总的源代码:
import os.path
import re
import time
import requests
import json
import pprint #把字典类型的数据按照源代码类型的形式输出来,更容易观察
#建立下载虎牙视频的地址:dir_name
dir_name = '数码――虎牙视频'
if not os.path.exists(dir_name):
os.mkdir(dir_name)
head = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
def find_save(id):
#先找视频播放地址,利用.mp4到前面/的一堆东西来查找,单个视频的总的播放地址
#https://videobd-platform.cdn.huya.com/1048585/5668003/31077907/d68919f9eb244c073904380017b185ac.mp4?vid=604111737
time.sleep(3) #好像有一个视频有一点大,然后后面就断开连接了,这里把访问时间改变一下
#寻找视频播放地址的总链接,改变videoId来改变视频
baseurl = f'https://liveapi.huya.com/moment/getMomentContent?videoId={id}'
#对视频的播放地址来查找视频详细的可以下载的网址
request = requests.get(url=baseurl,headers=head)
response = request.json() #查找的JQ类型的,然后就改变一下
# pprint.pprint(response)
title = response['data']['moment']['title'] ##字典类型来用键查找值
vedio_link = response['data']['moment']['videoInfo']['definitions'][0]['url'] ##字典类型来用键查找值
# print(title)
# print(vedio_link) #判断是不是查找到了想要的标题以及链接
#保存视频(利用获得的详细的可以下载的视频来进行下载)
file_name = title
requ = requests.get(url=vedio_link,headers=head)
with open(dir_name + '/' + file_name + '.mp4','wb') as f: #一定要对视频加上后缀名(不然不可以播放)
f.write(requ.content)
print(file_name,'下载完成')
requ.close()
request.close() #对打开的网页进行关闭,防止被拉黑
#上面是对单个视频进行下载
#下面我们利用链接不同的id来对一个页面的视频进行下载
def find_id():
#先利用查找视频的详细链接来搜索然后找到所有视频的总页面的来凝结
all_url = 'https://v.huya.com/g/all?set_id=41'
request = requests.get(url=all_url,headers=head)
response = request.text
# print(response)
idss = re.findall(r' <script> window.HNF_GLOBAL_INIT = (.*?) </script>',response)[0] #利用正则表达式来来找到存有所有的id的总的字符串
#利用json来让字符串强制转换为字典类型
idss = json.loads(idss)
# pprint.pprint(idss)
#这里注意,前面是字典,但是字典里面到每个视频的信息又一次成了列表类型
ids = idss['videoData']['videoDataList']['value']
print(ids)
#这里利用列表,查找每一个id,因为有个保存的函数,所以把这个搜寻的小程序也写成函数,然后把各个id放到列表当中,然后再单个链接去下载
id = [i['vid']for i in ids]
print(id) #这里的所有的id都放在了一个列表当中
# for i in ids:
# id = i['vid'] #遍历列表,每个元素(也是每个视频的信息)又是字典
# print(id) #这里的id是一个一个的,需要添加步骤放到一个列表当中
request.close()
return id
id = find_id()
for i in id:
find_save(i)1.先找单个视频的网页中的包
? ? ? (1)? 1)右键点击检查,然后
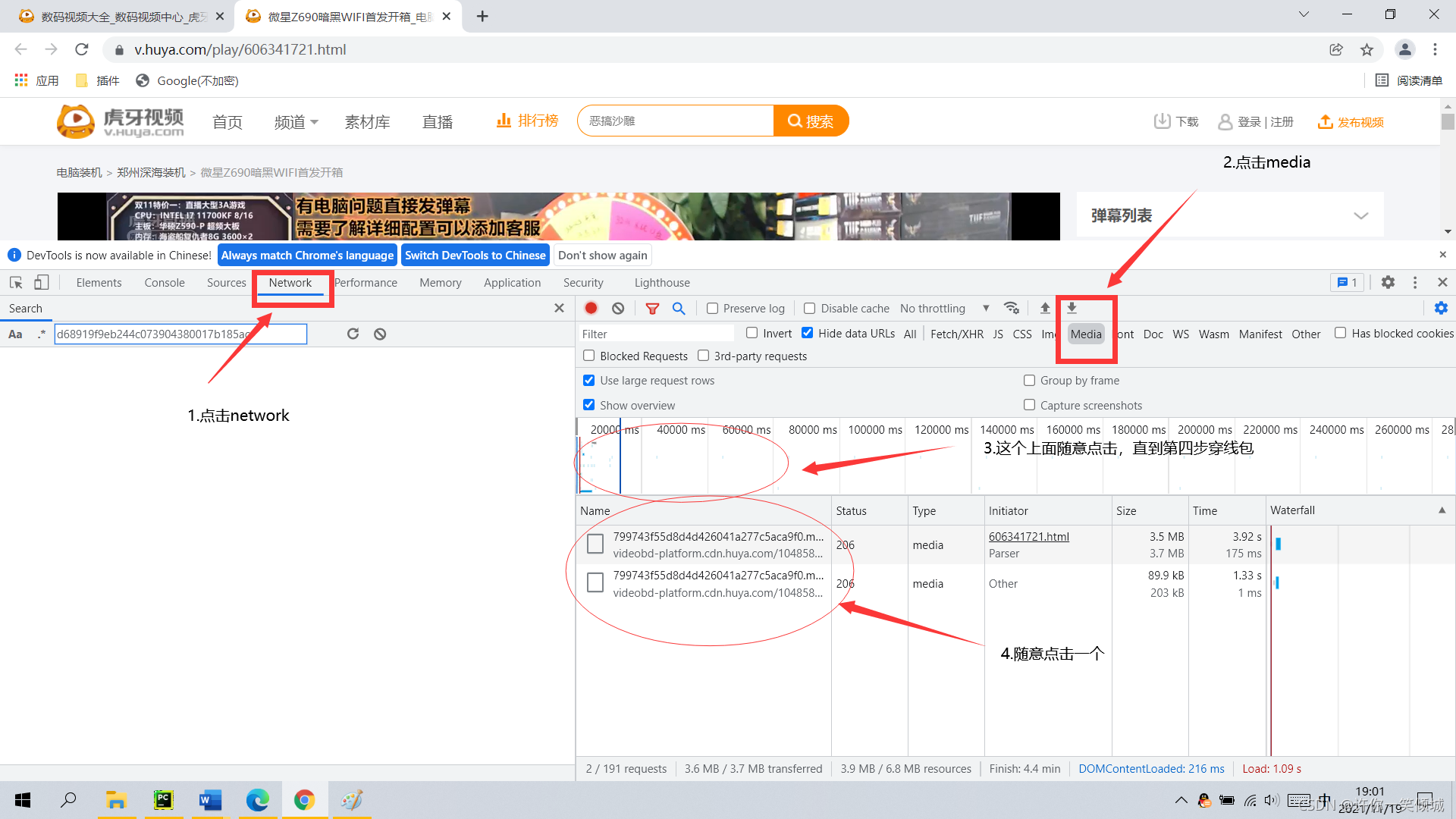
?????????2)复制/后面,.mp4前面的内容
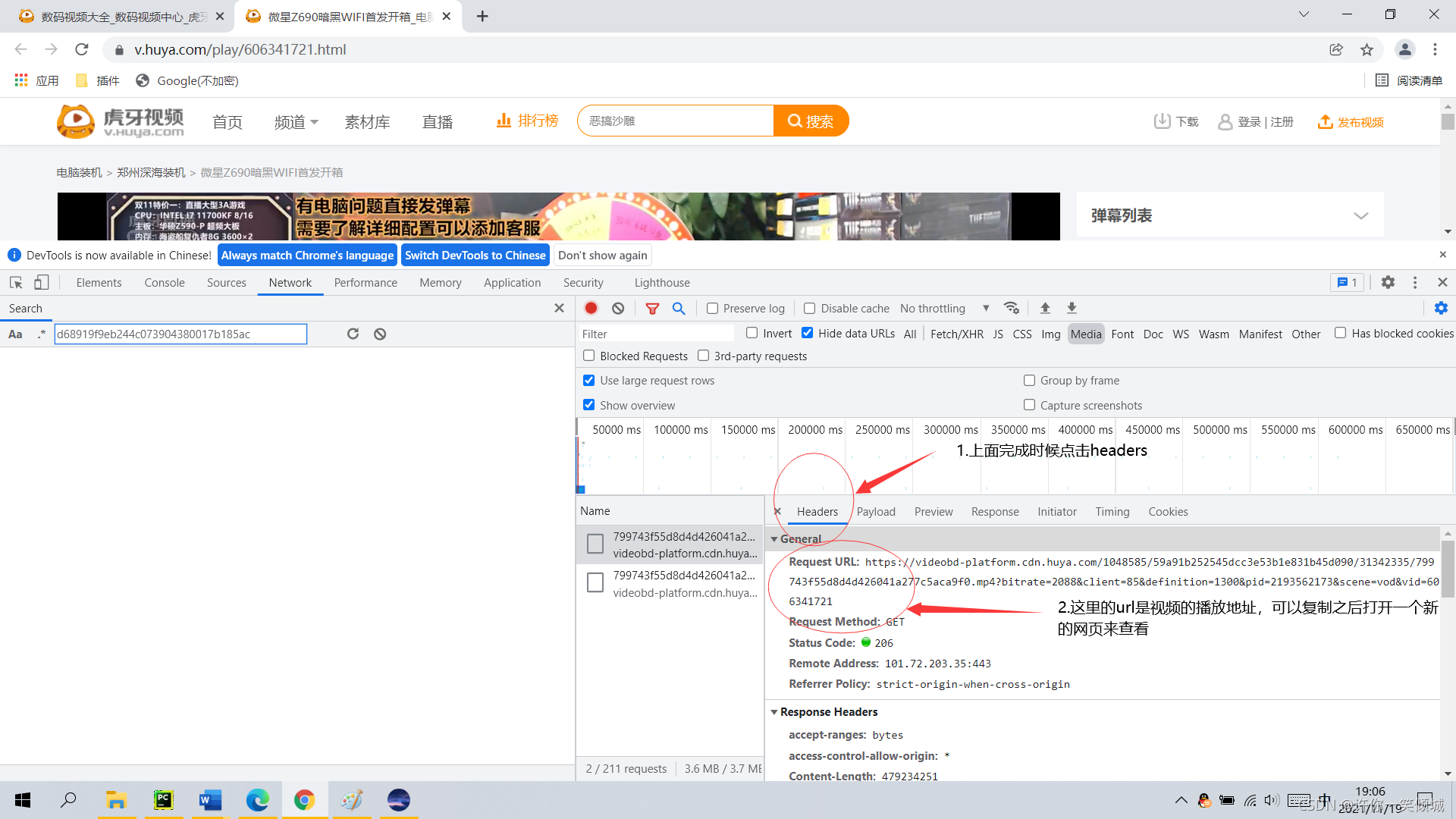
?3)将复制的内容在当前页面搜索获取每个视频页面的网址代码
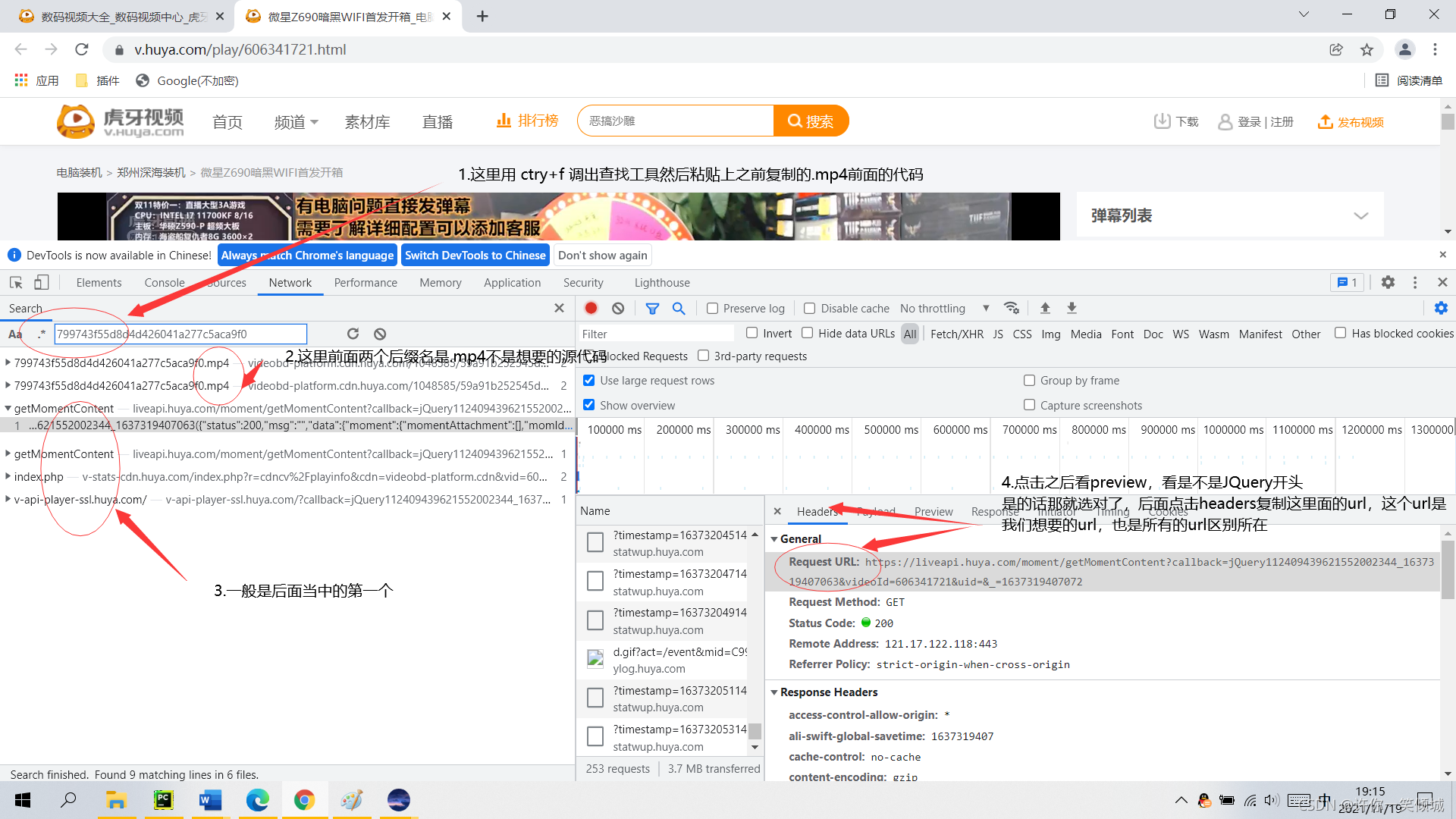
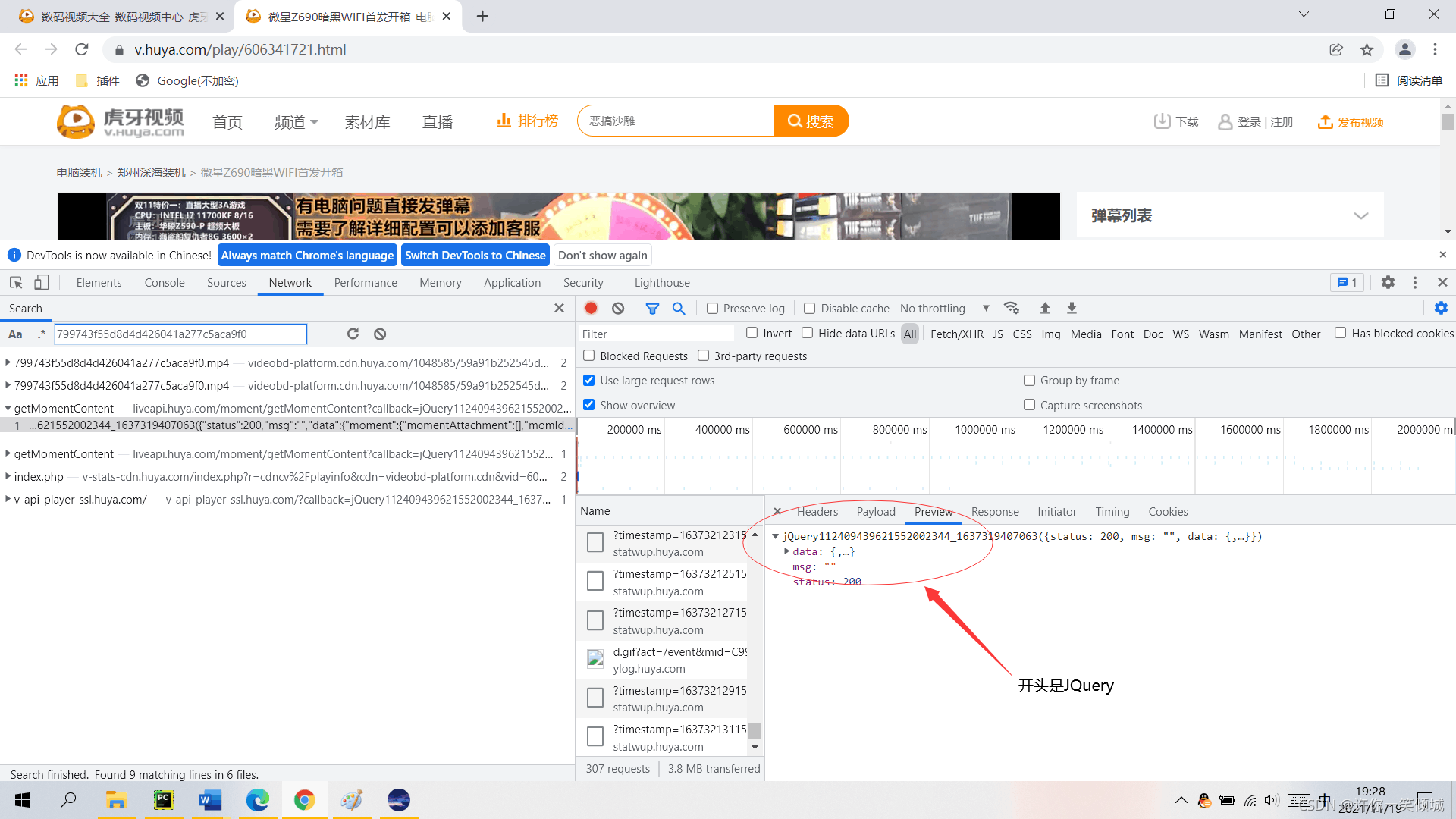
?
?
再多打开几个网址同做这样的事会发现我们获得的单个视频播放的网址只有id后面不同
(2).利用单个视频中的信息来找所有视频的videoid,只有这里不同,并且把callback和uid删去也可以打开同样的网页
代码:
import os.path
import re
import time
import requests
import json
import pprint #把字典类型的数据按照源代码类型的形式输出来,更容易观察
#建立下载虎牙视频的地址:dir_name
dir_name = '数码――虎牙视频'
if not os.path.exists(dir_name):
os.mkdir(dir_name)
head = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
def find_save(id):
#先找视频播放地址,利用.mp4到前面/的一堆东西来查找,单个视频的总的播放地址
#https://videobd-platform.cdn.huya.com/1048585/5668003/31077907/d68919f9eb244c073904380017b185ac.mp4?vid=604111737
time.sleep(3) #好像有一个视频有一点大,然后后面就断开连接了,这里把访问时间改变一下
#寻找视频播放地址的总链接,改变videoId来改变视频
baseurl = f'https://liveapi.huya.com/moment/getMomentContent?videoId={id}'
#对视频的播放地址来查找视频详细的可以下载的网址
request = requests.get(url=baseurl,headers=head)
response = request.json() #查找的JQ类型的,然后就改变一下
# pprint.pprint(response)
title = response['data']['moment']['title'] ##字典类型来用键查找值
vedio_link = response['data']['moment']['videoInfo']['definitions'][0]['url'] ##字典类型来用键查找值
# print(title)
# print(vedio_link) #判断是不是查找到了想要的标题以及链接
#保存视频(利用获得的详细的可以下载的视频来进行下载)
file_name = title
requ = requests.get(url=vedio_link,headers=head)
with open(dir_name + '/' + file_name + '.mp4','wb') as f: #一定要对视频加上后缀名(不然不可以播放)
f.write(requ.content)
print(file_name,'下载完成')
requ.close()
request.close() #对打开的网页进行关闭,防止被拉黑
#上面是对单个视频进行下载2.查找所有视频id
????????1)利用上面单个视频的videoid,在整个页面的检查中查找
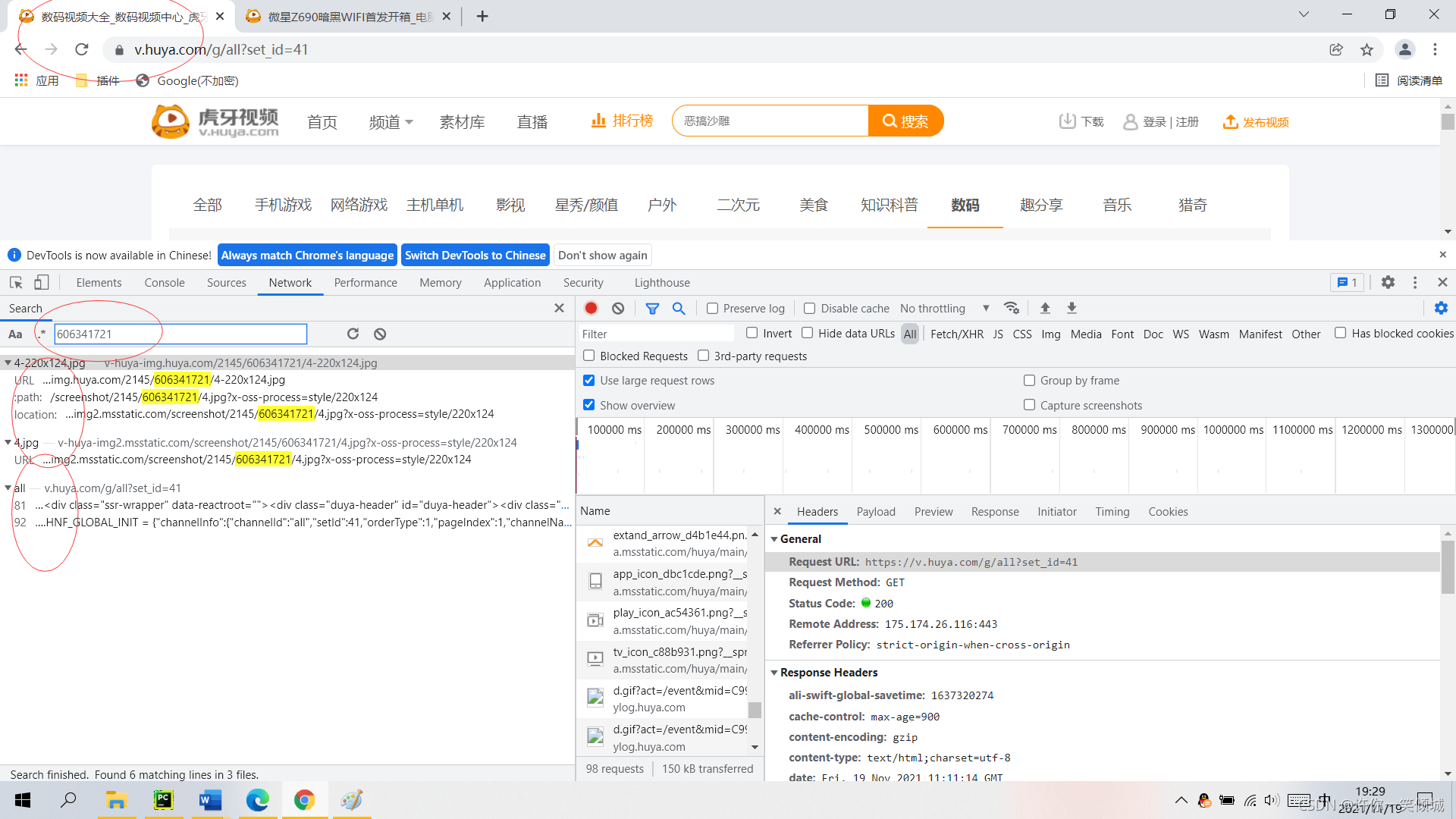
这里上面获取到headers的url是整个页面的网址,和地址栏上面的网址有一些不同
? ? ? ? ?2)查找id的位置
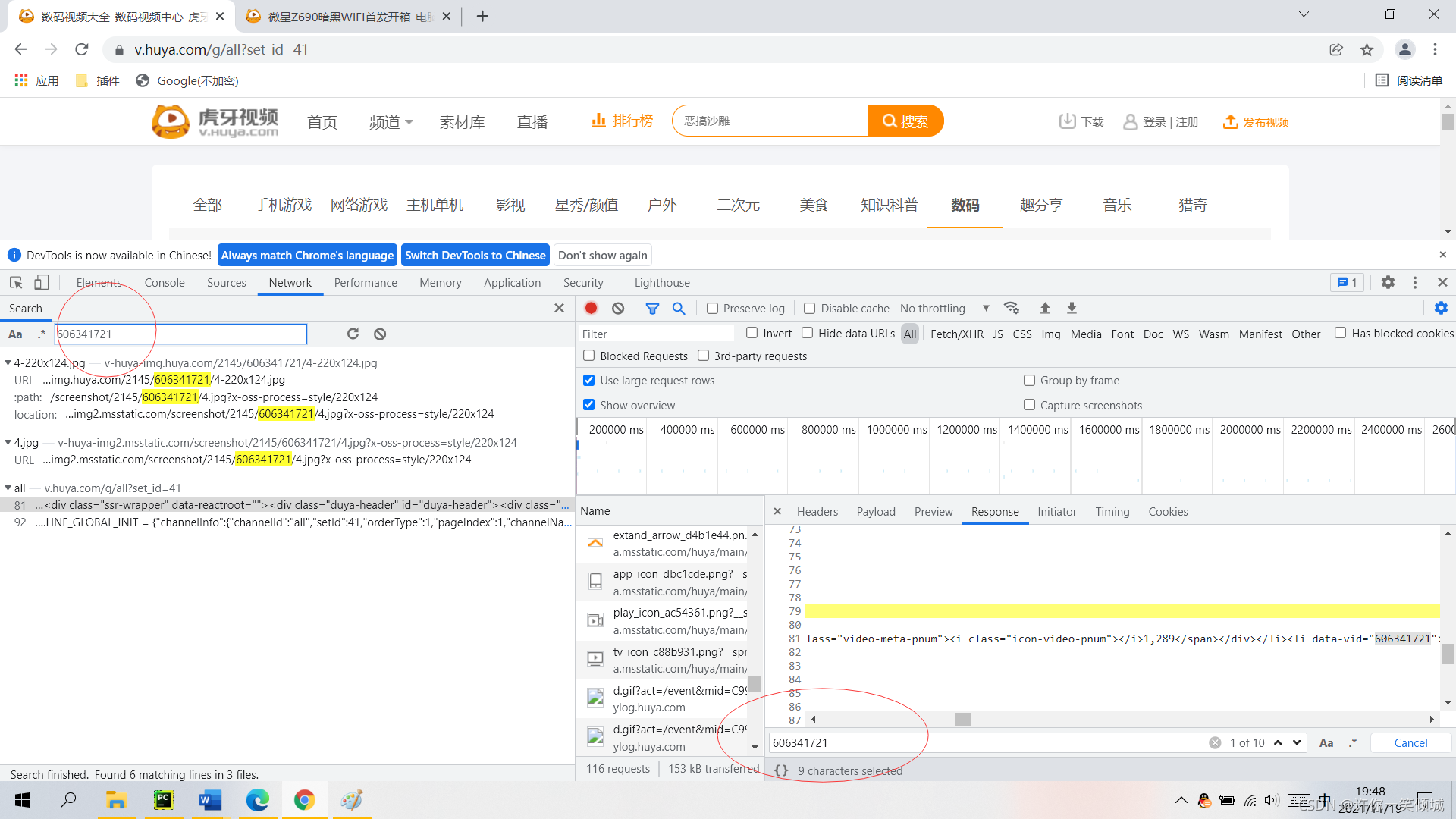
?这里利用两处查找快捷键,分别都在图里的位置,查找内容是videoid
代码:
import os.path
import re
import time
import requests
import json
import pprint #把字典类型的数据按照源代码类型的形式输出来,更容易观察
#下面我们利用链接不同的id来对一个页面的视频进行下载
def find_id():
#先利用查找视频的详细链接来搜索然后找到所有视频的总页面的来凝结
all_url = 'https://v.huya.com/g/all?set_id=41'
request = requests.get(url=all_url,headers=head)
response = request.text
# print(response)
idss = re.findall(r' <script> window.HNF_GLOBAL_INIT = (.*?) </script>',response)[0] #利用正则表达式来来找到存有所有的id的总的字符串
#利用json来让字符串强制转换为字典类型
idss = json.loads(idss)
# pprint.pprint(idss)
#这里注意,前面是字典,但是字典里面到每个视频的信息又一次成了列表类型
ids = idss['videoData']['videoDataList']['value']
print(ids)
#这里利用列表,查找每一个id,因为有个保存的函数,所以把这个搜寻的小程序也写成函数,然后把各个id放到列表当中,然后再单个链接去下载
id = [i['vid']for i in ids]
print(id) #这里的所有的id都放在了一个列表当中
# for i in ids:
# id = i['vid'] #遍历列表,每个元素(也是每个视频的信息)又是字典
# print(id) #这里的id是一个一个的,需要添加步骤放到一个列表当中
request.close()
return id
3.将这两步联合起来,可以实现对整个页面的视频的保存
代码:
import os.path
import re
import time
import requests
import json
import pprint #把字典类型的数据按照源代码类型的形式输出来,更容易观察
#建立下载虎牙视频的地址:dir_name
dir_name = '数码――虎牙视频'
if not os.path.exists(dir_name):
os.mkdir(dir_name)
head = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
def find_save(id):
#先找视频播放地址,利用.mp4到前面/的一堆东西来查找,单个视频的总的播放地址
#https://videobd-platform.cdn.huya.com/1048585/5668003/31077907/d68919f9eb244c073904380017b185ac.mp4?vid=604111737
time.sleep(3) #好像有一个视频有一点大,然后后面就断开连接了,这里把访问时间改变一下
#寻找视频播放地址的总链接,改变videoId来改变视频
baseurl = f'https://liveapi.huya.com/moment/getMomentContent?videoId={id}'
#对视频的播放地址来查找视频详细的可以下载的网址
request = requests.get(url=baseurl,headers=head)
response = request.json() #查找的JQ类型的,然后就改变一下
# pprint.pprint(response)
title = response['data']['moment']['title'] ##字典类型来用键查找值
vedio_link = response['data']['moment']['videoInfo']['definitions'][0]['url'] ##字典类型来用键查找值
# print(title)
# print(vedio_link) #判断是不是查找到了想要的标题以及链接
#保存视频(利用获得的详细的可以下载的视频来进行下载)
file_name = title
requ = requests.get(url=vedio_link,headers=head)
with open(dir_name + '/' + file_name + '.mp4','wb') as f: #一定要对视频加上后缀名(不然不可以播放)
f.write(requ.content)
print(file_name,'下载完成')
requ.close()
request.close() #对打开的网页进行关闭,防止被拉黑
#上面是对单个视频进行下载
#下面我们利用链接不同的id来对一个页面的视频进行下载
def find_id():
#先利用查找视频的详细链接来搜索然后找到所有视频的总页面的来凝结
all_url = 'https://v.huya.com/g/all?set_id=41'
request = requests.get(url=all_url,headers=head)
response = request.text
# print(response)
idss = re.findall(r' <script> window.HNF_GLOBAL_INIT = (.*?) </script>',response)[0] #利用正则表达式来来找到存有所有的id的总的字符串
#利用json来让字符串强制转换为字典类型
idss = json.loads(idss)
# pprint.pprint(idss)
#这里注意,前面是字典,但是字典里面到每个视频的信息又一次成了列表类型
ids = idss['videoData']['videoDataList']['value']
print(ids)
#这里利用列表,查找每一个id,因为有个保存的函数,所以把这个搜寻的小程序也写成函数,然后把各个id放到列表当中,然后再单个链接去下载
id = [i['vid']for i in ids]
print(id) #这里的所有的id都放在了一个列表当中
# for i in ids:
# id = i['vid'] #遍历列表,每个元素(也是每个视频的信息)又是字典
# print(id) #这里的id是一个一个的,需要添加步骤放到一个列表当中
request.close()
return id
id = find_id()
for i in id:
find_save(i)