爬虫第一步先大概分析一下目标网站
插画师实习_插画师实习生招聘信息 – 实习僧实习僧为大学生提供2021年最新的插画师实习,插画师实习生招聘信息。助力大学生职业发展,帮助企业有效招聘,找实习校招就上实习僧
 当时我看到有五百多页,就直接点到第六页想看看后续会不会弹出登录验证,因为有些网站得话你不登录它是不会让你看到后面得内容得
当时我看到有五百多页,就直接点到第六页想看看后续会不会弹出登录验证,因为有些网站得话你不登录它是不会让你看到后面得内容得
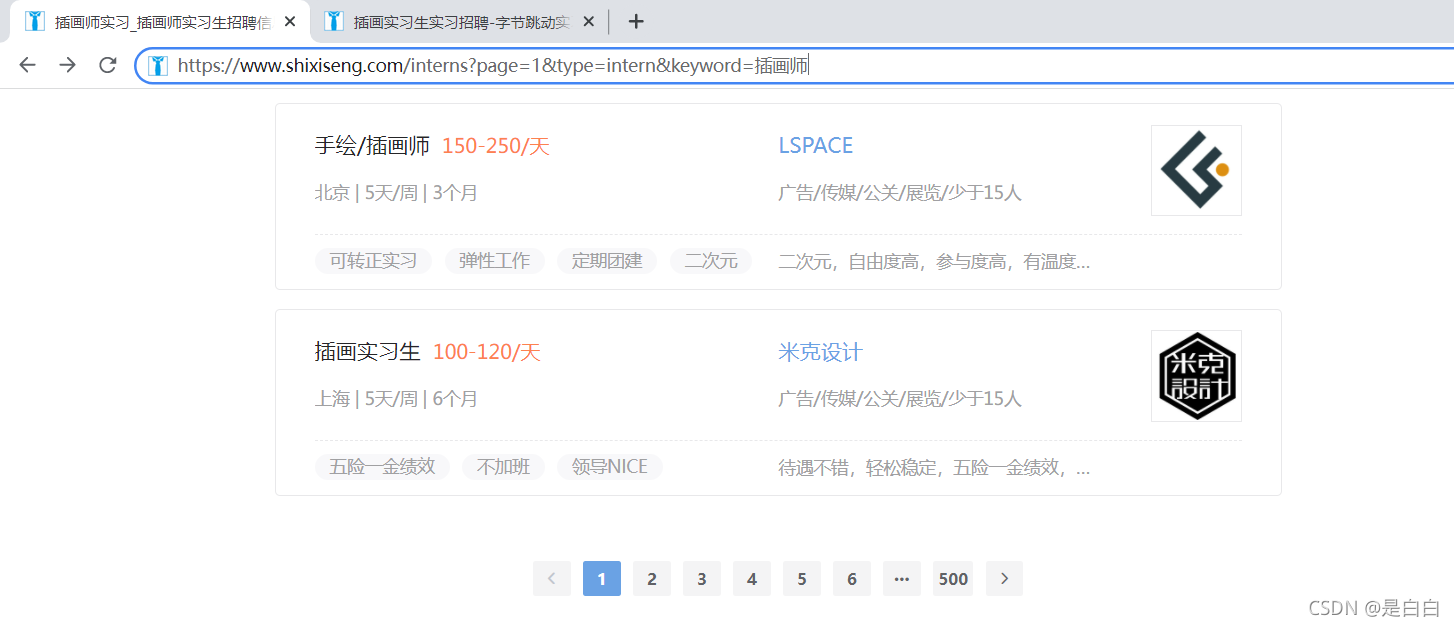
不过点了之后根本什么都没有,关于插画师这个岗位其实最多就三页我用自己账号登录了网站看也是一样得,说明这不是什么反爬是个BUG?
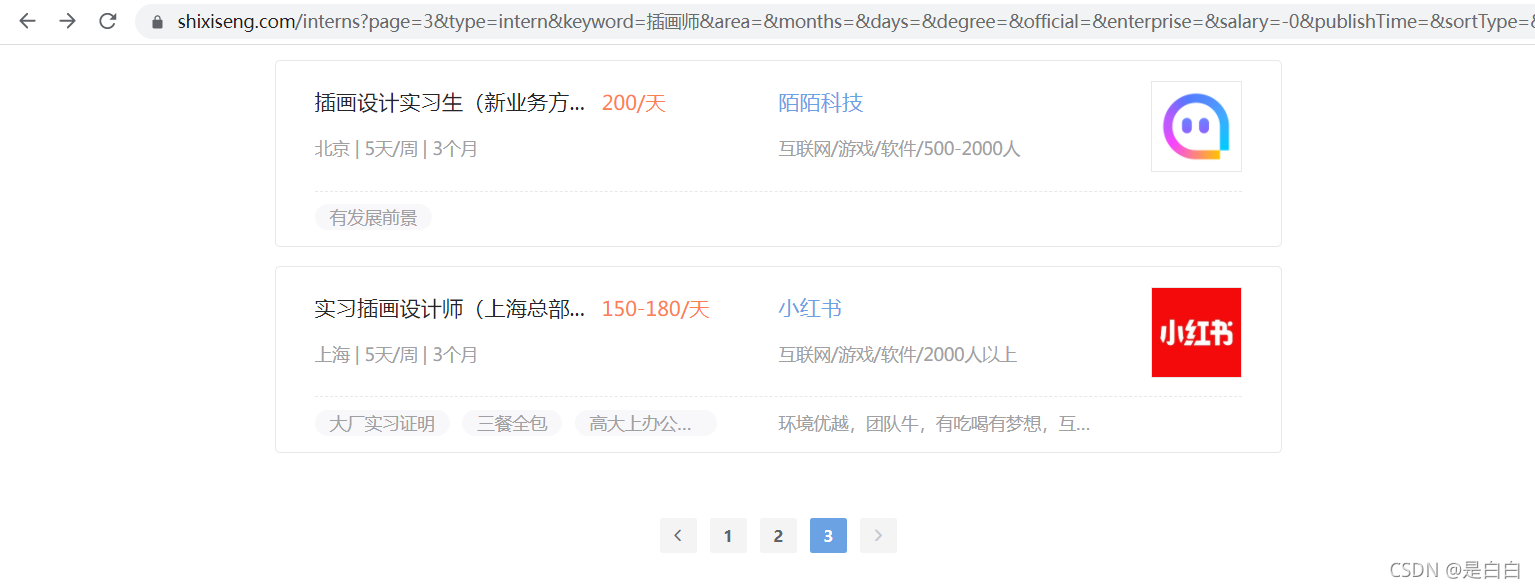
?然后就到非常有意思得地方了,可以看到主页面这里是有字体反爬得我们需要映射字体对吧,

?但是我点进职位详情页发现没有字体反爬,也就是我们直接获取职位得url去提取里面得内容就可以了,不需要去做字体映射得关系,这我就很迷啊?有点摸不着头脑
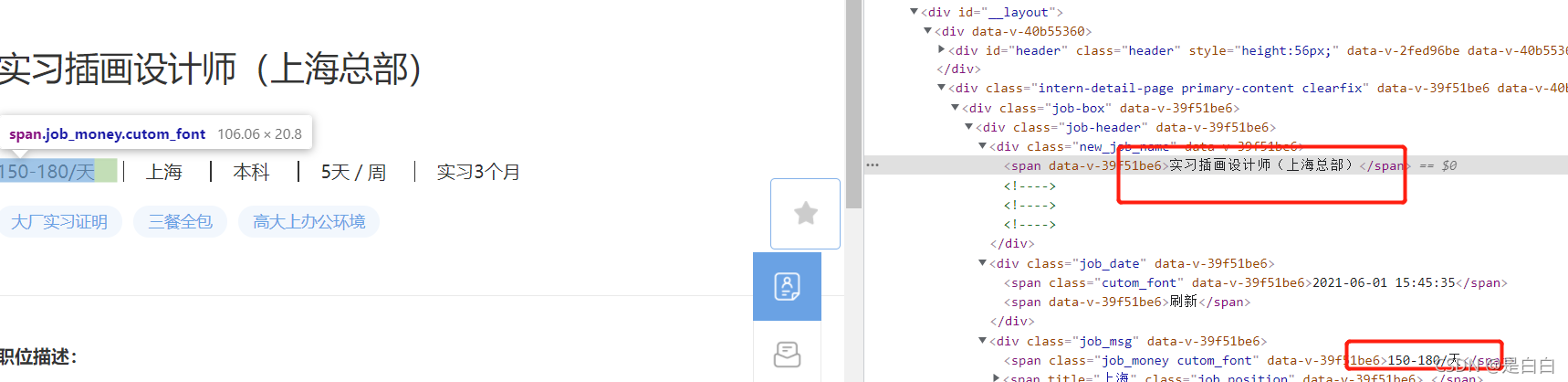
?
?到这里就分析的差不多了,我们先来获取前三页的的url顺便定义好headers
import requests
import random #随机模块
from lxml import etree
import pymysql
UserAgents=[
'Mozilla/5.0 (Windows x86; rv:19.0) Gecko/20100101 Firefox/19.0',
'Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36',
'Mozilla/5.0 (Microsoft Windows NT 6.2.9200.0); rv:22.0) Gecko/20130405 Firefox/22.0',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.17 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36'
] #里面存放的是请求头
user_agent=random.choice(UserAgents) #使用随机请求头
headers = {'User-Agent':user_agent,
'Cookie': '__jsluid_s=20d0f2e1ce22b48592d30b6313d6fea2; gr_user_id=9fb80ce1-f678-432d-af38-3a13139e61c7; utm_source_first=PC; utm_source=PC; utm_campaign=PC; gr_session_id_96145fbb44e87b47=f025cea3-727d-4cb3-9521-8319e0f463c9; gr_cs1_f025cea3-727d-4cb3-9521-8319e0f463c9=user_id%3Anull; Hm_lvt_03465902f492a43ee3eb3543d81eba55=1635827158,1636005802,1636819980,1637234701; gr_session_id_96145fbb44e87b47_f025cea3-727d-4cb3-9521-8319e0f463c9=true; bottom_banner=true; SXS_XSESSION_ID="2|1:0|10:1637234715|15:SXS_XSESSION_ID|48:Y2E4ODY5NmItZDFiYi00MTk0LWEyMmEtMjZmM2U0M2Y2NzYx|1d4bf2d400ca1d9a113f8777afa11c36497905cd30943a08a1aba0b8681fc7d0"; SXS_XSESSION_ID_EXP="2|1:0|10:1637234715|19:SXS_XSESSION_ID_EXP|16:MTYzNzMyMTExNQ==|b3cf3efae0348cd311f896e2e8045bd0cb224d0e6ccace20d95ef101364cdfb7"; Hm_lpvt_03465902f492a43ee3eb3543d81eba55=1637234994',
}
def main():
for x in range(1,4):
url='https://www.shixiseng.com/interns?page={}&type=intern&keyword=%E6%8F%92%E7%94%BB%E5%B8%88'.format(x)
print(url)
if __name__ == '__main__':
main()
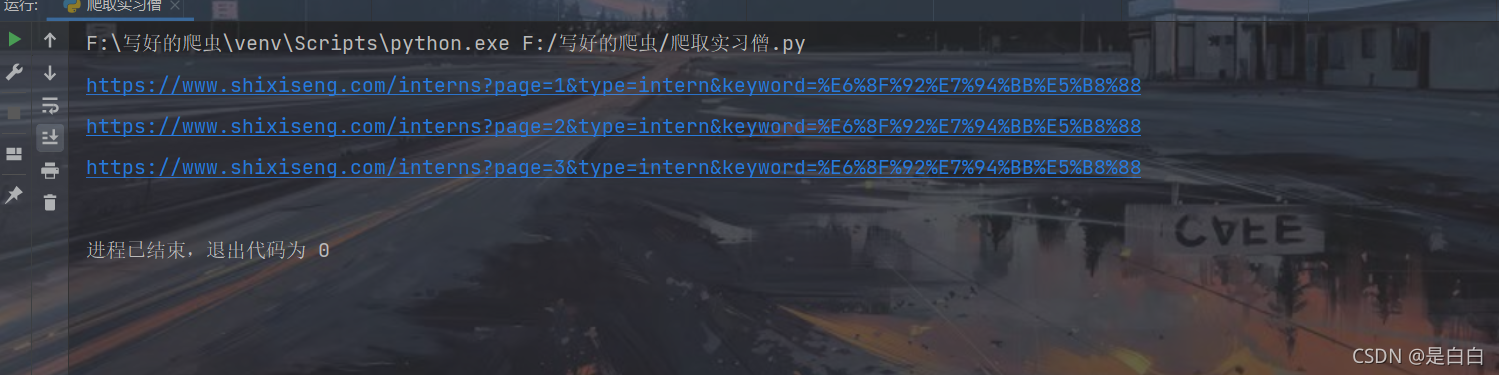
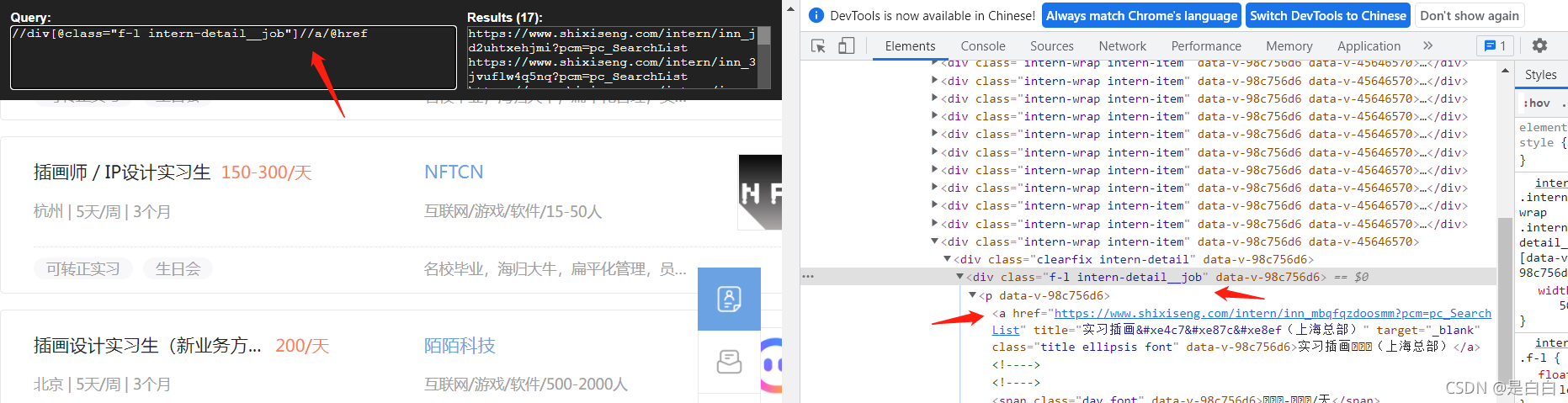
拿到之后自然要去获取详情页的url,我这里用的xpath去获取??不过因为它class面有空格的话你在网页上这样写可以获取到url,但是在程序里面返回的就是空的列表因为它获取不到,在程序里面是这样写的
//div[contains(@class,"f-l intern-detail__job")]//a/@href
def shixi(url):
response=requests.get(url,headers=headers)
content = response.content.decode('utf8')
# 解析html字符串
html = etree.HTML(content)
detail_url=html.xpath('//div[contains(@class,"f-l intern-detail__job")]//a/@href') #获取详情页url
print(detail_url)
?拿到详情页用xpath去解析就好了
def jiexi(url):
response = requests.get(url, headers=headers)
text=response.text
content = response.content.decode('utf8')
# 解析html字符串
html = etree.HTML(content)
titles=html.xpath('//div[@class="new_job_name"]/span//text()') #获取职位名称
# print(titles)
xinzis=html.xpath('//div[@class="job_msg"]/span//text()') #获取薪资那一栏
# print(xinzis)
release_times=html.xpath('//span[@class="cutom_font"]/text()') #获取发布时间
# print(release_times)
job_descriptions =html.xpath('//div[@class="job_detail"]/text()') #获取职位信息
print(job_descriptions)
job_descriptionss=[]
for tt in job_descriptions:
job_descriptionss.append(tt.strip())
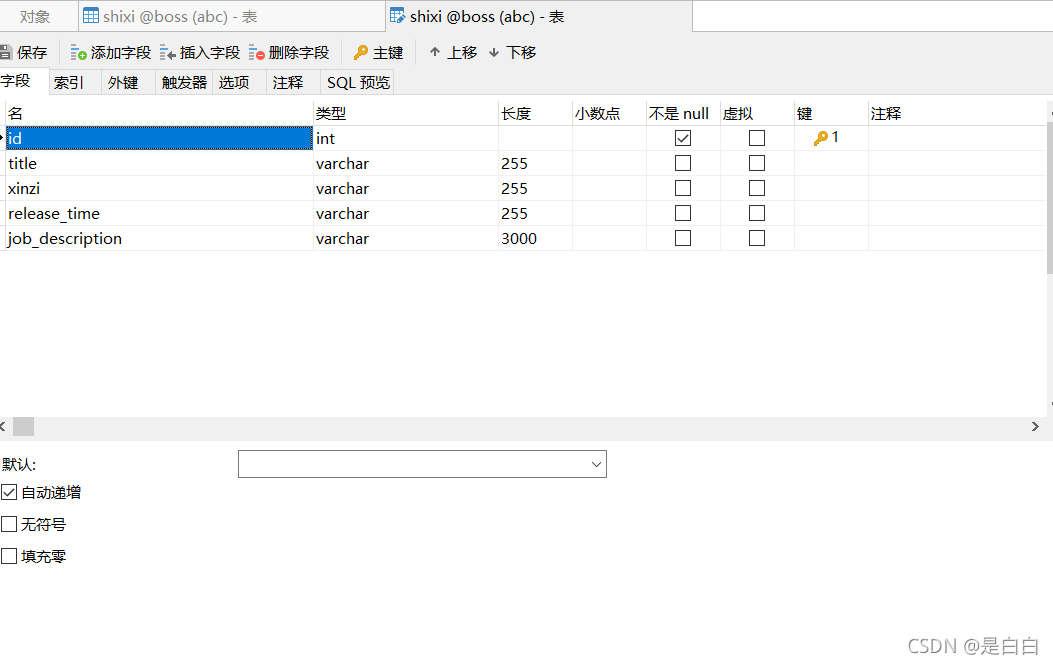
# print(job_descriptionss)解析完接下来就得导入数据库里面去MySQL我们先设计一下表,如果有建id这个字段想看导入了多少数据一定要勾选下面那个自动递增,不然写入的时候会报错的?
?用代码插入的时候到了
for value in zip(titles,xinzis,release_times,job_descriptionss):
title,xinzi,release_time,job_description=value
print(value)
try:
conn = pymysql.connect(
host='localhost', user='root', password='123456', database='boss', port=3306)
cursor = conn.cursor()
spl = '''
insert into shixi(id,title,xinzi,release_time,job_description) values(null,%s,%s,%s,%s)
'''
cursor.execute(spl,(title,xinzi, release_time,job_description))
conn.commit()
print('成功写入'+title)
except:
print('这条数据有问题'+title)
conn.close()不过我们可以看到插入数据库的话,岗位职责哪里永远只会写入第一个标签里面的内容后续的内容是不会写入的,第一个标签为空的话就什么都不写入

开始我还纳闷了是我获取的数据不完整的吗。可是我print(job_descriptionss)发现是获取完整的呀,我试着去打印value诶发现value里面是缺失不完整的只能获取第一个标签里面的内容
 ?
?
这里我一时半会没想明白是什么原因,就问了一下我们站内的专家老师,原因嘛就是我使用的是python内置的zip函数去整合数据,但是这个东西必须是需要长度一致的不然就会数据丢失不完整甚至错误,我举个栗子? ? ?楼下小黑的<age>标签是不是没有东西呀 这就导致了最后获取的长度不一致,解决办法嘛需要用一个判断语句if ... else来保证长度必须一致,哪怕是没有数据也得填一个进去,比如如果<age>里面没有东西那么就填入0? ?但是吧实习僧这个网站我不知道怎么去判断架构很迷,当然也是我太菜了啊(如果有朋友能把这段判断写完,那真是太谢谢了毕竟又能学到点新花样)
<body>
<div class="job_detail">
<name class = '01'>老实人</name>
<age>33</age>
<food>老实</food>
</div>
<div class="job_detail">
<name class = '02'>楼下小黑</name>
<age></age>
<food>不安分</food>
</div>
<div class="job_detail">
<name class = '03'>楼上小王</name>
<age>45</age>
<food>可能会变成老王</food>
</div>
<div class="job_detail">
<name class = '04'>王阿姨</name>
<age>16</age>
<food>小白羊</food>
</div>
</body>

既然Xpath靠不住,换个思路用正则呀,正则可不管你这么多就是写起来会麻烦一点,我们导入数据库的时候只有job_descriptions也就是岗位职责哪里不完整,我们就用正则重写这一段就好了
job_descriptions=re.findall(r'<div class="job_detail" style=".*?" data-v-39f51be6>(.*?)</div>',text,re.DOTALL)#获取岗位职责获取下来也是没有啥问题呀,就是会有很多我们不需要的字符,那么就用正则里面的sub来替换掉 ,这里需要注意的是如果有多个需要替换掉的内容就用 | 来分隔

job_descriptionss=[]
for tt in job_descriptions:
x = re.sub(r'<.*?>|\n|\t| |t3|t1|t2', '',tt) #把不需要的字符替换成空
job_descriptionss.append(x.strip())
print(job_descriptionss)可以看到替换之后就美观多了,具体的可能还会有别的字符,这个就需要你们耐心去找找一起替换了?

?我们在来重新打印value可以看到已经获取完整了,没有数据丢失的情况了呀?
![]()
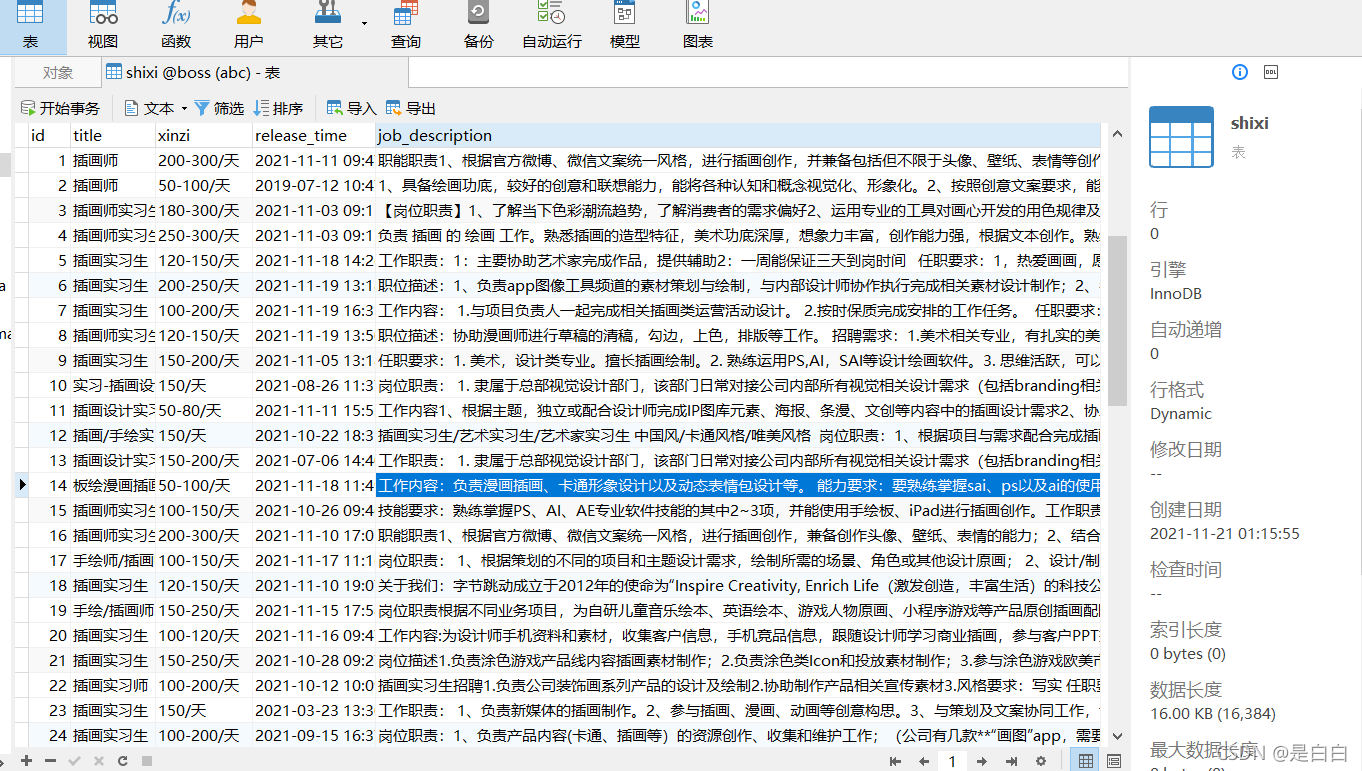
?来看看导入的效果吧
?全部源代码如下
import requests
import random #随机模块
from lxml import etree
import time
import re
import pymysql
UserAgents=[
'Mozilla/5.0 (Windows x86; rv:19.0) Gecko/20100101 Firefox/19.0',
'Mozilla/5.0 (Windows NT 4.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2049.0 Safari/537.36',
'Mozilla/5.0 (Microsoft Windows NT 6.2.9200.0); rv:22.0) Gecko/20130405 Firefox/22.0',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.17 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36'
] #里面存放的是请求头 #不过这里我演示用的,有些浏览器可能版本会比较低级导致返回的数据不正常,换成自己的浏览器请求头即可
user_agent = random.choice(UserAgents) # 使用随机请求头
headers = {'User-Agent': user_agent,
'Cookie': '__jsluid_s=20d0f2e1ce22b48592d30b6313d6fea2; gr_user_id=9fb80ce1-f678-432d-af38-3a13139e61c7; utm_source_first=PC; utm_source=PC; utm_campaign=PC; gr_session_id_96145fbb44e87b47=f025cea3-727d-4cb3-9521-8319e0f463c9; gr_cs1_f025cea3-727d-4cb3-9521-8319e0f463c9=user_id%3Anull; Hm_lvt_03465902f492a43ee3eb3543d81eba55=1635827158,1636005802,1636819980,1637234701; gr_session_id_96145fbb44e87b47_f025cea3-727d-4cb3-9521-8319e0f463c9=true; bottom_banner=true; SXS_XSESSION_ID="2|1:0|10:1637234715|15:SXS_XSESSION_ID|48:Y2E4ODY5NmItZDFiYi00MTk0LWEyMmEtMjZmM2U0M2Y2NzYx|1d4bf2d400ca1d9a113f8777afa11c36497905cd30943a08a1aba0b8681fc7d0"; SXS_XSESSION_ID_EXP="2|1:0|10:1637234715|19:SXS_XSESSION_ID_EXP|16:MTYzNzMyMTExNQ==|b3cf3efae0348cd311f896e2e8045bd0cb224d0e6ccace20d95ef101364cdfb7"; Hm_lpvt_03465902f492a43ee3eb3543d81eba55=1637234994',
}
def shixi(url):
response=requests.get(url,headers=headers)
content = response.content.decode('utf8')
# 解析html字符串
html = etree.HTML(content)
detail_urls=html.xpath('//div[contains(@class,"f-l intern-detail__job")]//a/@href') #获取详情页url
print(detail_urls)
for detail_url in detail_urls:
# print(detail_url)
jiexi(detail_url) #循环去解析返回的职位详情页
time.sleep(random.uniform(1, 3)) #随机暂停
pomes = []
def jiexi(url):
response = requests.get(url, headers=headers)
# print(response.text)
text=response.text
content = response.content.decode('utf8')
# 解析html字符串
html = etree.HTML(content)
titles=html.xpath('//div[@class="new_job_name"]/span//text()') #获取职位名称
xinzis=html.xpath('//div[@class="job_msg"]/span//text()') #获取薪资
release_times=html.xpath('//span[@class="cutom_font"]/text()') #获取发布时间
job_descriptions=re.findall(r'<div class="job_detail" style=".*?" data-v-39f51be6>(.*?)</div>',text,re.DOTALL)#获取岗位要求
# print(job_descriptions)
job_descriptionss=[]
for tt in job_descriptions:
x = re.sub(r'<.*?>|\n|\t| |t3|t1|t2', '',tt)
job_descriptionss.append(x.strip())
# print(job_descriptionss)
for value in zip(titles,xinzis,release_times,job_descriptionss):
title,xinzi,release_time,job_description=value
print(value)
try:
conn = pymysql.connect(host='localhost', user='root', password='123456', database='boss', port=3306)
cursor = conn.cursor()
spl = '''
insert into shixi(id,title,xinzi,release_time,job_description) values(null,%s,%s,%s,%s)
'''
cursor.execute(spl,(title,xinzi, release_time,job_description))
conn.commit()
print('成功写入'+title)
except:
print('这条数据有问题'+title)
conn.close()
def main():
for x in range(1,4):
url='https://www.shixiseng.com/interns?page={}&type=intern&keyword=%E6%8F%92%E7%94%BB%E5%B8%88'.format(x)
shixi(url)
if __name__ == '__main__':
main()
至此程序就全部写完啦?

声明
本文仅限于做技术交流学习,请勿用作任何非法用途!