目录
一、爬虫简介
1.什么是网络爬虫?
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
2.爬虫类型
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。 实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
- 通用网络爬虫
通用网络爬虫又称全网爬虫(Scalable Web Crawler),爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。 由于商业原因,它们的技术细节很少公布出来。 这类网络爬虫的爬行范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于待刷新的页面太多,通常采用并行工作方式,但需要较长时间才能刷新一次页面。 虽然存在一定缺陷,通用网络爬虫适用于为搜索引擎搜索广泛的主题,有较强的应用价值。 - 聚焦网络爬虫
聚焦网络爬虫(Focused Crawler),又称主题网络爬虫(Topical Crawler),是指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫。 和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。 - 增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler)是指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面。 和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。增量式网络爬虫的体系结构[包含爬行模块、排序模块、更新模块、本地页面集、待爬行 URL 集以及本地页面URL 集]。 - 深层网络爬虫
Web 页面按存在方式可以分为表层网页(Surface Web)和深层网页(Deep Web,也称 Invisible Web Pages 或 Hidden Web)。 表层网页是指传统搜索引擎可以索引的页面,以超链接可以到达的静态网页为主构成的 Web 页面。Deep Web 是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。例如那些用户注册后内容才可见的网页就属于 Deep Web。 2000 年 Bright Planet 指出:Deep Web 中可访问信息容量是 Surface Web 的几百倍,是互联网上最大、发展最快的新型信息资源。
3.网络爬虫的使用范围
①作为搜索引擎的网页搜集器,抓取整个互联网,如谷歌,百度等。
②作为垂直搜索引擎,抓取特定主题信息,如视频网站,招聘网站等。
③作为测试网站前端的检测工具,用来评价网站前端代码的健壮性。
4.网络爬虫的合法性
Robots协议:又称机器人协议或爬虫协议,该协议就搜索引擎抓取网站内容的范围作了约定,包括网站是否希望被搜索引擎抓取,哪些内容不允许被抓取,网络爬虫据此“自觉地”抓取或者不抓取该网页内容。自推出以来Robots协议已成为网站保护自有敏感数据和网民隐私的国际惯例。
- robots协议通过robots.txt实现.
- robots.txt文件应该放置在网站根目录下。
- 当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面.
5.网页搜索策略
网页的抓取策略可以分为深度优先、广度优先和最佳优先三种。深度优先在很多情况下会导致爬虫的陷入(trapped)问题,目前常见的是广度优先和最佳优先方法。
- 广度优先搜索
广度优先搜索策略是指在抓取过程中,在完成当前层次的搜索后,才进行下一层次的搜索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索方法。也有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。另外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。这些方法的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。 - 最佳优先搜索
最佳优先搜索策略按照一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个URL进行抓取。它只访问经过网页分析算法预测为“有用”的网页。存在的一个问题是,在爬虫抓取路径上的很多相关网页可能被忽略,因为最佳优先策略是一种局部最优搜索算法。因此需要将最佳优先结合具体的应用进行改进,以跳出局部最优点。将在第4节中结合网页分析算法作具体的讨论。研究表明,这样的闭环调整可以将无关网页数量降低30%~90%。 - 深度优先搜索
深度优先搜索策略从起始网页开始,选择一个URL进入,分析这个网页中的URL,选择一个再进入。如此一个链接一个链接地抓取下去,直到处理完一条路线之后再处理下一条路线。深度优先策略设计较为简单。然而门户网站提供的链接往往最具价值,PageRank也很高,但每深入一层,网页价值和PageRank都会相应地有所下降。这暗示了重要网页通常距离种子较近,而过度深入抓取到的网页却价值很低。同时,这种策略抓取深度直接影响着抓取命中率以及抓取效率,对抓取深度是该种策略的关键。相对于其他两种策略而言。此种策略很少被使用。
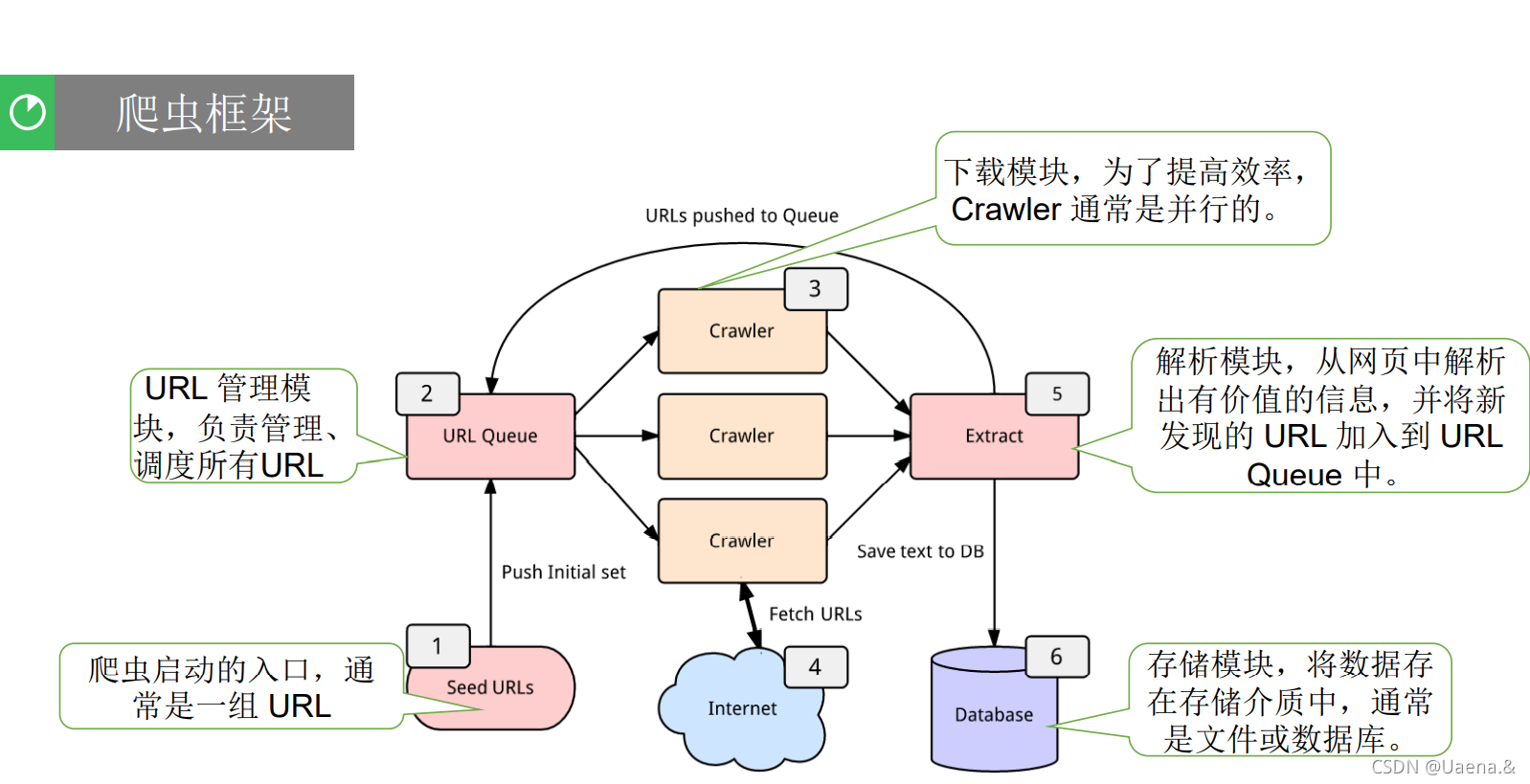
6.爬虫的基本结构
网络爬虫通常包含四个模块:
? URL管理模块
? 下载模块
? 解析模块
? 存储模块
二、环境准备
(一)新建一个python虚拟环境
用conda建立一个名为crawler的python虚拟环境,在此虚拟环境中用pip或conda安装requests、beautifulsoup4等必要包(若有网络问题,请切换国内镜像网站或国外网站仓库,注意两个安装工具使用不同的仓库)。当使用jupyter、pycharm、spyder、vscoder等IDE编程环境时,需要自己选择设置IDE后台使用的python版本或虚拟环境。比如当使用jupyter notebook时,参考(https://blog.csdn.net/qq_35654046/article/details/106972448),在jupyter运行的web界面中选择对其应的python内核Kernel(有虚拟环境列表);如果使用pycharm,参考(https://blog.csdn.net/ifubing/article/details/105153541)选择相应的已有虚拟环境。
使用conda create -n crawler python=3.8命令,新建一个名为crawlerpython版本为3.8的虚拟环境
y开始创建
创建好啦
使用命令conda env list可以查看已有的虚拟环境,crawler已存在,base是conda自带的环境,uuu是我之前创建的
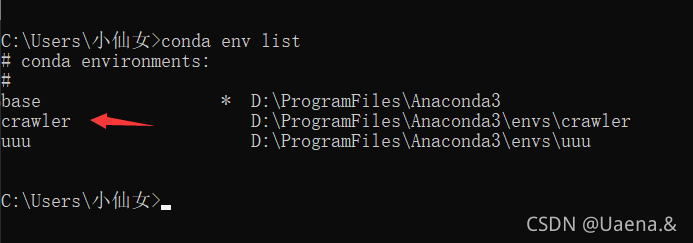
activate crawler进入crawler环境,conda deactivate退出当前环境,activate就是进入base环境

conda remove --name 环境名 --all卸载环境
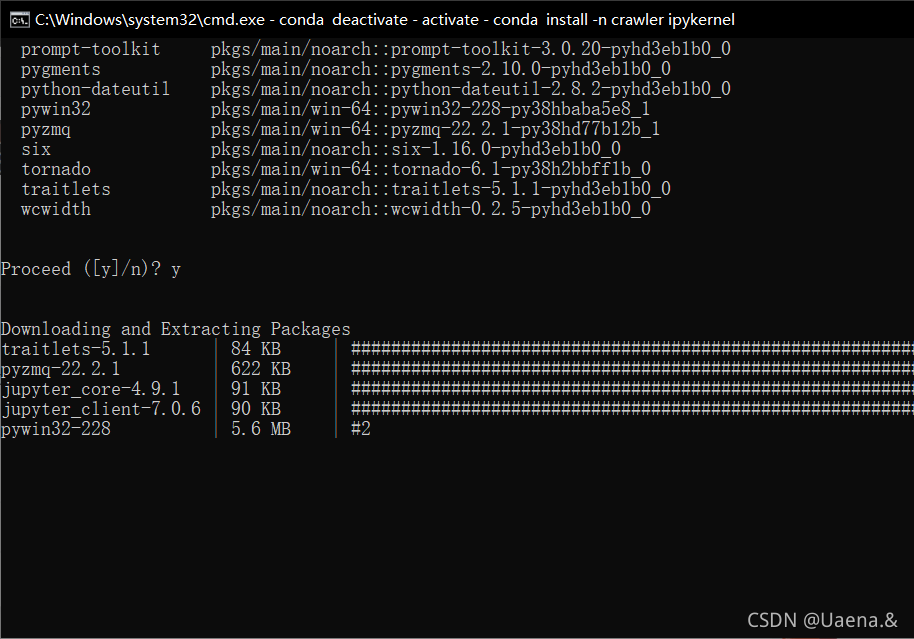
jupyter notebook原生不支持选择虚拟环境,每次有新项目都需要重新配置一遍所有插件。使用nb_conda插件将jupyter notebook变成和pycharm一样可以选择运行环境。
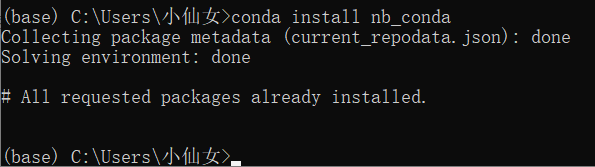
使用conda install nb_conda命令在base环境中安装nb_conda
使用conda install -n 环境名 ipykernel命令在conda虚拟环境中安装ipykernel
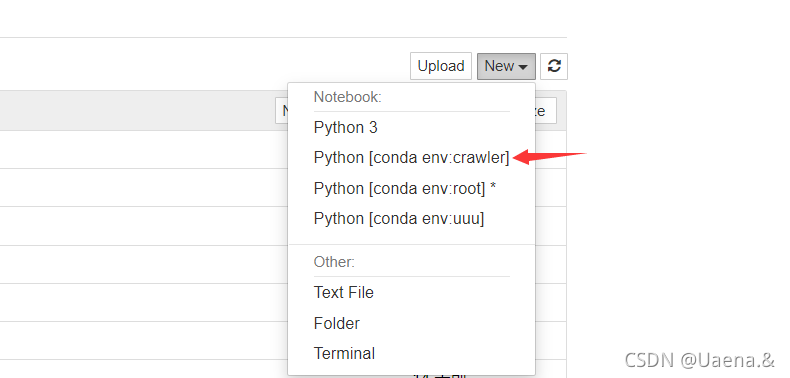
可以在jupyter notebook中显示了
(二)安装库
环境准备
Python安装,这部分可以参考我之前的文章Python环境配置&Pycharm安装,去官网下载对应的安装包,一路Next安装就行了;
pip安装,pip是Python的包管理器,现在的Python安装包一般都会自带pip,不需要自己再去额外安装了;
requests,beautifulsoup库的安装,通过以下语句来完成安装:
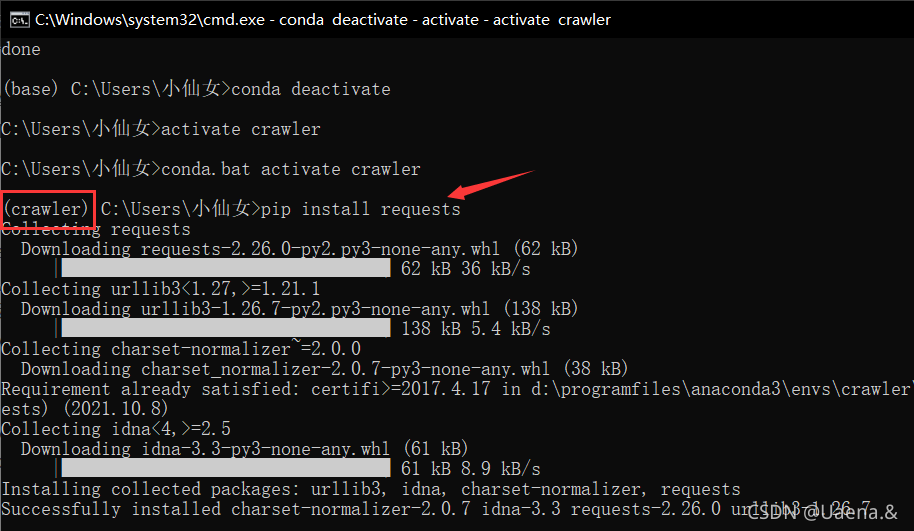
pip install requests
pip install beautifulsoup4
谷歌浏览器(chrome);
pip install requests
pip install beautifulsoup4
pip install html5lib
三、爬取南阳理工学院ACM题目网站
学习示例代码,对关键代码语句写出详细注释,编程完成对南阳理工学院ACM题目网站 http://www.51mxd.cn/ 练习题目数据的抓取和保存;
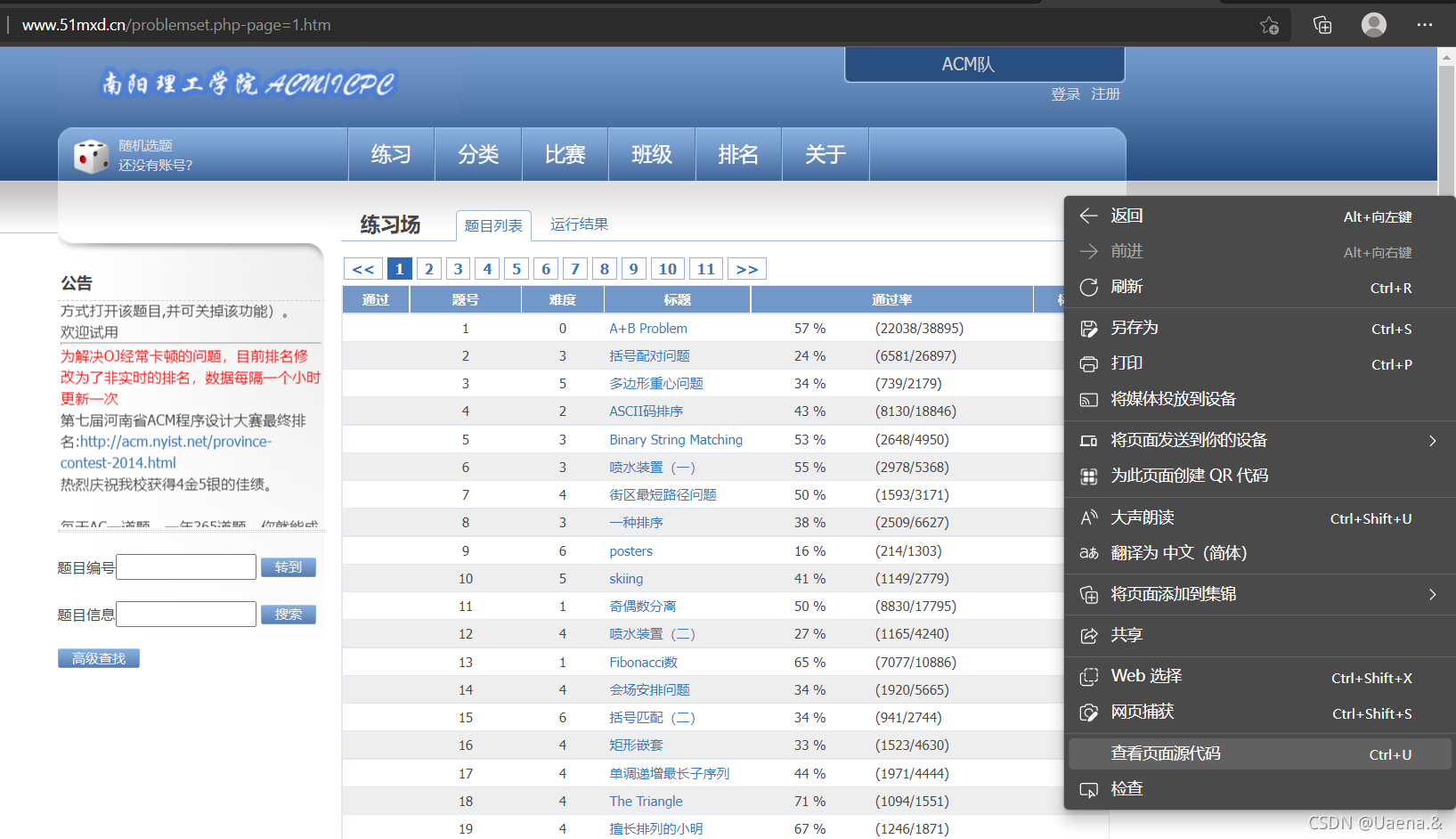
(一)查看页面源代码
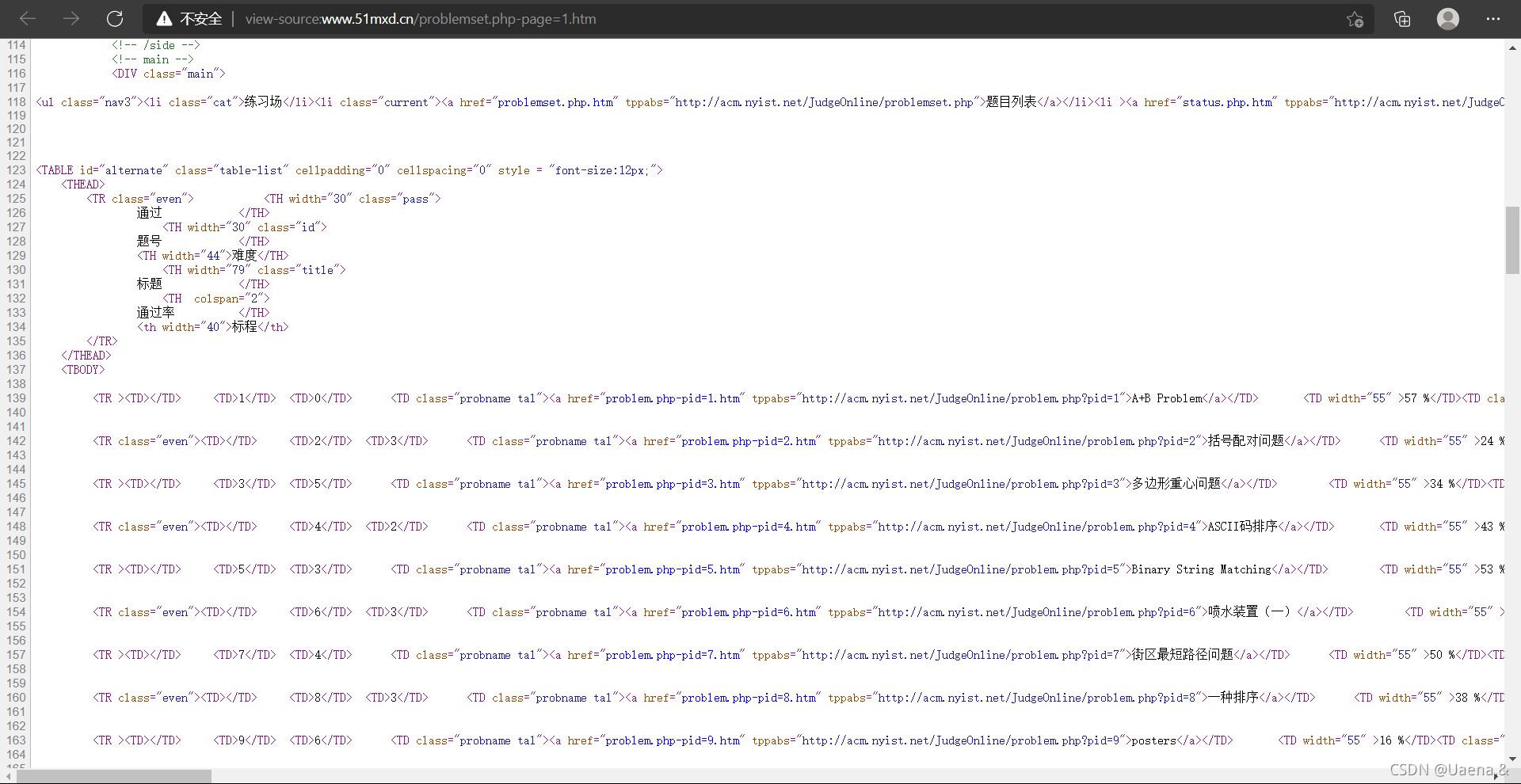
点击进入南阳理工学院ACM题目网站,
右击->查看页面源代码
(二)代码运行
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
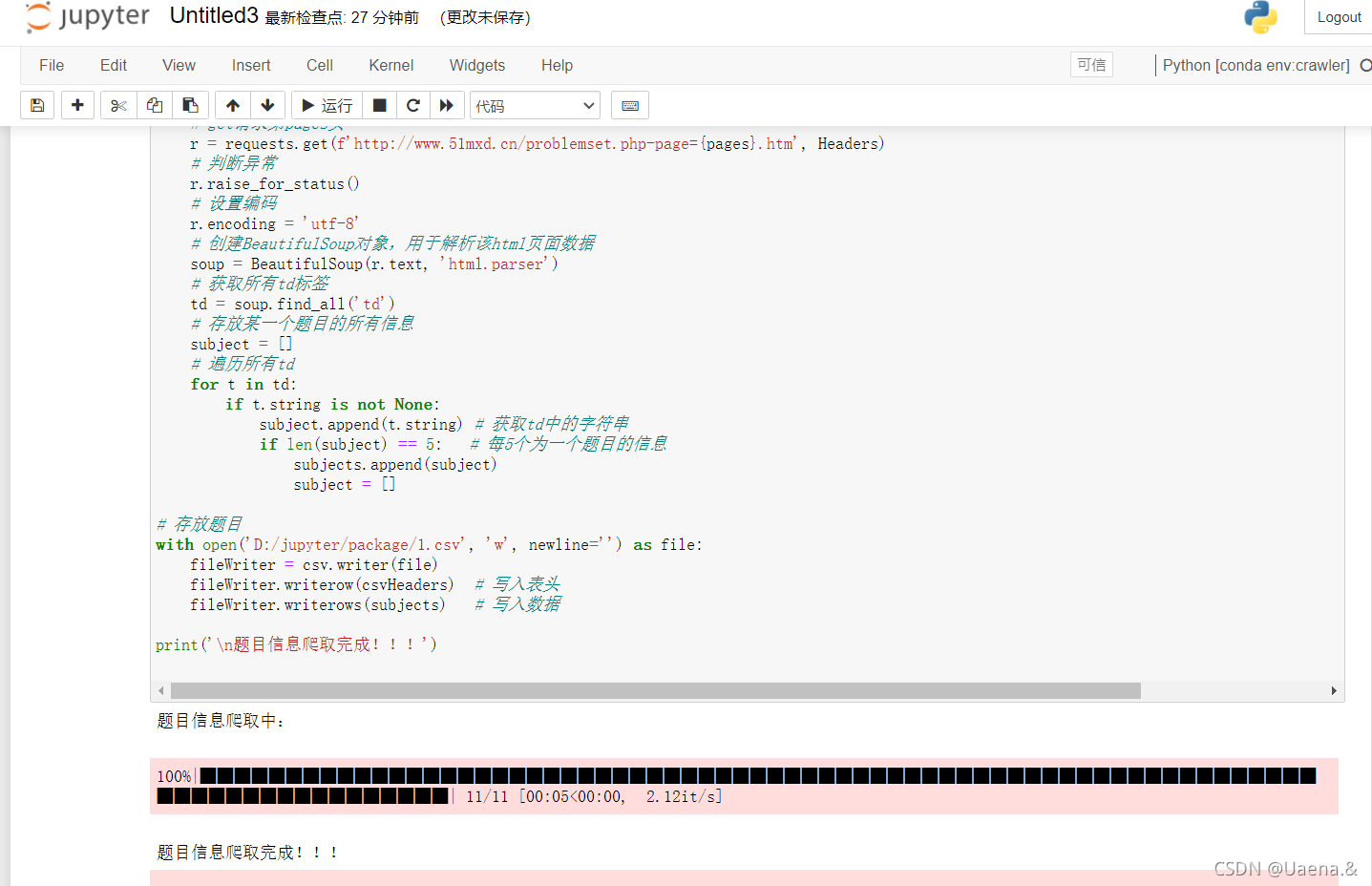
print('题目信息爬取中:\n')
# tqdm作业:以进度条方式显示爬取进度
# 爬取11页所有题目信息
for pages in tqdm(range(1, 11 + 1)):
# get请求第pages页
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers)
# 判断异常
r.raise_for_status()
# 设置编码
r.encoding = 'utf-8'
# 创建BeautifulSoup对象,用于解析该html页面数据
soup = BeautifulSoup(r.text, 'html.parser')
# 获取所有td标签
td = soup.find_all('td')
# 存放某一个题目的所有信息
subject = []
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('D:/jupyter/package/1.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) # 写入表头
fileWriter.writerows(subjects) # 写入数据
print('\n题目信息爬取完成!!!')
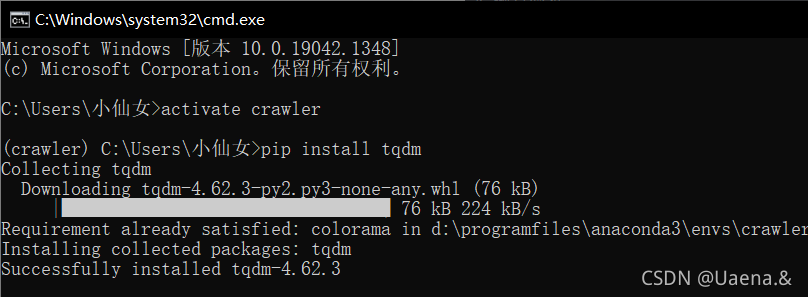
运行,报错ModuleNotFoundError: No module named 'tqdm',缺少tqdm文件,使用命令pip install tqdm安装
报错FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?,使用pip install lxml安装,然后还是不行,安装的时候自动最新版本,把刚刚下载的版本删掉:pip uninstall lxml,指定版本下载试试:pip install lxml==3.7.0。还是不行!!
那就第二个方法,将参数lxml修改为html.parser
soup = BeautifulSoup(r.text, 'html.parser')
可以啦!激动的心颤抖的手~
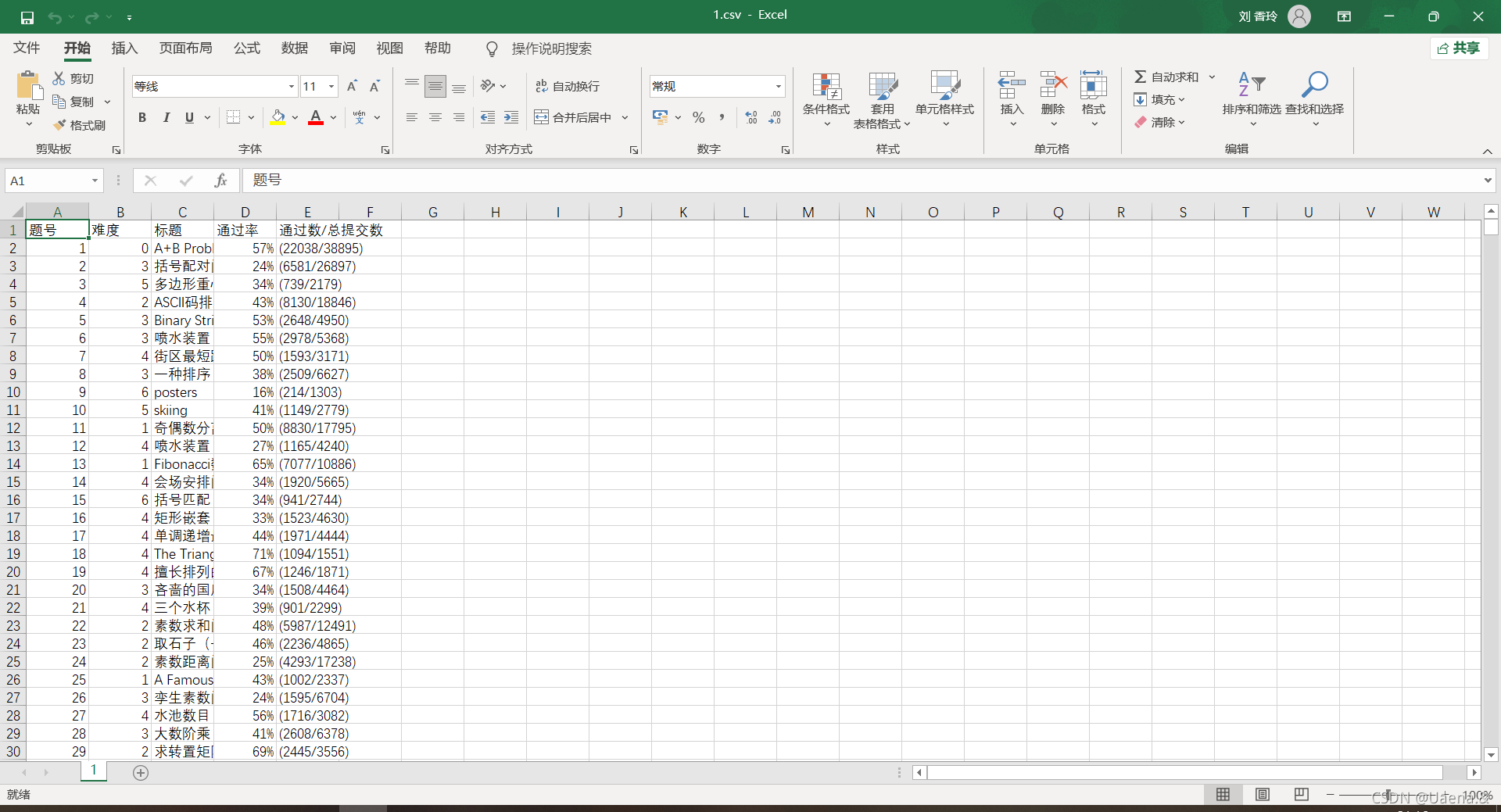
(三)结果
四、爬取重庆交通大学新闻网站
改写爬虫示例代码,将重庆交通大学新闻网站中近几年所有的信息通知(http://news.cqjtu.edu.cn/xxtz.htm) 的发布日期和标题全部爬取下来,并写到CSV电子表格中。
(一)查看网页源代码
重庆交通大学新闻网
右击->查看网页源代码
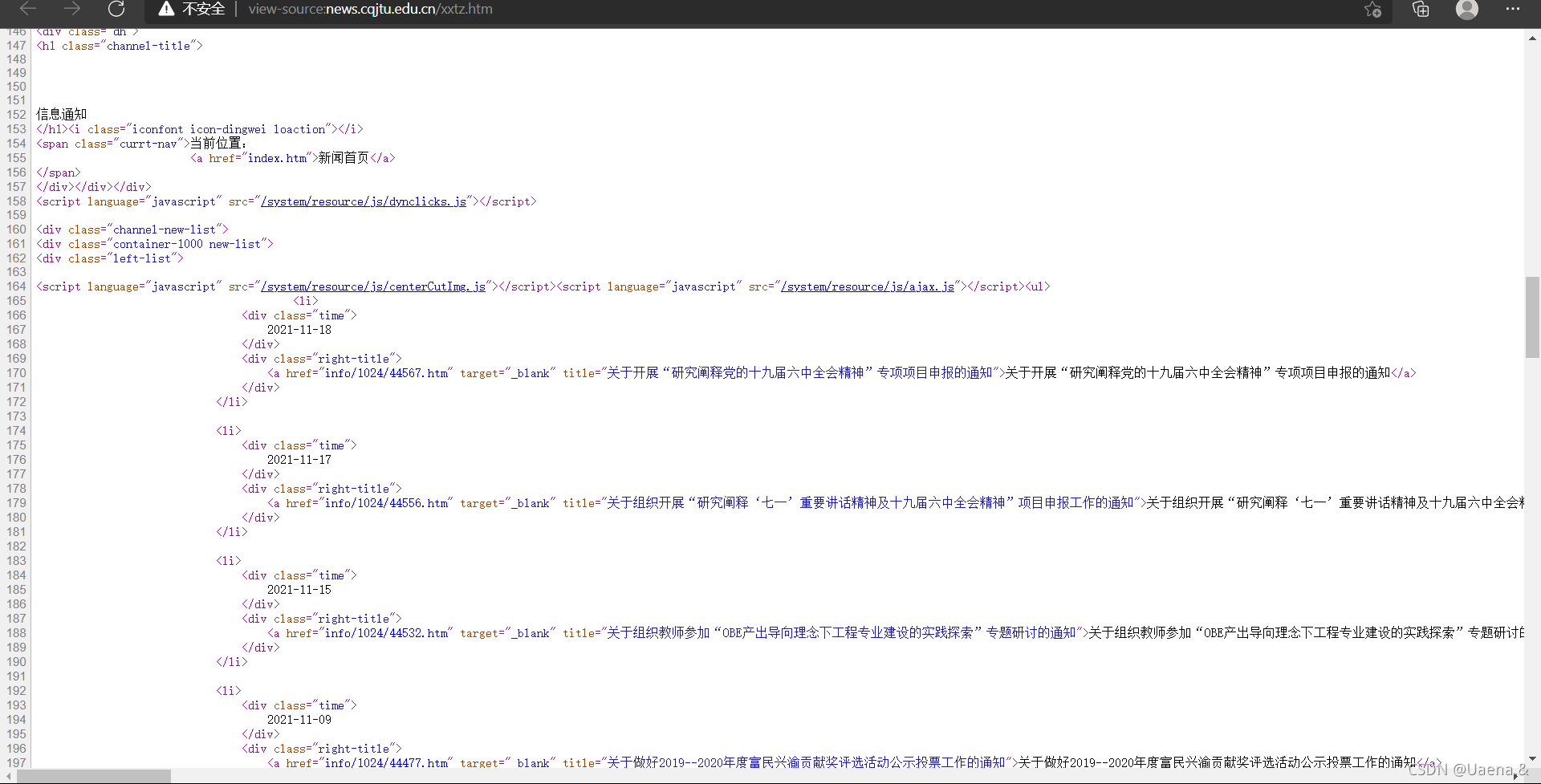
(二)代码运行
import requests
from bs4 import BeautifulSoup
import csv
from tqdm import tqdm
# 模拟浏览器访问
cqjtu_Headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'
}
#csv的表头
cqjtu_head=["日期","标题"]
#存放内容
cqjtu_infomation=[]
def get_page_number():
r=requests.get(f"http://news.cqjtu.edu.cn/xxtz.htm",headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html5lib')
page_num=soup.find_all('script',page_array)
page_number=page_num[4].string#只靠标签这些定位好像不是唯一,只能手动定位了
page_number=page_number.strip('function a204111_gopage_fun(){_simple_list_gotopage_fun(')#删掉除页数以外的其他内容
page_number=page_number.strip(',\'a204111GOPAGE\',2)}')
page_number=int(page_number)#转为数字
return page_number
def get_time_and_title(page_num,cqjtu_Headers):#页数,请求头
if page_num==66 :
url='http://news.cqjtu.edu.cn/xxtz.htm'
else :
url=f'http://news.cqjtu.edu.cn/xxtz/{page_num}.htm'
r=requests.get(url,headers=cqjtu_Headers)
r.raise_for_status()
r.encoding="utf-8"
array={#根据class来选择
'class':'time',
}
title_array={
'target':'_blank'
}
page_array={
'type':'text/javascript'
}
soup = BeautifulSoup(r.text, 'html.parser')
time=soup.find_all('div',array)
title=soup.find_all('a',title_array)
temp=[]
for i in range(0,len(time)):
time_s=time[i].string
time_s=time_s.strip('\n ')
time_s=time_s.strip('\n ')
#清除空格
temp.append(time_s)
temp.append(title[i+1].string)
cqjtu_infomation.append(temp)
temp=[]
def write_csv(cqjtu_info):
with open('D:/jupyter/package/2.csv', 'w', newline='',encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(cqjtu_head)
fileWriter.writerows(cqjtu_info)
print('爬取信息成功')
page_num=get_page_number()#获得页数
for i in tqdm(range(page_num,0,-1)):
get_time_and_title(i,cqjtu_Headers)
write_csv(cqjtu_infomation)
运行
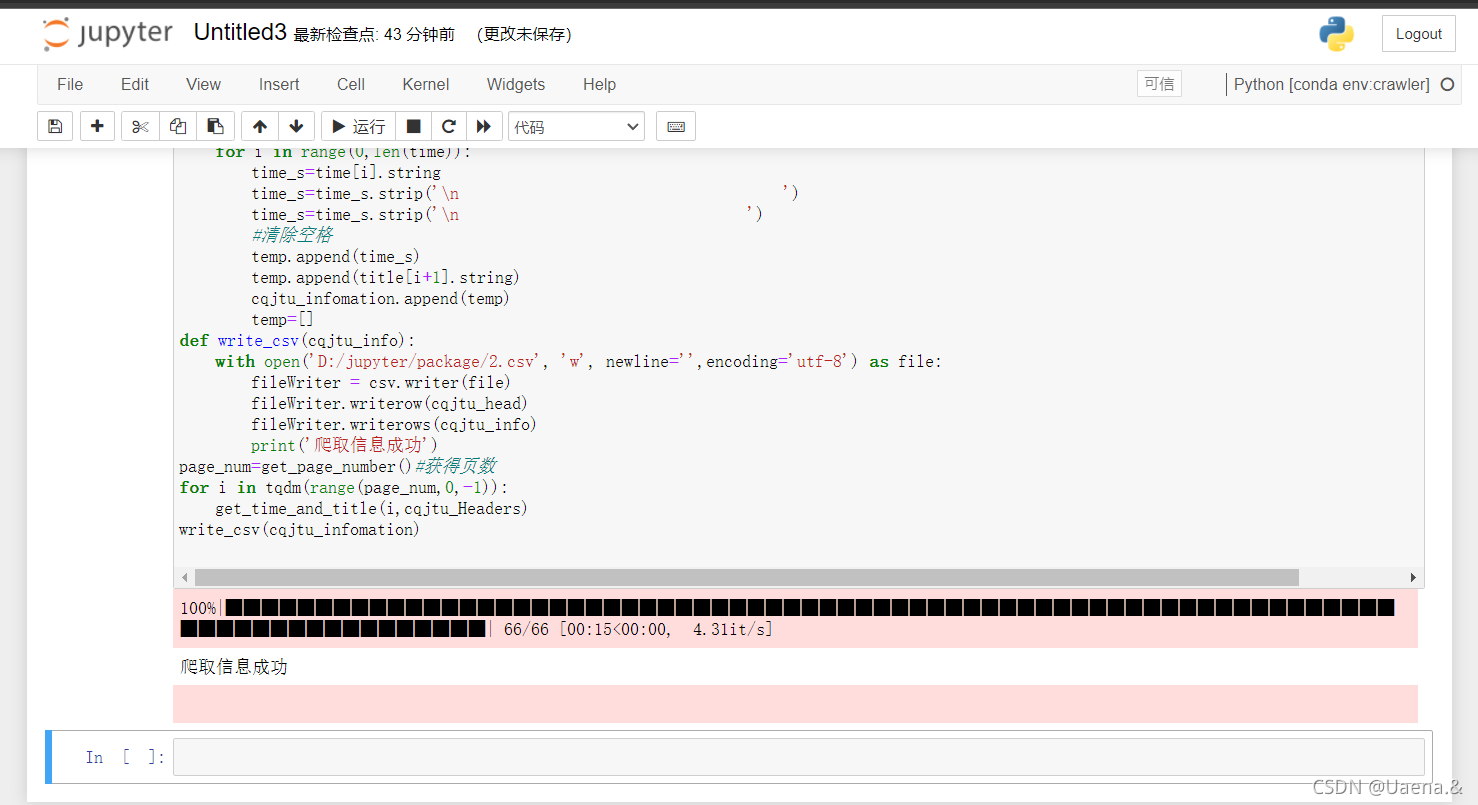
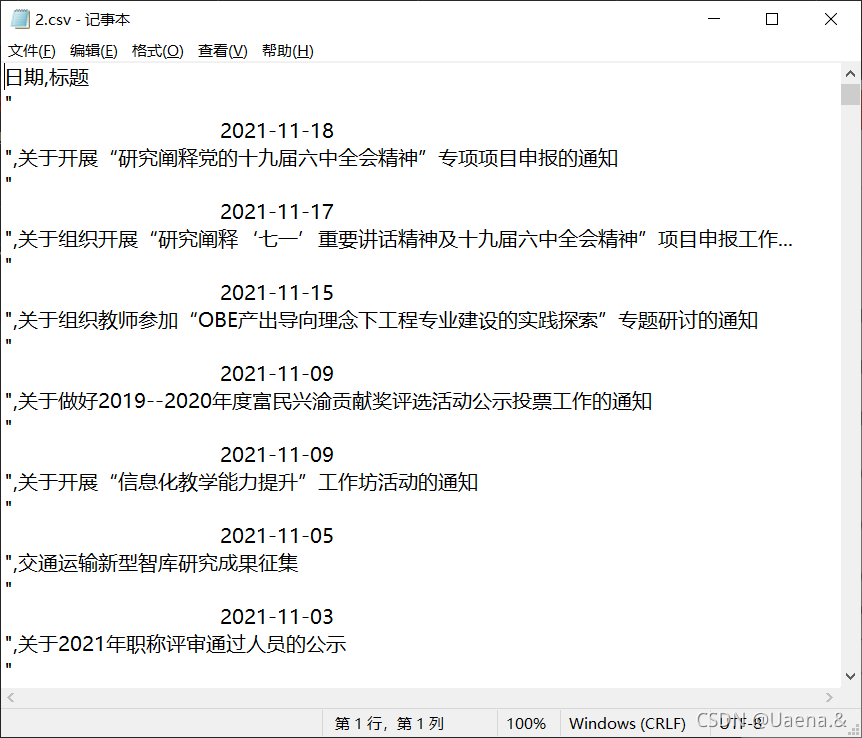
(三)结果
打开是这样的
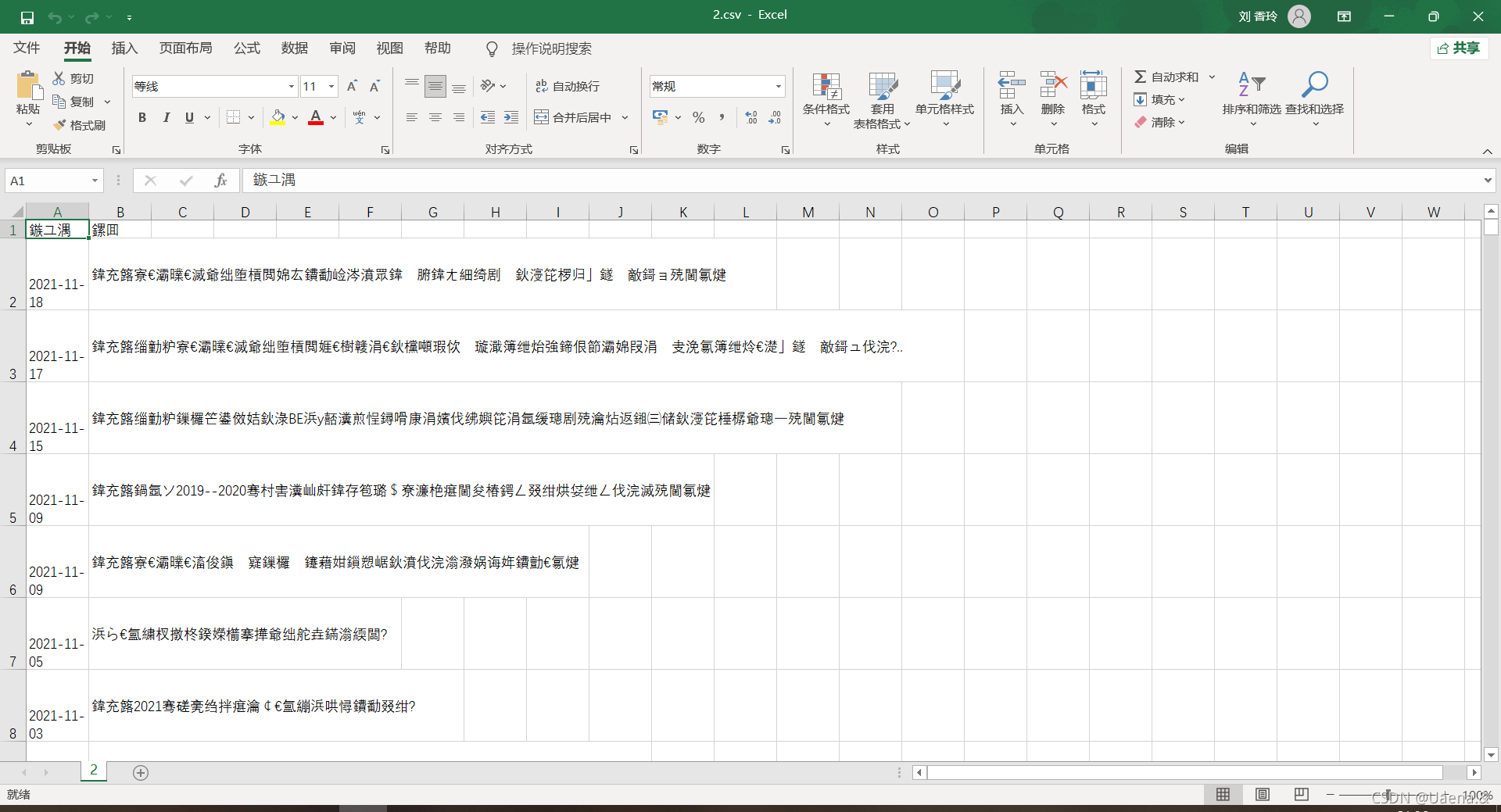
记事本打开
参考文献
Jupyter notebook选择运行代码的虚拟环境
anaconda安装教程、管理虚拟环境
Python爬虫练习(爬取OJ题目和学校信息通知)