目录
一、正则表达式的定义
正则表达式(RE)是一种文本模式,也称为正则表达式模式,用于匹配字符串,通过re模块可使用正则表达式,它可以匹配指定文本中与表达式模式相同的字符串,也可以说是为指定字符串指定相应的规则。
二、元字符
以下是常用的元字符:

(1)点字符
点字符“.”用于匹配字母、数字、下划线、空白符(除换行符\n、\r)等单个的字符,反过来说也就是匹配除了\n、\r以外的任何单个的字符,例如:.A匹配字母A;…匹配任意两个字符;.a表示的是匹配以任意字符开头,以a结尾的字符串。
(2)脱字符和美元符
脱字符“^”和美元符“$”分别用于匹配开头和结尾。例如^ab表示的是匹配以ab开头,第一个字符为a,第二个字符为b的字符串;ab$表示的是匹配以ab结尾,第一个字符为a,第二个字符为b的字符串。
(3)字符组
字符组“[]”用于匹配字符组内任意一个字符,字符组内的字符之间是同级关系,即只会匹配字符组中一个字符,而字符组外的字符是根据由前到后的顺序依次匹配的。例如:a[qwe]匹配的是以字符a开头,且以字符q或w或e结尾的字符串,并不是先匹配以a开头q结尾的字符串;[qwe]r匹配的是以q或w或e字符开头,且以r字符结尾的字符串。
(4)连字符和连接符
连字符“-”用于匹配一个范围,用在字符组中。例如:[A-Z]表示的是匹配A至Z中一位大写字母。
连接符“|”较于字符组,它既能匹配单个字符,又能匹配字符串,匹配一个与表达式模式相同的字符或字符串。例如:a|b|c|d表示的是匹配字符a、b、c、d其中的任意一个字符;12@s|asdd表示的是匹配12@s或asdd。
(5)匹配符
匹配符“?”用于匹配其前表达式零个或一个。
(6)重复
通过使用“+”、“*”、“{}”来重复匹配其前导元素。例如:abc+d是匹配字符c一个或多个,但不可能为0,即不可能为abd;和abc*d不一样,它是匹配字符c零个或多个,所以匹配结果有很多种,比如abd(匹配0个)、abcd(匹配1个)、abccd(匹配2个)……
{}用来限制重复匹配次数,例如:ab{3}c表示的是匹配字符b三次,即匹配的结果是abbbc;也可以限定一个范围设置重复匹配次数,例如:ab{1,4}表示的是匹配字符b一至四次,即匹配的结果可以是ab、abb、abbb、abbbb。
(7)子组
通过子组“()”来对一组字符串中的某些字符进行分组。例如:ab??表示的是匹配子组c零个或一个,匹配结果可以是ab或abc。
三、预定义字符
要注意如果不在预定义字符前加r,则会被视为无效的转义序列,加上r使预定义字符所代表的是字符串而不是转义字符,以下是常用的预定义字符,:

四、re模块
re模块也就是python中的正则表达式模块,这里介绍几个常用的模块函数及方法。
(一)match()函数
re.match()函数会判断目标文本的起始位置是否符合指定模式,若符合匹配成功返回匹配对象,而不符合就会返回None。该函数返回匹配对象中匹配信息span表示匹配对象在目标文本中出现的位置,match表示匹配对象本身内容,另外match()函数有几个参数如下:
re.match(正则表达式,目标文本,匹配模式)
例如下列python代码:
import re
txt0 = "123456ab_"
txt1 = "abr"
txt2 = "HELLOHELLO!"
print(re.match("...", txt0)) # 该正则表达式匹配txt0字符串中任意两个字符
print(re.match("^abr$", txt1)) # 该正则表达式匹配txt1字符串中只有abr的行
print(re.match("HELL[OH]", txt2)) # 该正则表达式匹配txt2字符串中以字符串HELL开头,以字符O或H结尾的字符串
运行结果如下:

(二)search()函数
re.search()函数用于匹配处于目标文本中任意位置的字符串,若匹配成功会返回匹配对象,否则返回None,它的返回匹配对象的匹配信息以及函数的参数与re.match()函数一样。
re.search(正则表达式,目标文本,匹配模式)
例如下列python代码:
import re
txt0 = "12345 6ab_ 9w"
txt1 = "SDDHFHSf9ryu*py"
txt2 = "HELLO WORLD!"
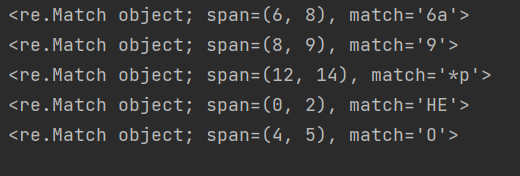
print(re.search("6a", txt0)) # 该正则表达式匹配txt0字符串中为6a的字符串
print(re.search(r"\d", txt1)) # 该正则表达式匹配txt1字符串中的数字
print(re.search(r"\W[p]", txt1)) # 该正则表达式匹配txt1字符串中以特殊字符开头,且以字符p结尾的字符串,
print(re.search("[A-J]+", txt2)) # 该正则表达式匹配txt2字符串中大写字母A至J之间的一位大写字母一次或多次,这里是多次所以返回HE
print(re.search("C|A|O|G", txt2)) # 该正则表达式匹配txt2字符串中字符C、A、O、G中的任意一个,txt2中只有O所以返回O
运行结果如下:
(三)匹配对象
1、Match对象
通过match()函数和search()函数匹配目标文本成功时返回匹配对象,也就是返回了一个Match对象,如下:
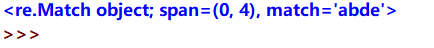
该对象分为span和match,span是一个元组,元组中第一个元素表示匹配对象在目标文本中的开始位置,而第二个元素表示匹配对象在目标文本中的结束位置;match则表示所匹配对象的内容。
2、匹配对象
Match对象在re模块中有一些常用的函数和方法,如下表:
| 名称 | 功能 |
|---|---|
| group([num]) | 获取所匹配的字符串或获取第num个元组的匹配结果 |
| groups() | 获取一个包含所有子组匹配结果的元组 |
| start()和end() | 获取匹配对象的开始和结束位置 |
| span() | 获取span属性,即匹配对象位置的元组 |
例如下列python代码:
import re
text="HELLO WORLD!"
result=re.search(r"\w*",text)
result_groups=re.search("(E)(L)",text)
print(result)
print(result.span())
print(result.start())
print(result.end())
print(result.group())
print(result.groups())#因为不含有元组,所以返回一个空元组
print(result_groups.group())
print(result_groups.group(2))
print(result_groups.groups())
运行结果如下:

(四)compile()函数
若要重复使用一个正则表达式,则可以通过re.compile()函数对其进行预编译,生成一个正则表达式( Pattern )对象,从而避免开销。
其格式如下,Pattern参数表示一个正则表达式,flag参数用于指定匹配的模式,它是可选的:
compile(Pattern(正则表达式),flag) #flag用于指定匹配的模式
常用的匹配模式有以下:
| 参数flag | 功能 |
|---|---|
| re.I | 忽略大小写 |
| re.L | 使预定义字符取决于当前环境设置 |
| re.M | 多行匹配,影响^和$ |
| re.S | 匹配所有字符,其中包括换行符 |
| re.U | 根据Unicode字符集解析字符 |
| re.A | 根据ASCII字符集解析字符 |
| re.X | 更灵活的匹配,忽略空格和注释书写正则表达式 |
例如下列python代码,通过comile()函数将正则表达式"6a"预编译位正则对象p,且设置参数flags为匹配时忽略大小写(re.I),即匹配的结果忽略大小写:
import re
text0="ab c-8955/qasdd"
q=re.compile(r"5\W[a-e]*")#通过comile()函数将正则表达式"5\W[a-e]*"预编译为正则对象q
print(q.search(text0))
text1="12 6A_966-7"
p=re.compile("6a",re.I)#通过comile()函数将正则表达式"6a"预编译为正则对象p,且设置参数flags为匹配时忽略大小写
print(p.search(text1,0,3))#从"1"开始匹配输出None
print(p.search(text1,0,5))
运行结果如下:

(五)findall()函数和finditer()函数
1、findall()函数
findall()函数通过正则表达式匹配字符串,并返回一个列表,若有多个匹配模式则返回元组列表,而若没有匹配到相应的子串则会返回一个空列表。
其格式如下,字符串起始位置和结束位置是可选参数,默认情况下起始位置为0、结束位置为字符串的长度:
findall(正则表达式,字符串,起始位置,结束位置)
例如下列python代码:
import re
text0="abdzeruiio123"
text1="班级:01;人数:50;排名:01"
text2="2*x=0 3/y=12 5+z=3"
q=re.compile(r"[a-g]")
print(q.findall(text0))
print(q.findall(text0,0,3))
print(q.findall(text1))#返回空列表
print(re.findall(r"[\u4e00-\u9fa5]+",text1))#[\u4e00-\u9fa5]为中文的unicode编码范围
print(re.findall(r"(\d.\w)=(\d)",text2))
运行结果如下:

2、finditer()函数
finditer()函数与findall()函数一样,但该函数会将正则表达式所匹配的所有子串以迭代器返回。
例如下列python代码:
import re
text0="abdera*uiio+123"
p=re.compile(r"[a-g]+")
result=re.finditer(p,text0)
print(result)
print(result.__next__())
q=re.finditer(r"\W",text0)
for i in q:#for循环通过group()函数依次输出迭代器
print(i.group())
运行结果如下:

(六)sub()函数和subn()函数
sub()函数和subn()函数用于检索和替换,即用于替换目标文本中的匹配项,前者返回替换后的字符串,而后者返回包括替换结果和替换次数的元组。
两个函数的参数是一样的,前三个参数是必选的,后两个可选,其格式如下,:
sub(正则表达式,要替换的字符串,目标文本,替换次数,匹配模式)
subn(正则表达式,要替换的字符串,目标文本,替换次数,匹配模式)
例如下列python代码:
import re
text="abd1+era"
print(re.sub(r"\d\W","aa",text))
print(re.subn(r"\d\W","aa",text))
运行结果如下,sub()函数通过匹配目标文本中的数字和特殊字符将其替换为“aa”并返回替换后字符串,subn()函数返回字符串和替换次数的一个元组:

(七)split()函数
split()函数用于匹配字符串然后将其分割后返回一个列表,分割的默认次数为0,表示全部进行分割,split()函数的格式如下:
split(正则表达式,目标文本,分割次数,匹配模式)
例如下列python代码:
import re
text="ab de ra"
print(re.split(r"\s",text))
print(re.split(r"\s",text,1))
运行结果如下:

五、贪婪匹配和非贪婪匹配
正则表达式中有两种匹配方式,分别是贪婪匹配和非贪婪匹配,在Python中正则表达式的默认匹配方式为贪婪匹配,贪婪匹配是指在条件满足的情况下尽可能多地进行匹配,当在可匹配或可不匹配时优先尝试匹配;反之非贪婪匹配就是尽可能少地进行分配,当在可匹配或可不匹配时优先尝试忽略。
在使用元字符时默认为贪婪匹配方式,但当元字符与“?”搭配时,则会以非贪婪匹配方式进行匹配。
例如下列python代码,“d.+”匹配以字符d开头后跟单个字符一次或多次,这种是贪婪匹配匹配尽可能多的字符;“d.+?”是非贪婪匹配,只匹配字符d开头后一个字符,其为忽略优先:
import re
text="abderauu"
a=re.search("d.+",text)#贪婪匹配
print(a.group())
a=re.search("d.+?",text)#非贪婪匹配
print(a.group())
运行结果如下:
