相信很多小伙伴对爬虫很感兴趣,遇到网上有用的信息,总想把他们批量保存下来。如果都手工的去复制粘贴,费时间费精力,而且还不符合程序员的作风。所以这时候写一个小爬虫,晚上睡觉时让他勤劳的给我们打工干活就好了。
不过一提到爬虫,就避不开 Python。只要一搜爬虫入门教程,满篇都是教你如何使用 Python 爬虫。
诚然,Python 简单、高效、易用以及丰富的库与爬虫框架,是新手在入门爬虫时的最佳选择。但是我们 Java 开发者就不配用 Java 写爬虫了吗?我就是想在工作之余简单的爬取一批页面,想使用熟悉的语言快速实现这个小功能,你还得让我去学个 Python?
作为一名爱撸码的老程序员,自然是认可多掌握些语言和技术,把路走宽这个道理的。但是如果自己熟悉的语言有一个好上手,开箱即用的爬虫框架,一解燃眉之急,是不是就可以在短时间内高效的完成自己的目标呢?
那么就分享给广大Java程序员一个好用的爬虫框架,Jsoup。
快速入门
1.引入依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version> <!-- or latest version -->
</dependency>
2.一行代码返回页面
只需要一行代码即可对一个链接发起请求,返回页面数据。
Document document = Jsoup.connect(url).get;
好了,你已经掌握了 Jsoup 的使用方式,这篇文章就这里了,我们下期再见……
开个玩笑哈,确实,使用 Jsoup 请求一个页面,就是这么简单。但是我们还要对页面信息进行解析,从一个复杂的 HTML 文档中找到我们要信息。先来简单的介绍一下 Jsoup 常见的类以及 api,方便后续的介绍。
常见类与api
1.常见的类
Jsoup 常见的几个类,都是对应 HTML DOM 中的概念。通过对以下几个类的操作,就可以从一个 HTML 页面获取自己想要的数据啦。
-
Document 类,对应 HTML DOM Document 对象
-
Element 类,对应 HTML 的 DOM 元素,比如 <p>、<div>、<a> 等
-
Attribute,对应 HTML 中的属性,比如一个 div 元素里的 class、id 等
2.常用api
首先,介绍一下获取 DOM 元素的 api,都是属于 Element 类中定义的方法。
-
getElementById(String id):通过 id 获取元素,非常精准。
-
getElementsByTag(String tag):根据标签名获取元素的集合,比如:
document.getElementsByTag("p")
会获取到所有 <p> 标签的元素,方便我们进一步从中抓取想要的文本。
-
getElementsByClass(String className):根据 class 名称获取元素的集合,比如:
document.getElementsByClass("item")
会获取所有 class 为 item 的元素。一般页面的列表项会指定相同的 class,所以这个方法方便我们直接获取指定的列表内容。
-
getElementsByAttribute(String key):根据属性名称获取元素的集合,比如:
document.getElementsByAttribute("href")
这样我们就可以获取全部有链接属性的元素,方便去跳转爬取该页面涉及到的其他页面。
获取到 DOM 元素之后,我们还需要获取这个元素的属性、文本等数据,如下:
-
attr(String key):获取元素中某属性的值。比如:element.attr("class"),可以获取当前元素 class 属性的值。
-
attributes:获取元素的所有属性。我们可以对全部属性进行遍历或者其他处理。
-
id、className 、classNames:获取元素的 id 值、class 值以及全部 class 值的集合。这几个方法的底层都是 attr(String key) 方法,实际上是方便我们使用的快速实现。
-
text:获取元素的全部文本内容。我们不用手动遍历当前元素的所有子节点去获取文本信息,这个方法会直接把所有文本拼接到一起并返回。
举个例子
好了,说了这么多,是时候实战一波了。我们以爬虫入门经典案例,豆瓣电影 Top250 页面为例,来看看 Jsoup 具体是怎么使用的。
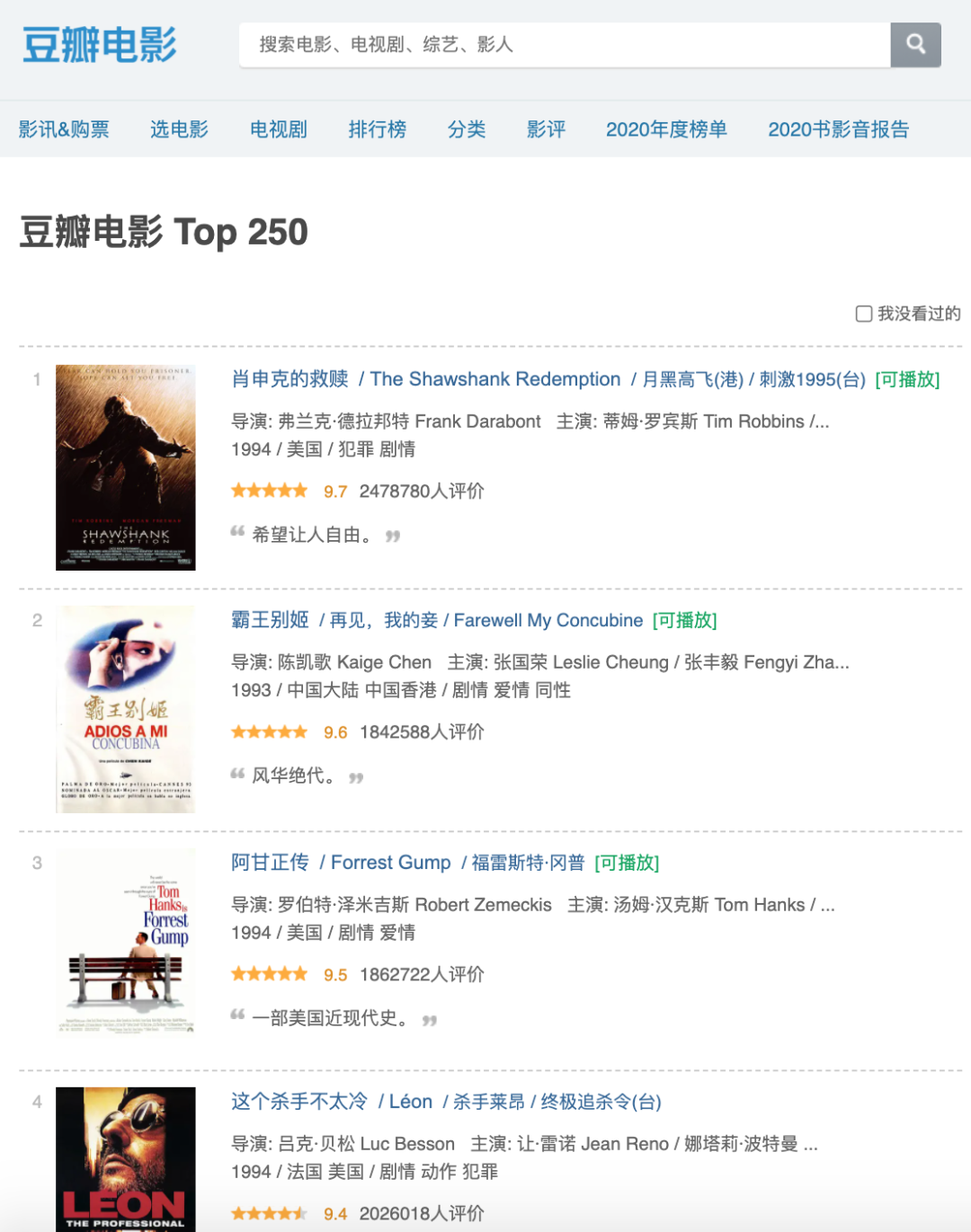
因为只是个示例,所以我们的目标简单一些,爬取这一页电影名称即可。
首先,我们直接 F12 看一下页面的源码,会发现影片名称是一个 class 为 title 的标签,如图:
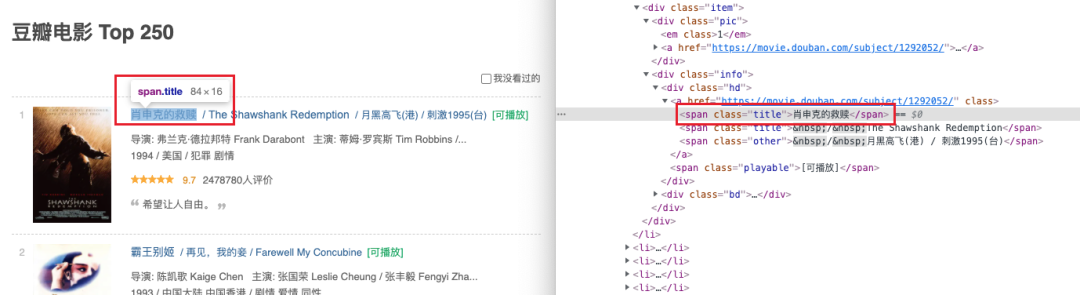
而电影的名称有多个,其他的名称会用 / 符号来分割。所以思路来了,只要我们获取到这个页面所有 class 值为 title 的元素,过滤掉带有 / 的文本,就可以啦。代码如下:
public static void printMovieName throws IOException {
// 豆瓣电影Top250
String url = "https://movie.douban.com/top250";
// 获取页面
Document document = Jsoup.connect(url).get;
// 根据class获取元素集合
Elements titles = document.getElementsByClass("title");
int index = 1;
for (Element title : titles) {
String text = title.text;
// 过滤掉电影的其他名称
if (!text.contains("/")) {
System.out.println("No." + index + " " + text);
index++;
}
}
}
输出结果如下:

总结
怎么样,用 Jsoup 写爬虫是不是非常的简单?当然,在这个简单的例子的基础上,我们可以实现更复杂的逻辑,比如:
-
获取分页链接继续爬取后续页面的内容;
-
爬取影片的完整信息,并保存到数据库中;
-
将影片的图片保存到本地或者上传到图床。
这些逻辑对于一个熟练掌握 Java 语言的程序员来说,都是很容易实现的事情。这也是为什么,我认为 Java 程序员使用自己的本职语言来开发爬虫,效率会更高一些。因为日常的搬砖操作可以让我们更熟练的处理爬取到的数据。爬虫只是获取数据的一个方式,对于数据的处理和使用也是非常重要的一部分。
温馨提示:我们要合法使用爬虫哦。通过网站域名 +robots.txt 来查看爬虫协议,判断是否可以使用爬虫爬取信息,比如:
https://www.douban.com/robots.txt。同时,切记不要爬取敏感信息,并进行牟利!
自己总结的Python学习笔记,自认为只学习不实践永远是一块废铁!学习与实践相结合才是最强!纯学习容易忘记知识点与主要内容,学习与动手实践相结合可以巩固你的知识点!你通过Python学习笔记与70个Python项目结合好好学习就可以!
学习笔记:





70个Python项目:


?问君能有几多愁,开源项目解千愁,我们下期再见!