hello,大家好,我是小浪宝宝,一个想凭借自己双手活下去的00后,想把自己的思路详细的分享给大家,励志让看到我的分享的人,一看程序就懂。👏👏👏👏👏好了,话不多说,切入今天的主题。最近杨幂和陈伟霆主演的《斛珠夫人》正在热映,弹幕连连,最近呢,学了一些爬虫,就想着把爬虫知识用于实践,就将弹幕爬取了下来,又了解到Python可以将词做成特定的词云,想想都好玩,快来一起看看吧。
? 本次程序结果:?
? ? ? ? 爬取了 23176 条弹幕,并根据弹幕做成了词云。
?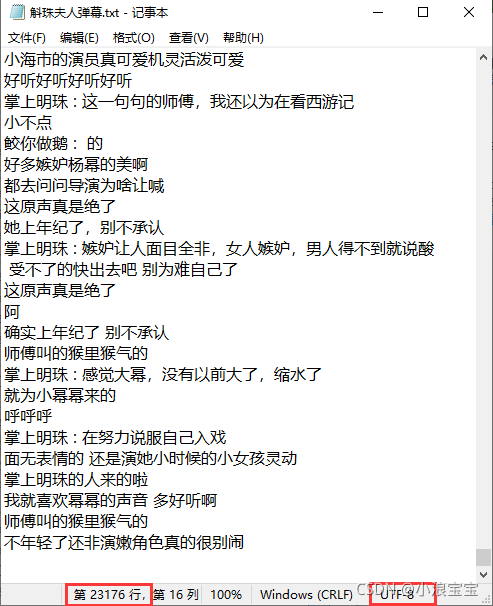

词云原图在这里:

目录
?????????爬虫爬取数据的过程不外乎数据获取、数据处理、数据保存,那我们分模块进行处理。本次分享程序主要在数据获取和数据处理。我会在文章末尾附上全部代码,不要着急,一步一步来。本次程序大致的框架如下:
import requests
class Spider:
# 初始化方法
def __init__(self):
self.session = requests.Session()
self.headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
'cookie': '填写你登录网页后的 cookie',
}
self.session.headers.update(self.headers)
# 获取数据方法
def get_data(self):
pass
# 处理数据方法
def process_data(self):
pass
# 保存数据方法
def save_data(self):
pass1.数据获取
import requests # 导入request库
import time # 导入time库
import json # 导入json库
from wordcloud import WordCloud # 从wordcloud库中导入WordCloud方法
import jieba # 导入jieba库
from PIL import Image # 从PIL库中导入Image方法
import numpy as np #导入numpy库,并将名称简写为np(写成其他简写也可,例如abc,只要方便使用即可)
?1.1.导入的库的作用
| requests库 | requests库是爬虫最常用的对网址发起请求的第三方库 |
| time库 | 本程序主要用来进行延时,防止爬取请求过快被封禁 |
| json库 | 本程序主要用来将json格式数据转换成Python中的字典或者列表类型数据 |
| wrodcloud库中的WordCloud方法 | 本程序主要用来生成特定形状的词云 |
| jieba库 | 本程序主要用于将中文句子分成词的形式 |
| PIL库中的Image方法 | PIL是Python Imaging Library的简称,具有强大的图像处理功能,本程序主要用于图像的读取 |
| numpy库 | 本程序主要用来将图像像素点转换成矩阵,作为词云特定形状的遮罩 |
?1.2.__init__方法
......省略库的导入
class ChatSpider:
def __init__(self):
self.session = requests.Session()
# 自定义的请求头数据
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0',
'referer': 'https://v.qq.com/x/cover/mzc00200prv7r23/q0041j617a8.html?ptag=sogou.tv.free',
'cookie': '你腾讯视频登录后cookie'
}
# 设置 session 的全局 headers
self.session.headers.update(self.headers)? ? ? ? __init__()? 方法在之前的文章已经说过了,它是类的初始化方法,在类的实例过程中都会被执行一次。本程序中主要用来,保持 cookie 传递给后续的请求,让登录状态在多个请求之间共享。cookie 就好比是自己QQ密码,千万要保护好!,并且设置全局的请求头数据。使用 user-agent 将爬虫伪装成浏览器,user-agent 里包含了操作系统、浏览器类型、版本等信息。使用 referer 使我们假装由腾讯视频网页发起的请求,在爬取数据的过程中,还可以加其他的信息。
1.2.1.获取 cookie 、referer 、use-agent 数据?
? ? ? ? 1)打开网页版腾讯视频,并搜索《斛珠夫人》,登录自己的腾讯视频账号,并随便点开一集视频;
? ? ? ? 2)打开 开发者工具 ,点击“清除按钮”并刷新网页;
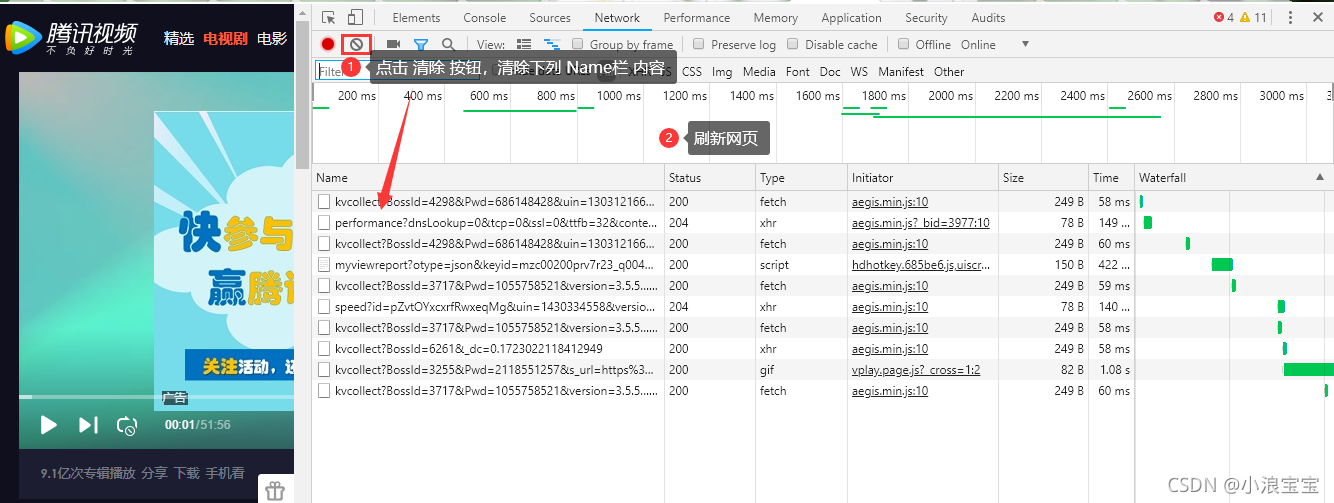
? ? ? ? ?3)点击第一个 Name标签, 复制 cookie 、referer 、user-agent 数据。(上面已经提到了 cookie 的重要性,小浪就不显示了,防止被高高手利用😭);
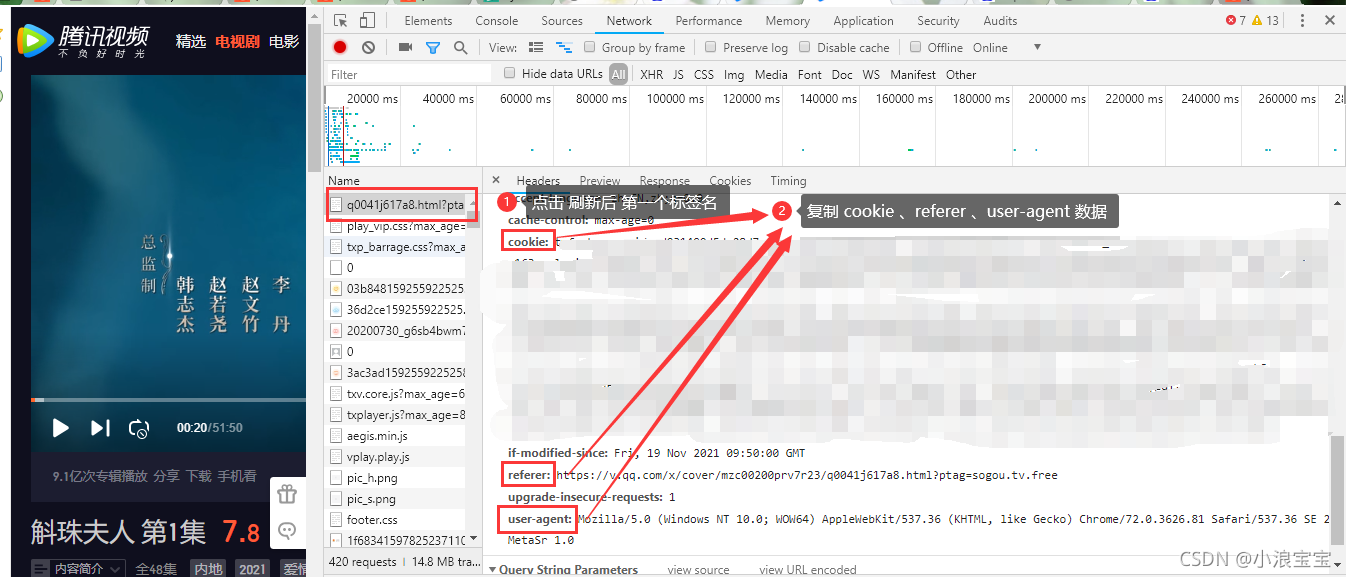
?1.3. get_data 方法
......省略库的导入
class ChatSpider:
......省略 __init() 方法
def get_data(self):
self.data = [] # 创建空列表,用于保存数据
for i in range(15,3015,30): # 使用for循环得到每一个完整的请求地址,i 传入 timestamp 参数
params ={
"otype":"json",
"target_id":"7520582071&vid=q0041j617a8",
"session_key":"0,388,1637139885",
"timestamp":str(i),
"_": "1637139884109"
}
req = self.session.get('https://mfm.video.qq.com/danmu', params = params)
req_josn = json.loads(req.text) # 识别出字符串中的 json 格式
for i in req_josn['comments']: # 分析 josn格式 的数据,找到弹幕在字典中>comments 中> content
print(i['content']) # 打印出弹幕内容
self.data.append(i['content']) #将弹幕添加到列表中
time.sleep(10) # 延时一段时间,防止爬取过快被封禁? ? ? ? get_data 方法主要用于获取数据,首先我们要找到请求网页的地址是多少。步骤如下:
? ? ? ? 1)打开 “开发者工具”,让视频播一会,然后随便搜索 弹幕中 的一句话 ――> 根据搜索结果,找到 Name栏 中对应得便签,并点击 ――> 复制要请求的网址(URL),并分析;
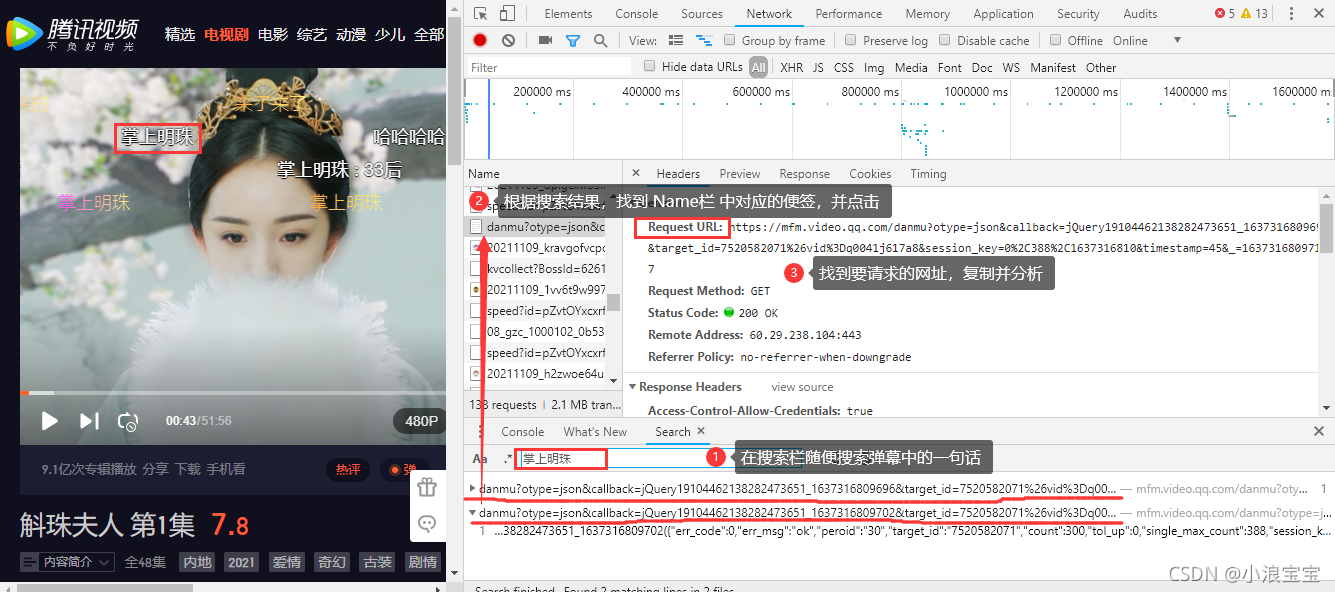
????????2)对比上面两个请求网页地址,发现只有 timestamp 和 _ 后的内容不同。timestamp 是页数,第一个网址是15,后面每30秒更新一次地址。_ 为时间戳,用于标识何时发生特定事件,通常给出日期和时间。网址?https://mfm.video.qq.com/danmu??问号后为查询字符串,在对比的过程中,可通过 string-to-json 网址把一整串请求地址转换成下列格式,方便对比;
{
? "https://mfm.video.qq.com/danmu?otype":"json",
? "callback":"jQuery19104462138282473651_1637316809696",
? "target_id":"7520582071&vid=q0041j617a8",
? "session_key":"0,388,1637317647",
? "timestamp":"75",
? "_":"1637316809719"
}
? ? ? ? 3)删除 callback 参数。你可能要问,为什么要删除 callback 参数,而不删除其他参数。 jQuery 是一个简洁而快速的JavaScript库,可用于简化事件处理,HTML文档遍历,Ajax交互和动画,以便快速开发网站。在预览要爬取的数据过程中,可以看到,在 json格式 数据外面套了一层JQuery 代码,为了方便我们直接获取其中 json格式 的数据,删除此参数即可。由于视频(以第一集为例)为51分56秒(3116秒),所以截取了前3015秒进行爬取弹幕。将剩下的查询字符串以字典的形式放在变量 params 里作为参数传入 session.get??,问号前面的直接放入 session.get??;
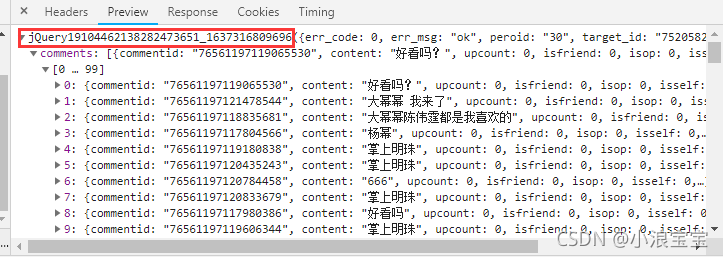
2.数据处理
......省略库的导入
class ChatSpider:
......省略 __init() 方法
......省略 get_data() 方法
......省略 process_data() 方法
def process_data(self):
pass? ? ? ? 在本次数据获取后,直接获取到了弹幕内容,并不需要对数据进行筛选。所以 process_data 方法中仅有 pass 语句表示空 。
3.数据保存
......省略库的导入
class ChatSpider:
......省略 __init() 方法
......省略 get_data() 方法
......省略 process_data() 方法
def save_data(self):
with open('斛珠夫人弹幕.txt', 'w', encoding='utf-8') as file: # 打开“斛珠夫人弹幕.txt”,如果没有就创建一个跟程序同目录的;
# ‘w’为写入;
# 编码形式为'utf-8',如果不添加编码形式,因为弹幕里有表情等形式,可能会出错
for i in self.data:
file.write(i+'\n') # 在保存数据的同时加上了换行符,方便查看弹幕? ? ? ? 在保存数据过程中,用到了 with 语句进行打开文件,并不需要我们手动编写代码关闭文件,执行完自动关闭文件。
4.制作词云
mask = np.array(Image.open('./杨幂/杨幂3纯色图.png')) # 打开图片,并将像素点转换成矩阵的形式,设置词云形状
with open('./斛珠夫人弹幕.txt','r',encoding='utf-8') as files: # 打开“斛珠夫人弹幕.txt”,如果没有就创建一个跟程序同目录的;
# ‘w’为写入;
# 编码形式为'utf-8',如果不添加编码形式,因为弹幕里有表情等形式,可能会出错
text = files.read() # 读取文件内容
print(text) # 打印文件内容
words = jieba.lcut(text) # 利用 jieba 库中的 lcut 方法,将文件内容分成词的形式,并返回列表
print(words) # 打印 句子 分成 词 后的列表
new_text = ' '.join(words) # 将词与词之间用 空格 连接连成一整个字符串
print(new_text) # 打印一整个字符串
word_cloud = WordCloud(font_path='msyh.ttc',\ # 添加字体路径
width=433,\ # 设置词云图片宽度
height=577,\ # 设置词云图片高度
max_words=10000,\ # 设置最大字体的大小
mask=mask,\ # 设置遮罩层,除白色外,其他都被词云覆盖
contour_width=3,\ # 设置词云轮廓宽度
contour_color='steelblue',\ # 设置词云轮廓颜色
background_color='white',\ # 设置词云背景颜色
).generate(text) # 根据文本内容生成词云
word_cloud.to_file('斛珠夫人弹幕词云.jpg') # 输出词云图片? ? ? ? ?你可能会问,Image.open?中,‘./’ 代表什么意思,'./' 在我的理解里,就是程序所在文件夹地址,我在程序所在文件夹里创建了一个“杨幂”的文件夹,并使用了其中的一张图片作为遮罩。在里做遮罩图片的时候,我其实并没有使用过 wordcloud?这个库,也是突发奇想,想做一个词云。在B站,看了教程视频,教程里讲,让我做一张透明图片,一直都不好用,做不成遮罩。又去查了很多资料,最后发现有人说是用纯白色图片,试了试,果然是。别人讲的不一定是对的,只有自己真正去做了才知道真假。如果你想一秒钟,抠出图片人物,私聊我,我教你!(点个赞呗,都看到这了,怪辛苦的)。
? ? ? ? 你可能还会问,WordCloud 里面的参数为什么是加了反斜杠 "\" 的。反斜杠,是说明这一句我们还没写完,想在下一行继续写,你会看到上面 WordCloud 里的参数都是上下对齐的(这是自动对齐的,不信你可以试试)。WordCloud? 中常用参数如下:
| font_path = "字体路径" | 词云的字体样式,若想输出中文,就要使用中文的字体 |
| width = n | 画布宽度,默认为400像素 |
| height = n | 画布高度,默认为400像素 |
| scale = n | 按比例放大或缩小画布 |
| min_font_size = n | 设置最小的字体大小 |
| max_font_size = n | 设置最大的字体大小 |
| stopwords = ‘words’ | 设置要屏蔽的词语 |
| background_color = 'color' | 设置背景板颜色,默认为黑色 |
| relative_scaling = n | 设置字体大小与词频的关联性 |
| contour_width = n????????? | 设置轮廓大小 |
| contour_color = 'color' | 设置轮廓颜色 |
| mask = mask | 遮罩层,除白色背景外,其余区域全部绘制词云 |
? ? ? ? 如果你没有合适的字体,请打开这个目录:C:\Windows\Fonts 这里都是 windows 自带的字体,你如果想用那个字体,复制到程序所在目录,切记不要剪切,剪切完 windows 就没字体用了!!!!。也可以不复制,在字体文件名前面加入地址就好了。
? ? ? ? 不知道你在执行代码的时候,发现了没有,爬取两万多条代码太费时间啦,我自己的电脑爬取了足足二十分钟(可能是我的电脑太落后了😅)!!。为了解决这个问题呢,当然还有其他的方法,比如多线程。多线程的事情,如果有需要欢迎留言或私聊我。多线程也就一两分钟的事。
? ? ? ? 看到最后了啊?嗯?点个赞呗,就说你呢!跟谁俩呢这是。👍👍👍👍👍
全部代码如下:
import requests # 导入request库
import time # 导入time库
import json # 导入json库
from wordcloud import WordCloud # 从wordcloud库中导入WordCloud方法
import jieba # 导入jieba库
from PIL import Image # 从PIL库中导入Image方法
import numpy as np #导入numpy库,并将名称简写为np(写成其他简写也可,例如abc,只要方便使用即可)
class ChatSpider:
def __init__(self):
self.session = requests.Session()
# 自定义的请求头数据
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0',
'referer': 'https://v.qq.com/x/cover/mzc00200prv7r23/q0041j617a8.html?ptag=sogou.tv.free',
'cookie': '你腾讯视频页面登录后的cookie'
}
# 设置 session 的全局 headers
self.session.headers.update(self.headers)
def get_data(self):
self.data = [] # 创建空列表,用于保存数据
for i in range(15,3015,30): # 使用for循环得到每一个完整的请求地址,i 传入 timestamp 参数
params ={
"otype":"json",
"target_id":"7520582071&vid=q0041j617a8",
"session_key":"0,388,1637139885",
"timestamp":str(i),
"_": "1637139884109"
}
req = self.session.get('https://mfm.video.qq.com/danmu', params = params)
req_josn = json.loads(req.text) # 识别出字符串中的 json 格式
for i in req_josn['comments']: # 分析 josn格式 的数据,找到弹幕在字典中>comments 中> content
print(i['content']) # 打印出弹幕内容
self.data.append(i['content']) #将弹幕添加到列表中
time.sleep(10) # 延时一段时间,防止爬取过快被封禁
def process_data(self):
pass # 空语句
def save_data(self):
with open('斛珠夫人弹幕.txt', 'w', encoding='utf-8') as file: # 打开“斛珠夫人弹幕.txt”,如果没有就创建一个跟程序同目录的;
# ‘w’为写入;
# 编码形式为'utf-8',如果不添加编码形式,因为弹幕里有表情等形式,可能会出错
for i in self.data:
file.write(i+'\n') # 在保存数据的同时加上了换行符,方便查看弹幕
chatspider = ChatSpider() # 类的实例化
chatspider.get_data() # 执行类的获取数据代码
chatspider.save_data() # 执行类的保存数据代码
mask = np.array(Image.open('./杨幂/杨幂3纯色图.png')) # 打开图片,并将像素点转换成矩阵的形式,设置词云形状
with open('./斛珠夫人弹幕.txt','r',encoding='utf-8') as files: # 打开“斛珠夫人弹幕.txt”,如果没有就创建一个跟程序同目录的;
# ‘w’为写入;
# 编码形式为'utf-8',如果不添加编码形式,因为弹幕里有表情等形式,可能会出错
text = files.read() # 读取文件内容
print(text) # 打印文件内容
words = jieba.lcut(text) # 利用 jieba 库中的 lcut 方法,将文件内容分成词的形式,并返回列表
print(words) # 打印 句子 分成 词 后的列表
new_text = ' '.join(words) # 将词与词之间用 空格 连接连成一整个字符串
print(new_text) # 打印一整个字符串
word_cloud = WordCloud(font_path='msyh.ttc',\ # 添加字体路径
width=433,\ # 设置词云图片宽度
height=577,\ # 设置词云图片高度
max_words=10000,\ # 设置最大字体的大小
mask=mask,\ # 设置遮罩层,除白色外,其他都被词云覆盖
contour_width=3,\ # 设置词云轮廓宽度
contour_color='steelblue',\ # 设置词云轮廓颜色
background_color='white',\ # 设置词云背景颜色
).generate(text) # 根据文本内容生成词云
word_cloud.to_file('斛珠夫人弹幕词云.jpg') # 输出词云图片