ���,��ȡ��FBI
return '$' + �ֶλ�ȡ + '$'
r = re.sub('FBI',������,a)
print(r)