思路&代码参考微信公众号:Python与Excel之交?,作者小刀
以美食节目《人生一串》为例
网页:人生一串-纪录片-全集-高清独家在线观看-bilibili-哔哩哔哩
弹幕
进入浏览器的开发者模式
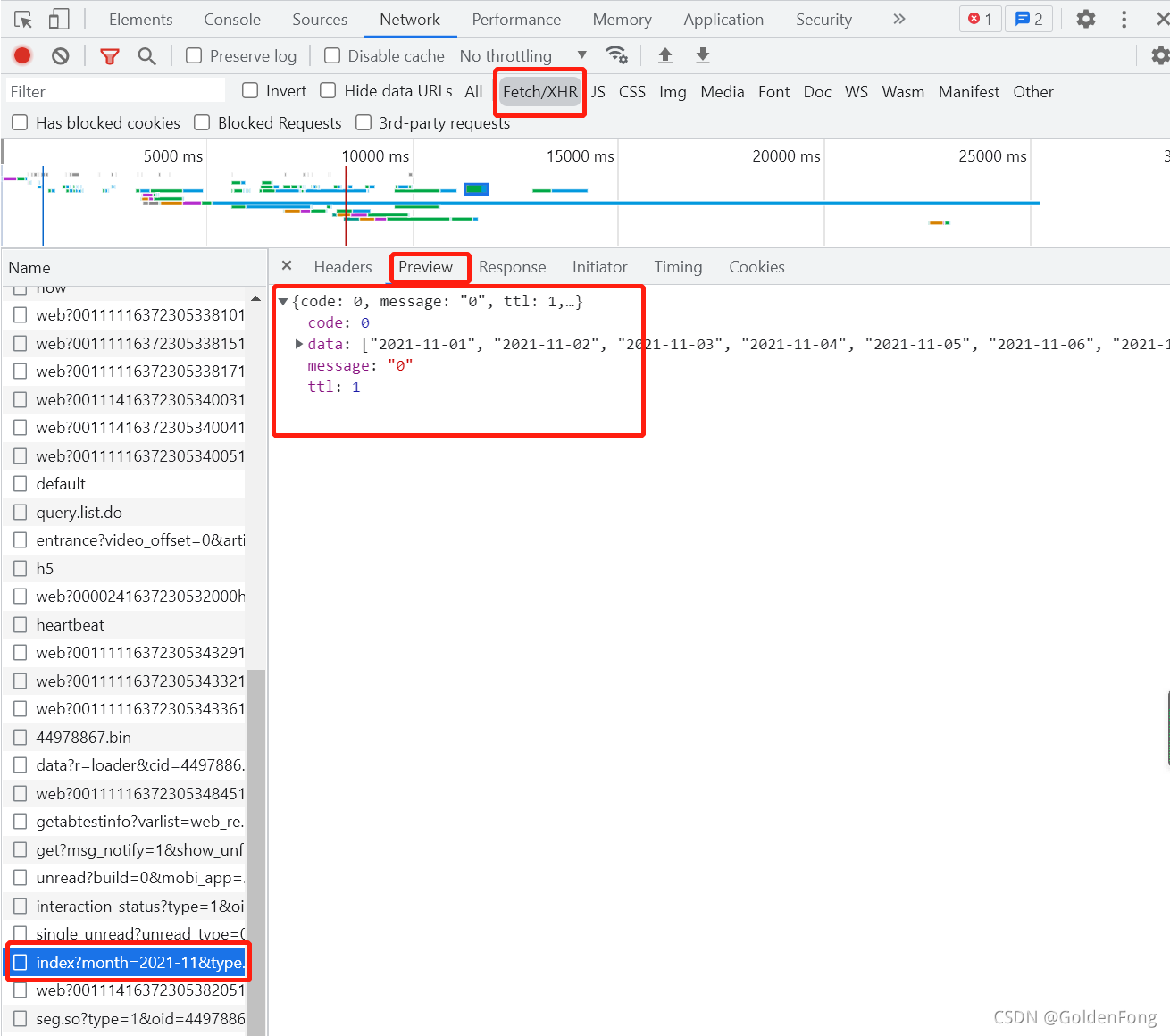
?B站的弹幕,需要点击右边弹幕的展开,如果要查看更多的弹幕,需要登录,然后点击查看历史弹幕
url:由month选择弹幕的月份,内容里的data包含有弹幕的具体日期,oid是每部视频的各自id
https://api.bilibili.com/x/v2/dm/history/index?month=2021-11&type=1&oid=44978867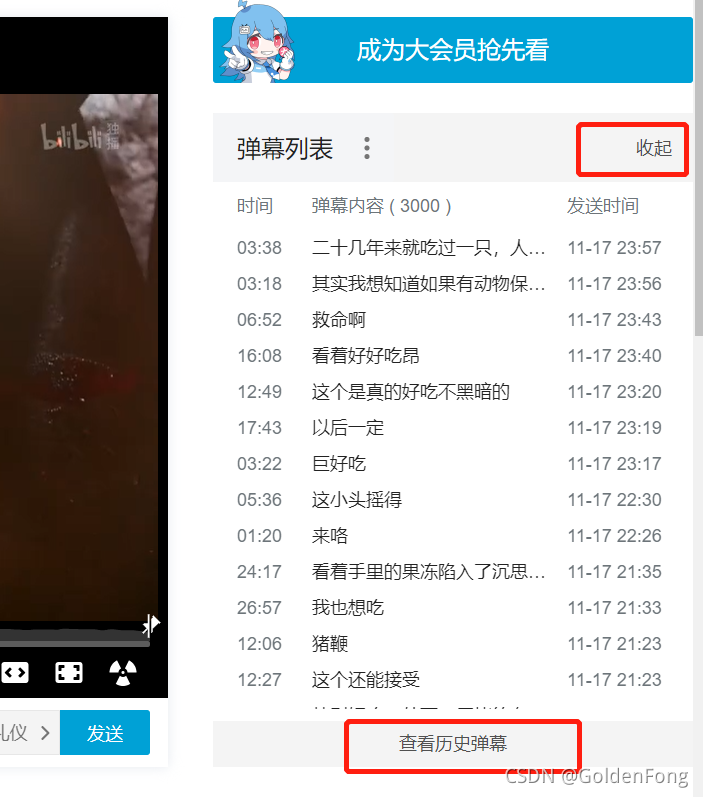
装弹幕的数据包
url是另外一个,由oid和date构成
https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=44978867&date=2021-11-17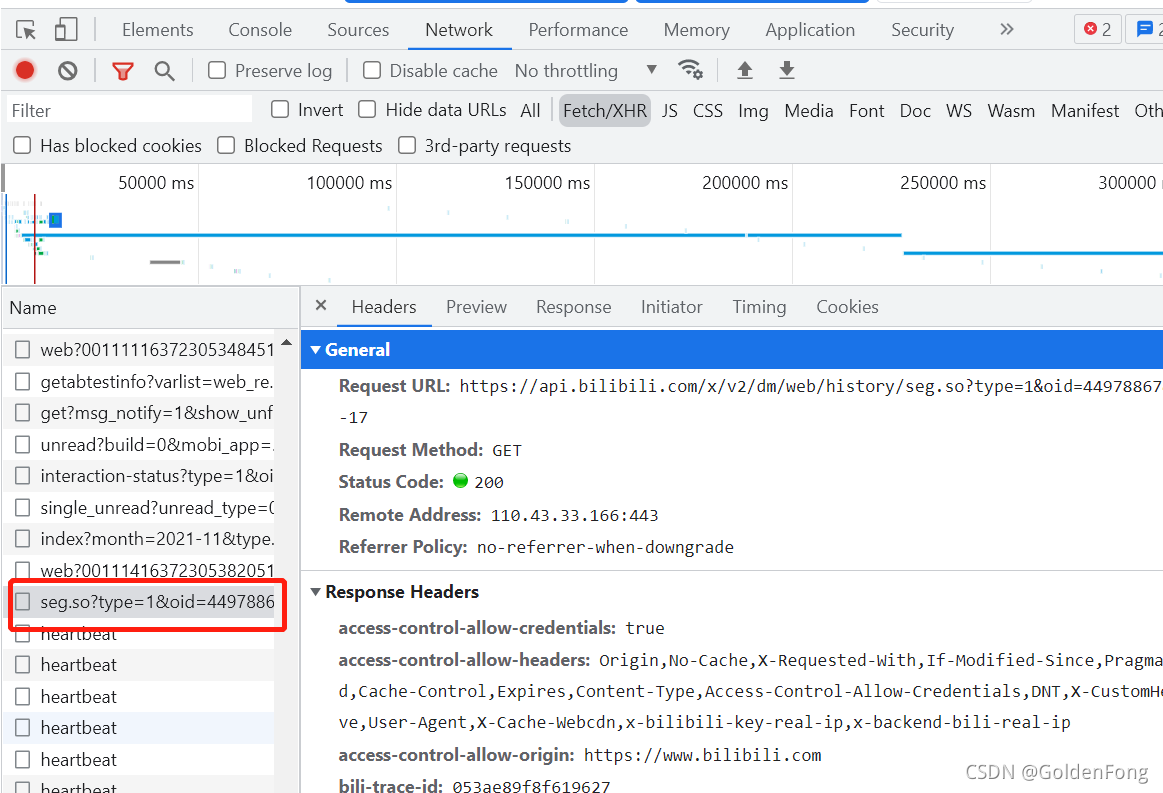
?代码
import requests
import pandas as pd
import re
def data_resposen(url):
headers = {
"cookie": "用自己的",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"
}
resposen = requests.get(url,headers=headers)
return resposen
def main(oid,month):
df = pd.DataFrame()
url = f'https://api.bilibili.com/x/v2/dm/history/index?month={month}&type=1&oid={oid}'
list_data = data_resposen(url).json()['data']
print(list_data)
for data in list_data:
urls = f'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid={oid}&date={data}'
text = re.findall(".*?([\u4E00-\u9FA5]+).*?", data_resposen(urls).text)#正则表达式,转码获取乱码的弹幕
for e in text:
print(e)
data = pd.DataFrame({'弹幕':[e]})
df = pd.concat([df,data])
if __name__ == '__main__':
oid = '44978715' #视频id
month = '2021-11' #开始日期
main(oid,month)

评论
评论在页面最下面,继续向下拉可以加载下一页
 真实的url
真实的url
https://api.bilibili.com/x/v2/reply/main?callback=jQuery172007192903829946484_1637231235333&jsonp=jsonp&next=0&type=1&oid=25246609&mode=3&plat=1&_=1637231283292
https://api.bilibili.com/x/v2/reply/main?callback=jQuery172007192903829946484_1637231235334&jsonp=jsonp&next=2&type=1&oid=25246609&mode=3&plat=1&_=1637231404391
https://api.bilibili.com/x/v2/reply/main?callback=jQuery172007192903829946484_1637231235335&jsonp=jsonp&next=3&type=1&oid=25246609&mode=3&plat=1&_=1637231422984可以看到只有next是代表页面从0开始固定的,第二页就是2 然后3
callback和最后的&_=都可以删除
代码
import requests
import pandas as pd
df = pd.DataFrame()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'
}
a = 1
while a < 4:#需要爬取多少
if a == 1:
url = f'https://api.bilibili.com/x/v2/reply/main?&jsonp=jsonp&next=0&type=1&oid=25246609&mode=3&plat=1'
else:
url = f'https://api.bilibili.com/x/v2/reply/main?&jsonp=jsonp&next={a}&type=1&oid=25246609&mode=3&plat=1'
html = requests.get(url,headers=headers).json()
print(a)#看看爬到第几页
for i in html['data']['replies']:
uname = i['member']['uname'] # 用户名称
sex = i['member']['sex'] # 用户性别
mid = i['mid'] # 用户id
current_level = i['member']['level_info']['current_level'] # vip等级
message = i['content']['message'] # 用户评论
like = i['like'] # 评论点赞次数
ctime = i['ctime'] # 评论时间
data = pd.DataFrame({'用户名称': [uname], '用户性别': [sex], '用户id': [mid],
'vip等级': [current_level], '用户评论': [message], '评论点赞次数': [like],
'评论时间': [ctime]})
df = pd.concat([df,data])
a += 1