一、网络爬虫
网络爬虫(web crawler), 以前经常称为网络蜘蛛(spider), 是按照一定的规则自动浏览万维网并获取信息的机器人程序(或叫脚本), 曾经被广泛的应用于互联网搜索引擎. 使用过互联网和浏览器的人都知道, 网页中除了提供用户阅读的文字信息之外, 还包含一些超链接. 网络爬虫系统正是通过网页中的超链接信息不断获得网络上的其他页面. 正因为如此, 网络数据采集的过程就像一个爬虫或者蜘蛛在网络上漫游, 所有才被形象的称之为网络爬虫或者网络蜘蛛。
爬虫原理
- 通用网络爬虫的实现原理及过程:
获取初始的URL。初始的URL地址可以由用户人为地指定,也可以由用户指定的某个或某几个初始爬取网页决定。
根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,首先需要爬取对应URL地址中的网页,爬取了对应的URL地址中的网页后,将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,同时将已爬取的URL地址存放到一个URL列表中,用于去重及判断爬取的进程。
将新的URL放到URL队列中。在第2步中,获取了下一个新的URL地址之后,会将新的URL地址放到URL队列中。
从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新网页中获取新URL,并重复上述的爬取过程。
满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件。如果没有设置停止条件,爬虫则会一直爬取下去,一直到无法获取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。 - 爬虫可以使用C++,Java,但python做爬虫的优势是:速度快、库多、效率高!
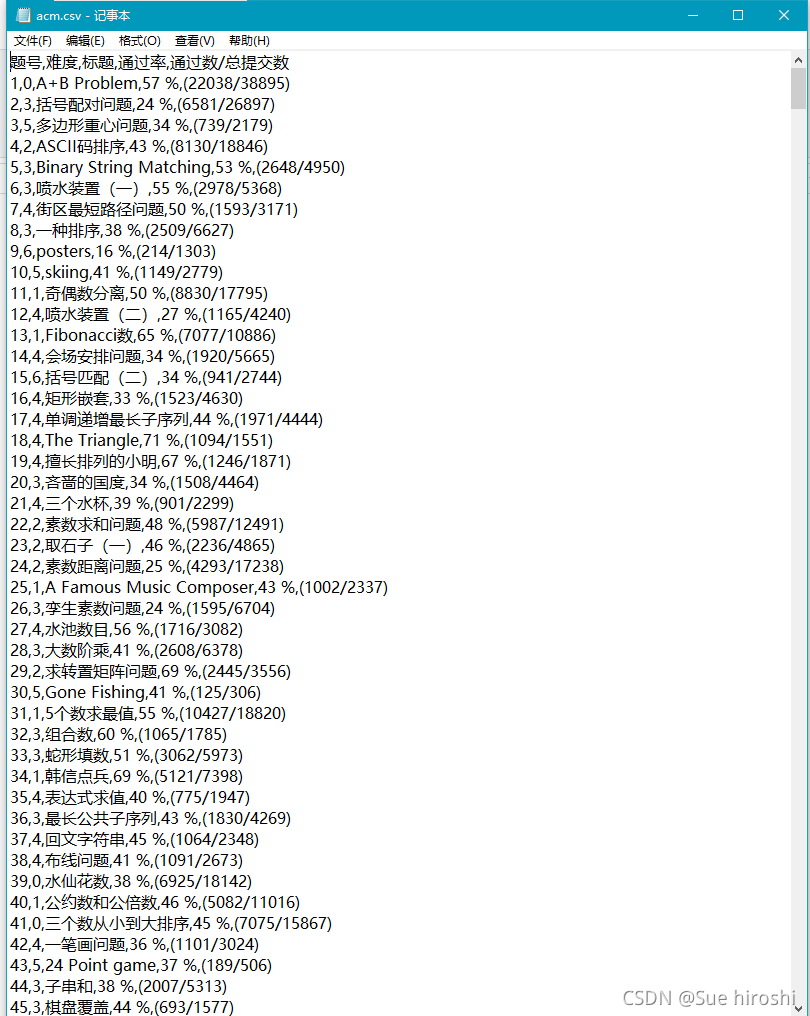
二、爬取ACM题目网站
代码
import requests
from bs4 import BeautifulSoup
import csv
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
subjects = []
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
r.raise_for_status()
r.encoding = 'utf-8'
soup = BeautifulSoup(r.text, 'html5lib')
td = soup.find_all('td')#讲所有含TD的项提取出来
subject = []
for t in td:
if t.string is not None:
#利用string方法获取其中的内容
subject.append(t.string)
if len(subject) == 5:
subjects.append(subject)
subject = []
with open('D:/Myworkspace/acm.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders)
fileWriter.writerows(subjects)
爬取成功!
三、爬取重庆交通大学新闻网站中近几年所有的信息通知
- 在元素界面找到时间time,标题righttitle
代码
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'
}
#csv的表头
cqjtu_head=["日期","标题"]
#存放内容
cqjtu_infomation=[]
#获取新闻标题和时间
def get_time_and_title(page_num,Headers):#页数,请求头
if page_num==66 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#根据class来选择
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html.parser')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#清除空格
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
# 爬取题目
print('新闻信息爬取中:\n')
for pages in tqdm(range(66, 0,-1)):
get_time_and_title(pages,Headers)
# 存放题目
with open('D:/Myworkspace/cqjtu.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_infomation)
print('\n新闻信息爬取完成!!!')

总结
- 爬虫是一个比较容易上手的技术,在这次作业中我对爬虫也有了个初步的了解。