ǰ��:���������,���Dz���Ҫ������ҳ������,ֻ��Ҫ���ֵ�����,����������Ҫ����ȡ�������ݽ�����
һ��re����
RegularExpression-----�������ʽ,��һ��ʹ�ñ���ʽ�ķ�ʽ���ַ�������ƥ���������ŵ����ٶȿ졢Ч�ʸߡ�ȷ�Ը�,ȱ�������������ѡ�
1.�������ʽ�
Ԫ�ַ�:

?����:����ǰ��Ԫ�ַ����ֵĴ�����

?̰��ƥ��Ͷ���ƥ��:

2.�������ʽ��python�е�ʵ��
- findall():��������,����list��
import re
lst = re.findall("\d+", "����6��,������15000m")
print(lst)#['6', '15000']- search():�����ƥ��,�������ƥ�䵽�˵�һ�����,�ͻ᷵��������,���ƥ�䲻������None��
import re
lst = re.search("\d+", "����6��,������15000m").group()
print(lst)#6- match():ֻ�ܴ��ַ����Ŀ�ͷ����ƥ�䡣
import re
lst = re.match("\d+", "����6��,������15000m").group()
print(lst)#����- finditer():��findall���,ֻ���������ص��ǵ�������
import re
lst = re.finditer("\d+", "����6��,������15000m")
for i in lst:
print(i.group())- compile():Ԥ�����������ʽ��
import re
obj = re.compile("\d+")
lst = obj.findall("����6��,������15000m")
print(lst)#['6', '15000']- re.S:��Ԫ�ַ�"."ƥ�任�з���
- (?P<����>):Ϊ�������ʽ����,����grop("����")�����������Ϊ�������ı���ʽ��
������������
1.��ȡ�������а�����?
������Ҫ���������ݨ�����

import re
import requests
import csv
page = input("������ҳ��(0=1,25=2,50=3...):")
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"
}
url = f"https://movie.douban.com/top250?start={page}&filter="
# ��ȡҳ��Դ����
res = requests.get(url=url,headers=header)
res_text = res.text
#��������
obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<br>(?P<year>.*?) '
r'.*?<span class="rating_num" property="v:average">(?P<score>.*?)</span>'
r'.*?<span>(?P<views>.*?)������',re.S)
result = obj.finditer(res_text)
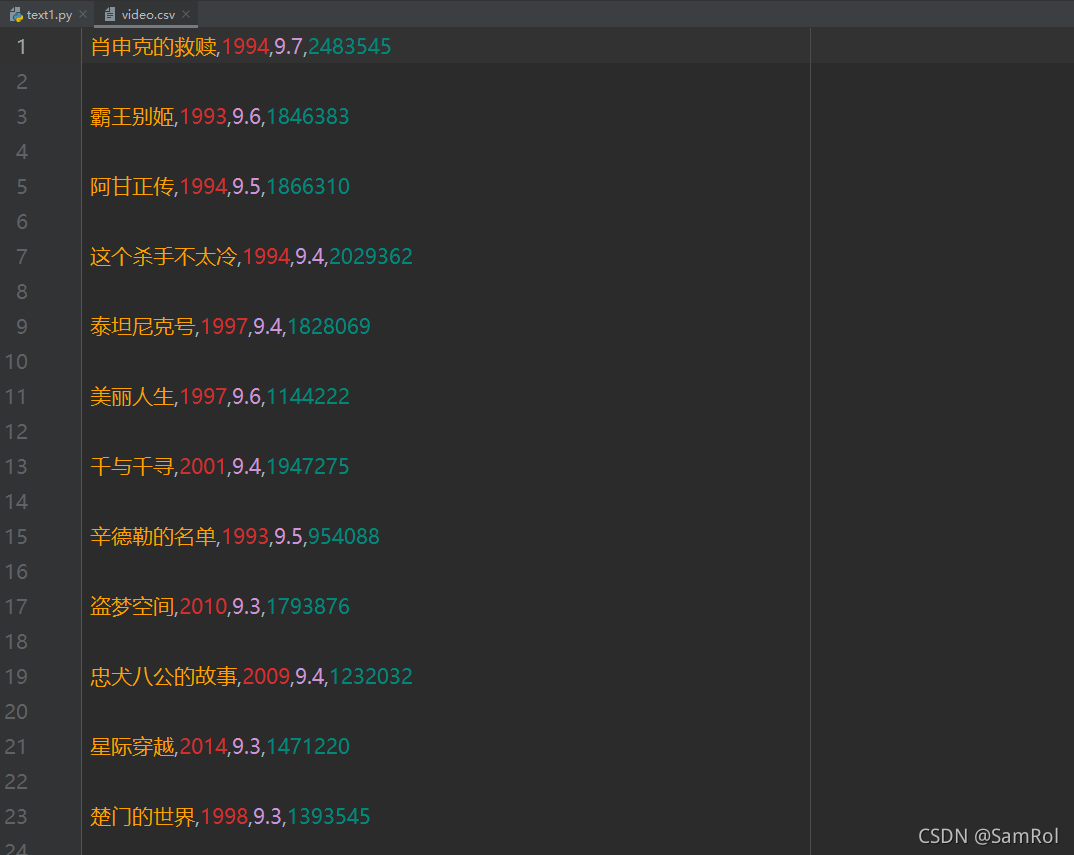
#��csv�ļ�
f = open("video.csv", mode="w")
#����д�����ݶ���
csvwiter = csv.writer(f)
for i in result:
dic = i.groupdict()
dic['year'] = dic['year'].strip()#Ϊyear�������������ո�
csvwiter.writerow(dic.values())#д������Ϊdic�������
#print(i.group("name"))
#print(i.group("year").strip())#�����ո�
#print(i.group("score"))��
#print(i.group("views"))
f.close()
print("done!")
��: