彼岸图链接: https://pic.netbian.com/new/

用到的库:
import requests #请求网页
from lxml import html #解析网页源代码
import time #时间模块
1.单张图片爬取
首先要知道哪个链接才是图片的下载链接(找到下载链接才能使用代码进行存储)
操作步骤:
①随便点进去一张图片
②按f12检查 点击出现的箭头图标 选中图片
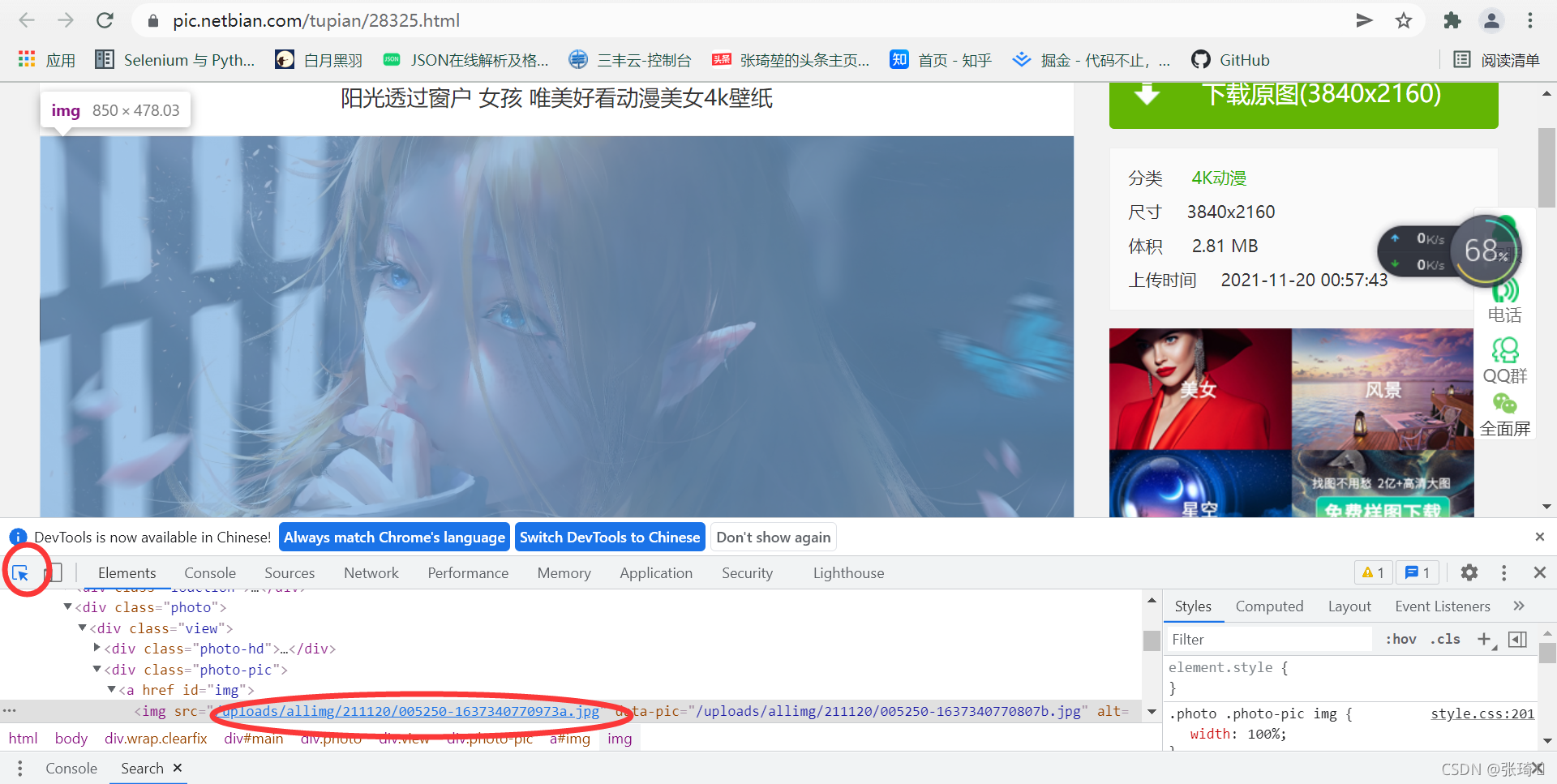
可以看到圈住的后缀为jpg格式的链接就是这张图片的下载链接
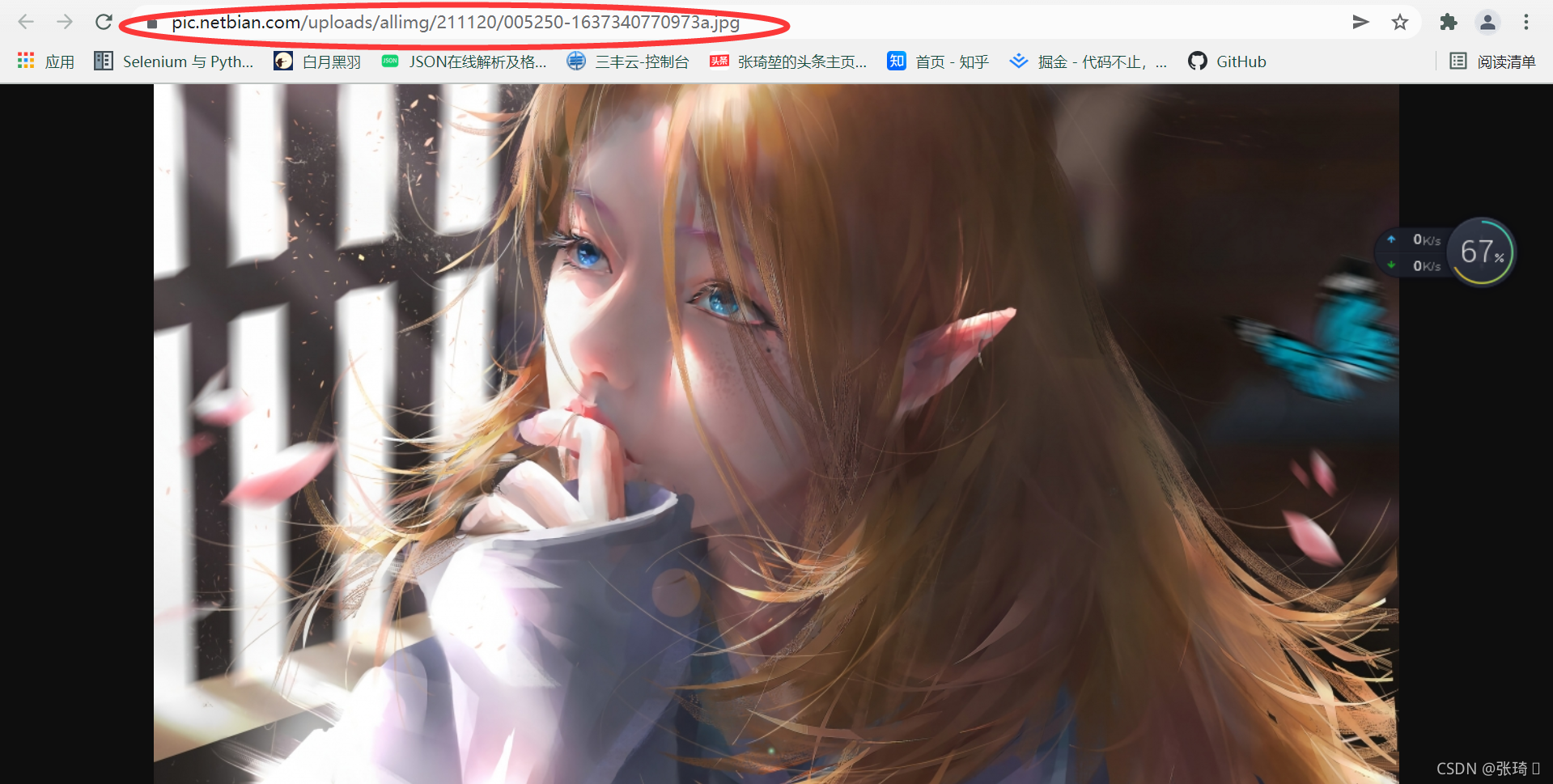
③复制图片下载链接 以下代码:
import requests
# 构造请求头
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4651.0 Safari/537.36",
"cookie":"__yjs_duid=1_0ed165241c418ef3bd1a08a4f18990101634282593810;Hm_lvt_526caf4e20c21f06a4e9209712d6a20e=1634282597; zkhanecookieclassrecord=%2C65%2C54%2C; yjs_js_security_passport=f2c27672aa84310f33e0f25d8859275320f1e1bd_1634284550_js; Hm_lpvt_526caf4e20c21f06a4e9209712d6a20e=1634284830"
}
url = 'https://pic.netbian.com/uploads/allimg/210528/191150-16222003104792.jpg'
con = requests.get(url,headers=headers).content #请求图片链接并转为二进制(注意图片存储必须以二进制格式)
with open('b.jpg','wb') as f:
f.write(con)
完成效果:
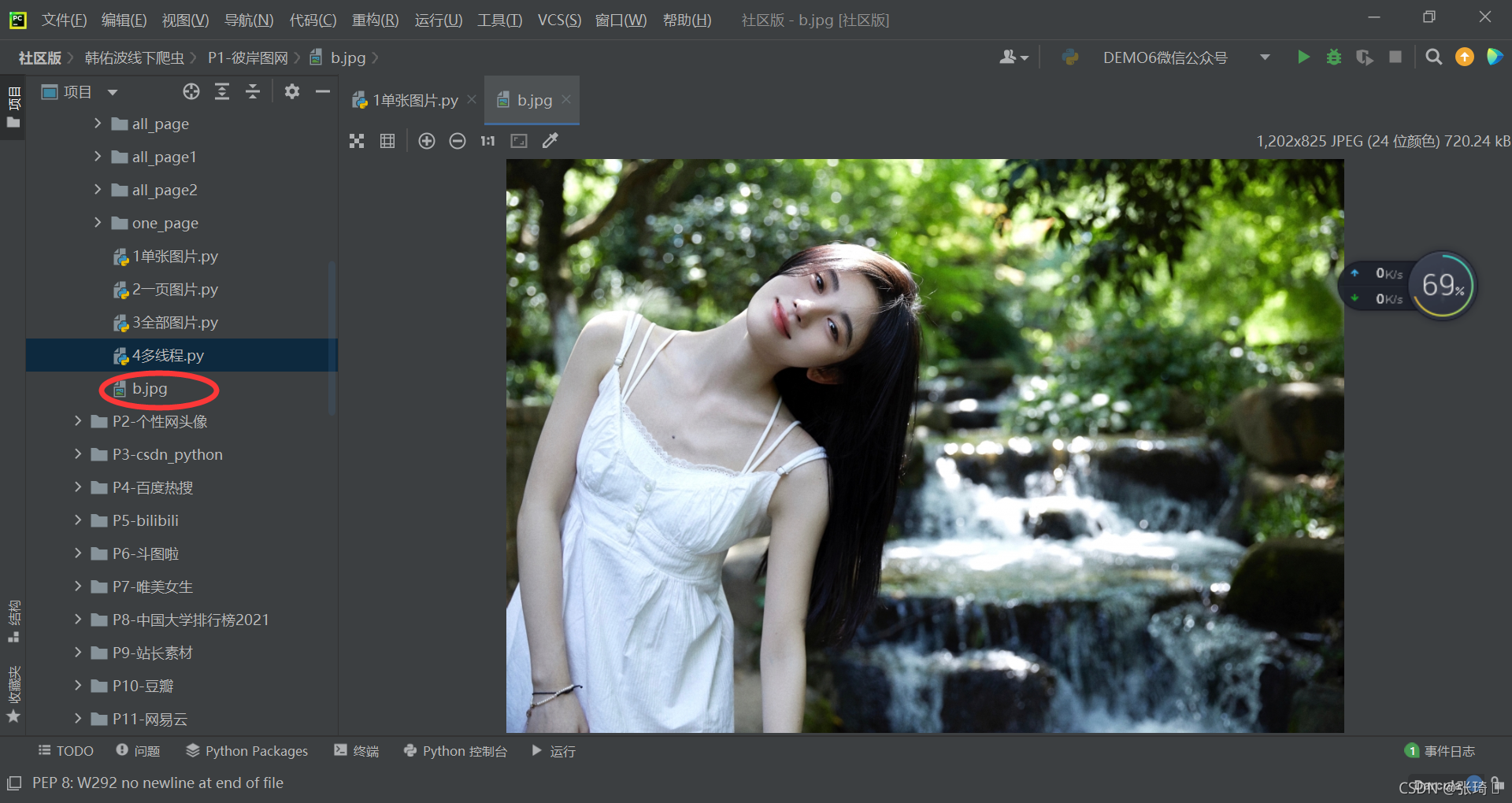
可以看到该脚本下多个以代码中命名的jpg为后缀的图片
看到这一张图片的抓取就完成了
2.一页图片
如果我们还像单张那样获取图片链接就太麻烦了,这次我们用语法直接获取一页图片的下载链接
步骤如下:
先导入要用到的第三方库
import requests #请求目标网页
from lxml import html #对目标网页的源代码进行解析提取
①向目标网页进行请求
url = 'https://pic.netbian.com/new/'
res = requests.get(url).text #请求目标 .text获取网页源代码
dom = html.etree.HTML(res) #解析源代码用于后面我们提取
②f12检查页面
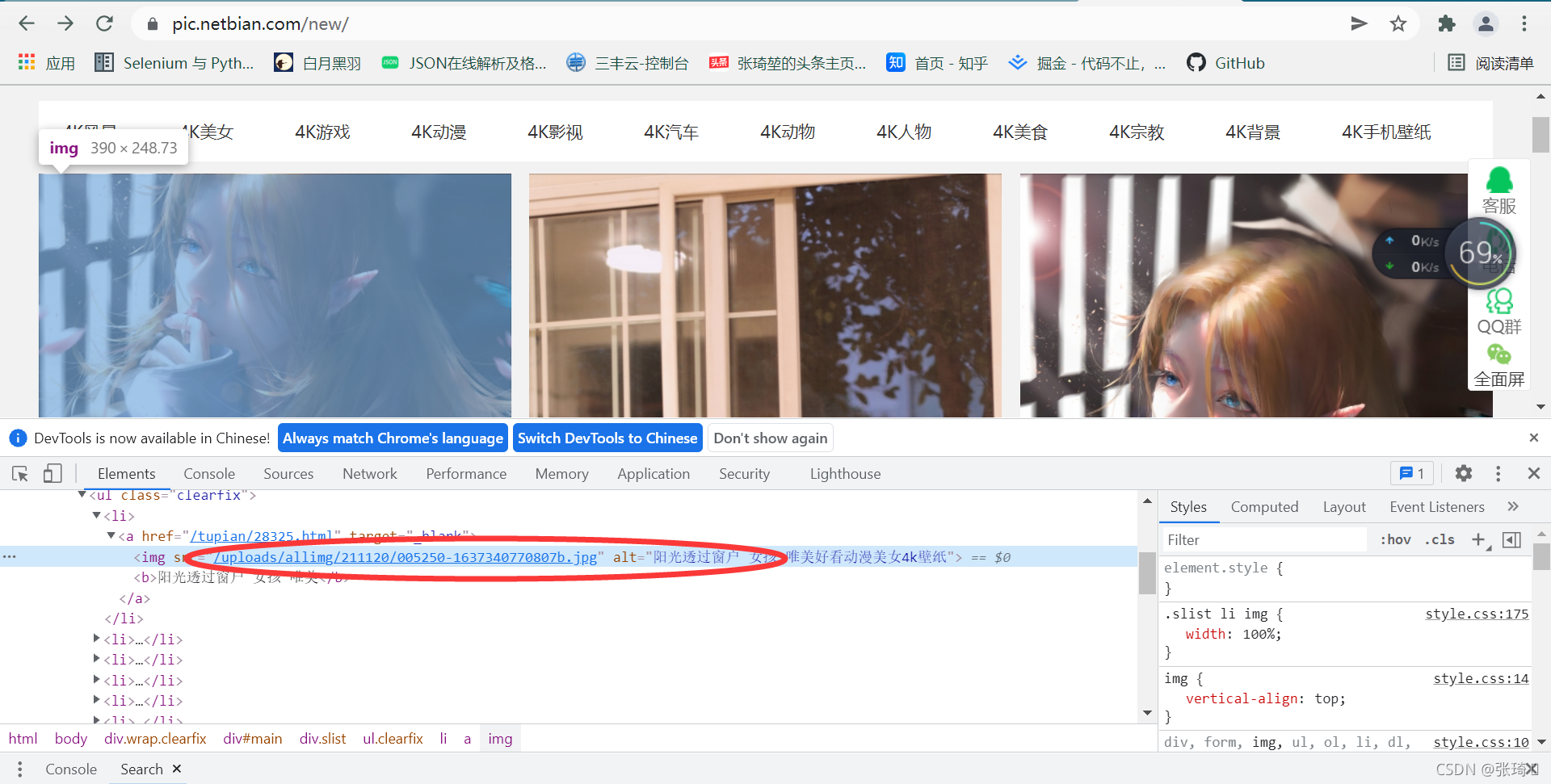
鼠标放到链接那一行右击==>Copy==>Copy XPath
//[@id=“main”]/div[3]/ul/li[1]/a/img #第一张图片
//[@id=“main”]/div[3]/ul/li[2]/a/img #第二张图片
跟第一张做比较可以发现只有li的索引不同
所以:
//*[@id=“main”]/div[3]/ul/li/a/img #获取当前页面索引链接
而我们要找的下载链接是获取img标签的src属性
所以图片下载链接用xpath语法获取为:
//*[@id=“main”]/div[3]/ul/li/a/img/@src (@后跟属性名称 即获取该属性的值)

这是可以看到获取到的链接和图片的真实链接是不一样的
https://pic.netbian.com/uploads/allimg/211120/004848-1637340528f071.jpg
/uploads/allimg/211120/005250-1637340770807b.jpg’
所以给获取到的src属性拼接上前面的域名:
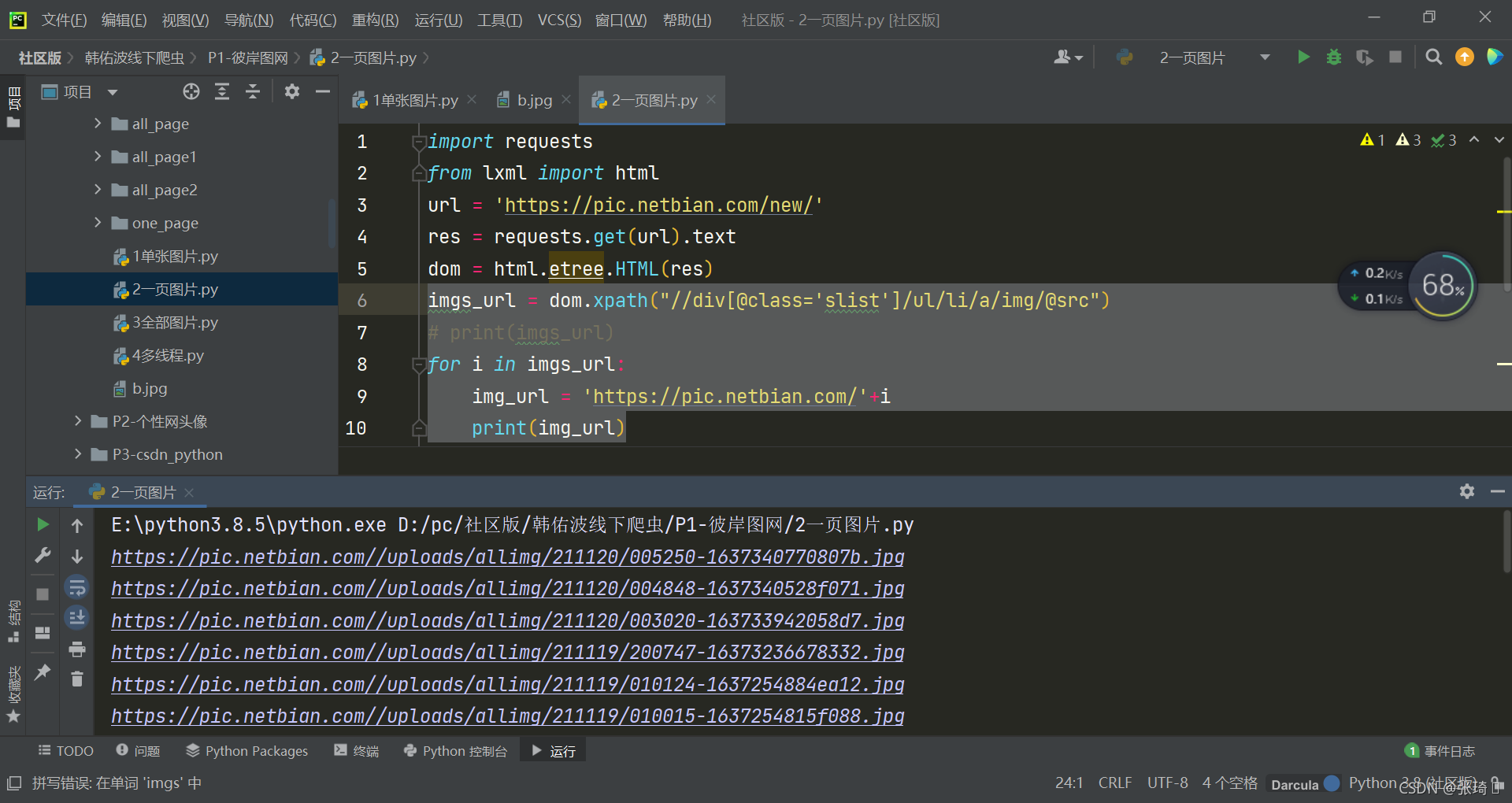
这时候的img_url就是我们要找的下载链接
然后就可以进行存储了
import requests
from lxml import html
url = 'https://pic.netbian.com/new/'
res = requests.get(url).text
dom = html.etree.HTML(res)
imgs_url = dom.xpath("//div[@class='slist']/ul/li/a/img/@src")
# print(imgs_url)
for i in range(len(imgs_url)):
img_url = 'https://pic.netbian.com/'+imgs_url[i]
# print(img_url)
name = 'No'+str(i) #用于命名图片
print('正在存储:'+name)
con = requests.get(img_url).content
with open('one_page/%s.jpg'%name,'wb') as f:
f.write(con)
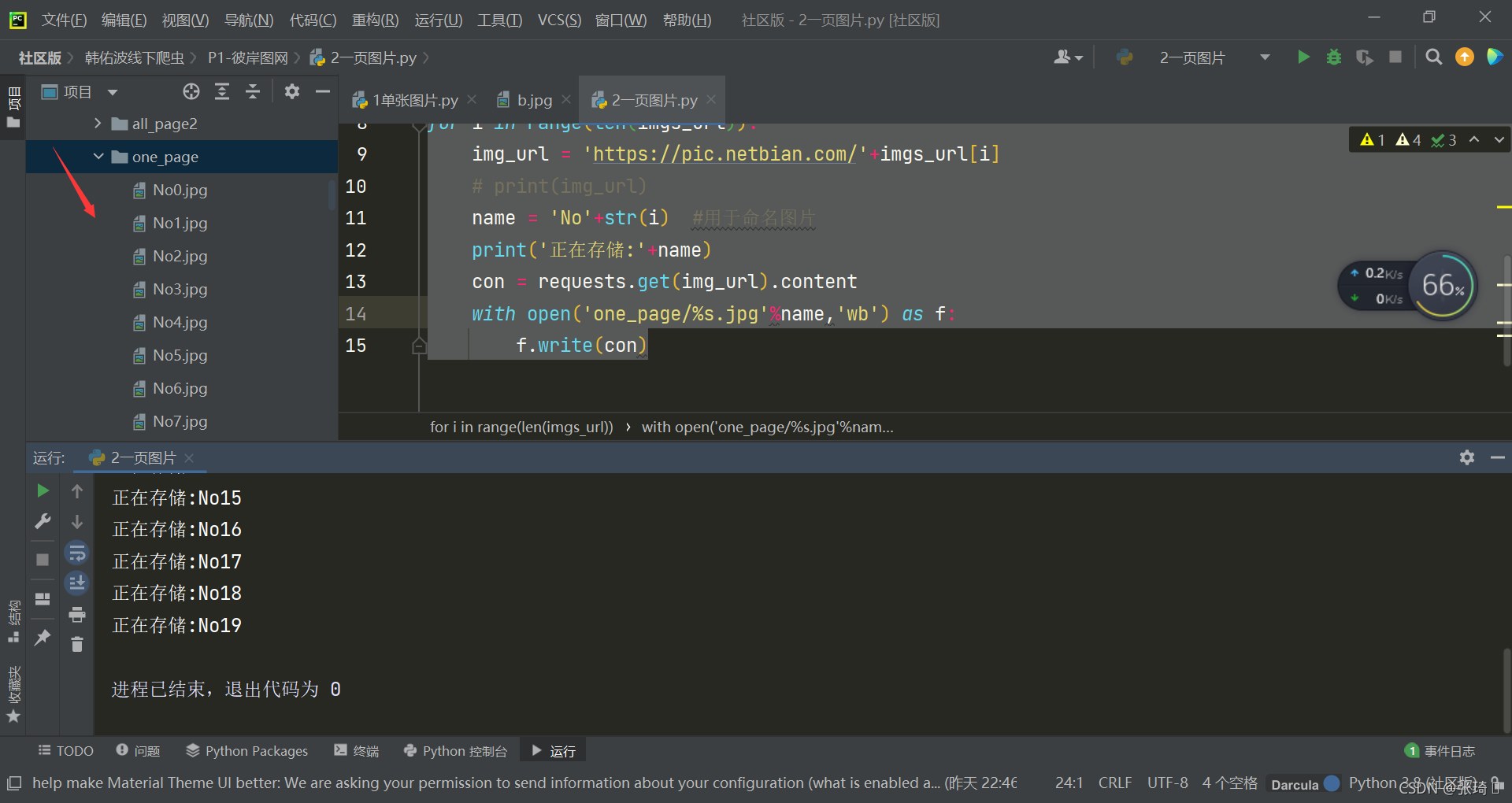
一页的图片就全下载下来了
3.多页图片
我们根据一页图片的写法可以分析得出分别请求目标页然后提取每页的链接就能对多页的图片进行下载
https://pic.netbian.com/new/ 第一页链接
https://pic.netbian.com/new/index_2.html 第二页链接
https://pic.netbian.com/new/index_3.html 第三页
可以看出除了第一页都是有规律的所以可以遍历出每页的链接
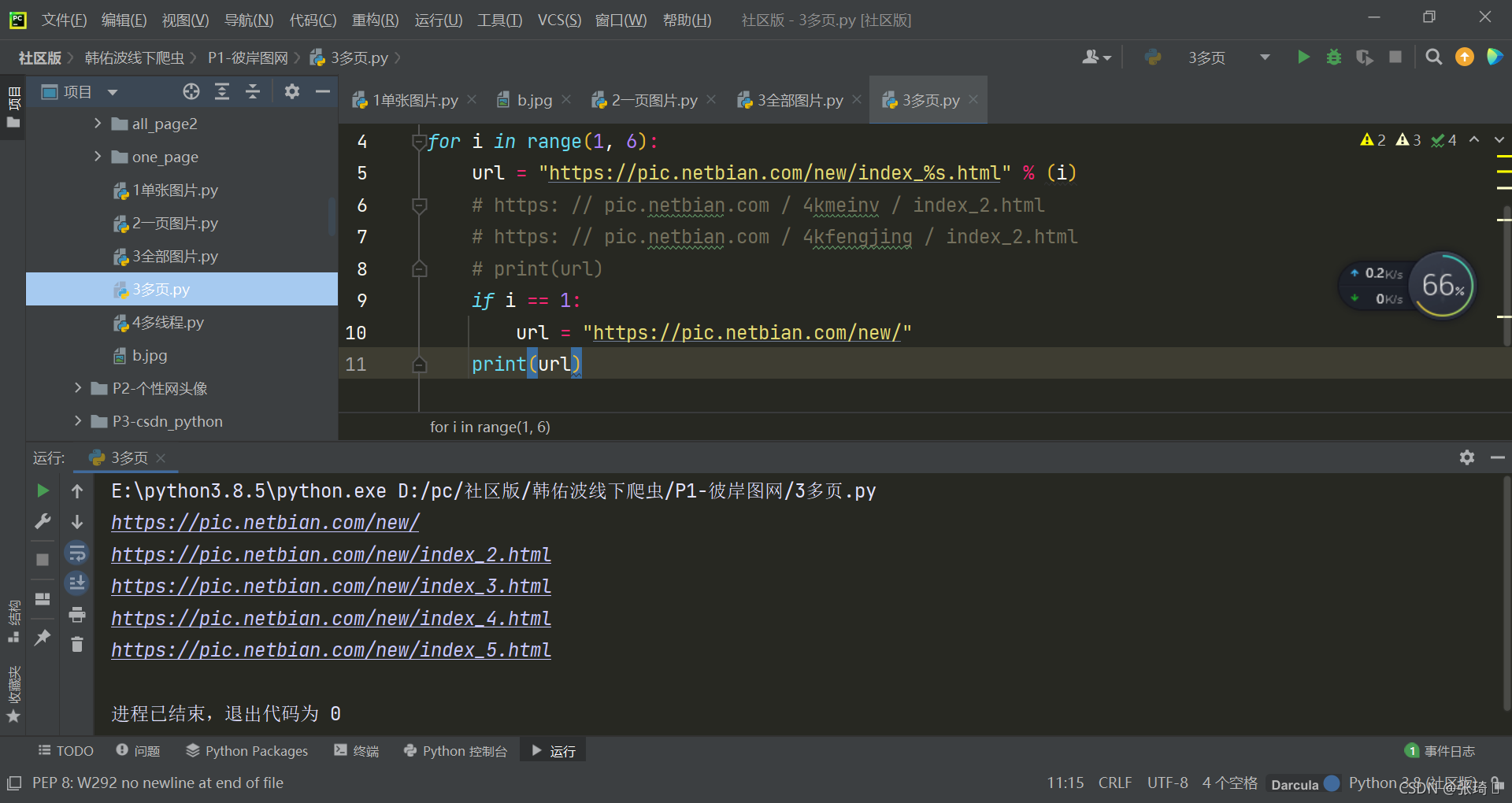
代码如下:`
import requests
from lxml import html
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4651.0 Safari/537.36",
"cookie": "__yjs_duid=1_dd6220b2a3c19e33333239dd66b5da881635232514518; Hm_lvt_14b14198b6e26157b7eba06b390ab763=1636252200,1636252296; Hm_lvt_526caf4e20c21f06a4e9209712d6a20e=1636254461,1636254484,1636333136,1637483174; zkhanecookieclassrecord=%2C54%2C; Hm_lpvt_526caf4e20c21f06a4e9209712d6a20e=1637488659",
}
#只下载前5页内容
for i in range(1, 6):
url = "https://pic.netbian.com/new/index_%s.html" % (i)
if i == 1:
url = "https://pic.netbian.com/new/"
# print(url)
res = requests.get(url,headers=headers)
for i in range(1,6):
if res.status_code != 200:
print('重新加载%s页'%i)
else:
continue
dom = html.etree.HTML(res.text)
imgs_url = dom.xpath("//div[@class='slist']/ul/li/a/img/@src")
# print(imgs_url)
for n in range(len(imgs_url)):
img_url = 'https://pic.netbian.com/' + imgs_url[n]
# print(img_url)
name = 'No' + str(i)+'-'+str(n) # 用于命名图片
print('正在存储:' + name)
con = requests.get(img_url,headers=headers).content
with open('one_page/%s.jpg' % name, 'wb') as f:
f.write(con)
- List item