每日分享:
怎么判断一个人是否合适呢?我觉得,一个合适的人会让你看到和得到全世界,而一个不合适的人会让你失去全世界
博主页面例如下:
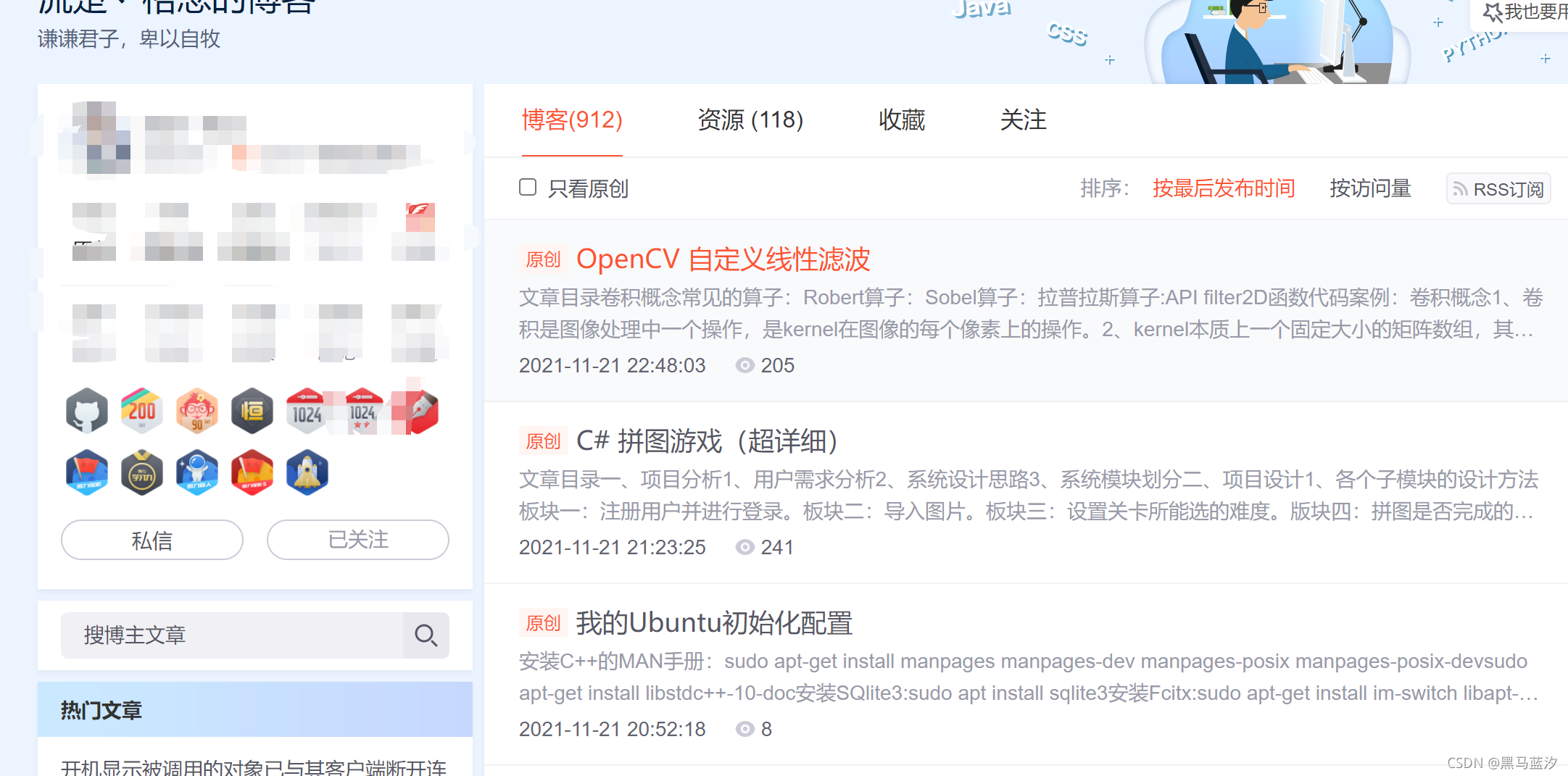
1. 在该页面抓包,并找到如下包:
![]()
?2. 复制它的网址url,观察每一页的网址,发现url的前面都一样,就最后的数字不同;并复制user-agent,请求为get请求。
3. 找到网页中的a标签(包括title和link),方便抓取标题和链接:

注意:本来应该40个结果,而text()之后有80个(如下图):(所以爬虫代码中列表索引为1,(0没有内容))

?观察网址,不缺东西且是40个,没有问题:(爬虫代码中列表索引正常写为0即可)

?源码如下:(博主博客页数决定循环数)
import requests
from lxml import etree
i = 1
# 我访问的博主博客一共23页,观察每一页的网址发现前面都一样,就最后的数字不同
for i in range(24):
url = 'https://yangyongli.blog.csdn.net/article/list/{}'.format(i)
headers = {
'user-agent': '填自己的user-agent内容'
}
response = requests.get(url, headers=headers)
data = response.content
# 去除注释(浏览器给你的内容会注释很多有用代码)
data = data.decode().replace('<!--', '').replace('-->', '')
html = etree.HTML(data)
# 找到网页中的a标签(包括title和link)
el_list = html.xpath('//*[@id="articleMeList-blog"]/div[2]/div/h4/a')
# 输出一页有多少个
print(len(el_list))
# 每一页爬取的结果放到列表里
data_list = []
for el in el_list:
data_list.append(el.xpath('./text()')[1])
data_list.append(el.xpath('./@href')[0])
# 写入txt文件中
f = open('information.txt', 'a', encoding='utf-8')
for j in data_list:
f.write(j)
f.close()
print(data_list)
结果部分截图如下:
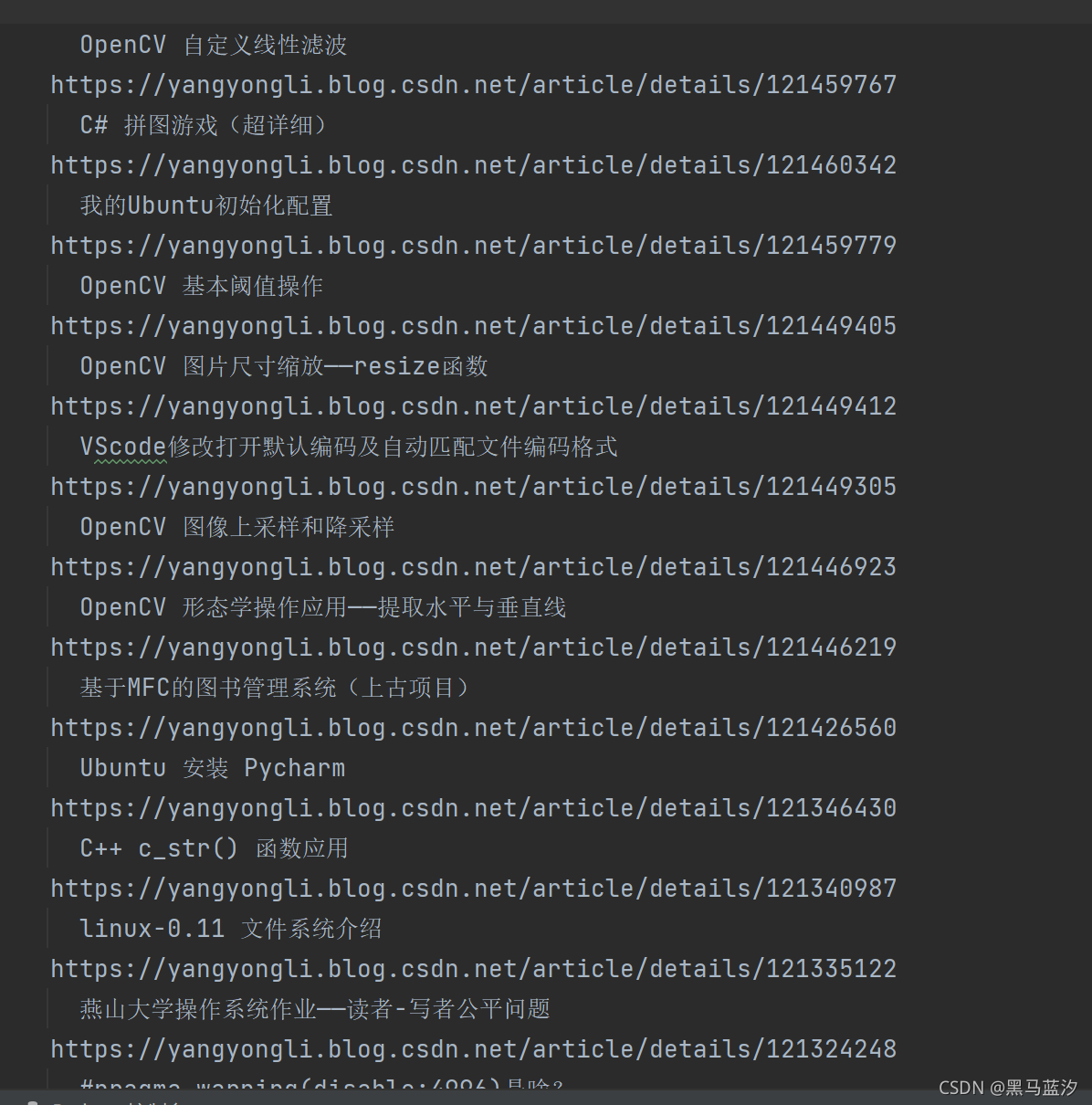
?