写在前面:
此博客仅用于记录个人学习进度,学识浅薄,若有错误观点欢迎评论区指出。欢迎各位前来交流。(部分材料来源网络,若有侵权,立即删除)
免责声明
- 代码仅用于学习,如被转载用于其他非法行为,自负法律责任
- 代码全部都是原创,不允许转载,转载侵权
情况说明
- python爬虫
- 实现了对音乐歌词的爬取
- 实现了对评论的爬取并生成词云图
效果展示
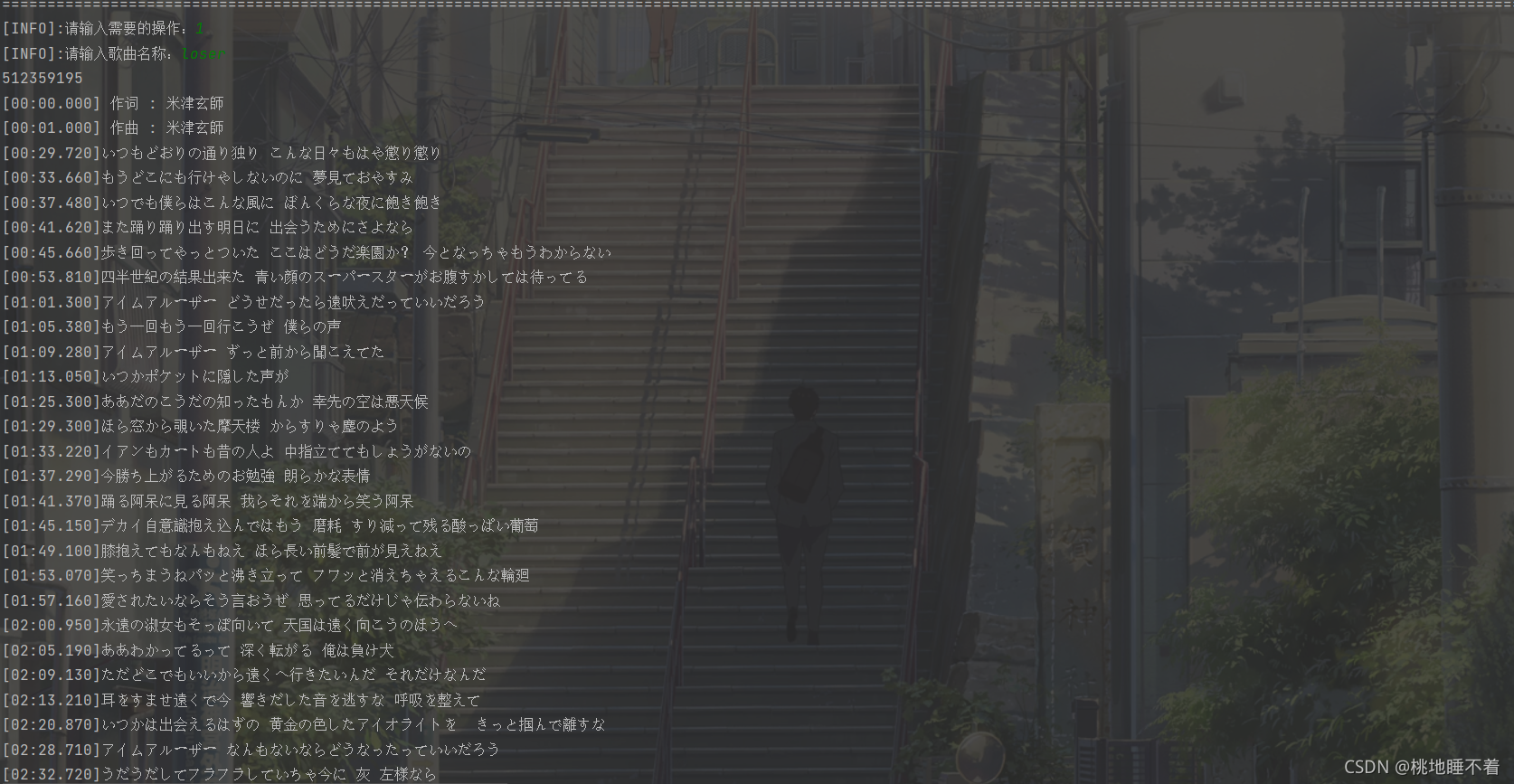
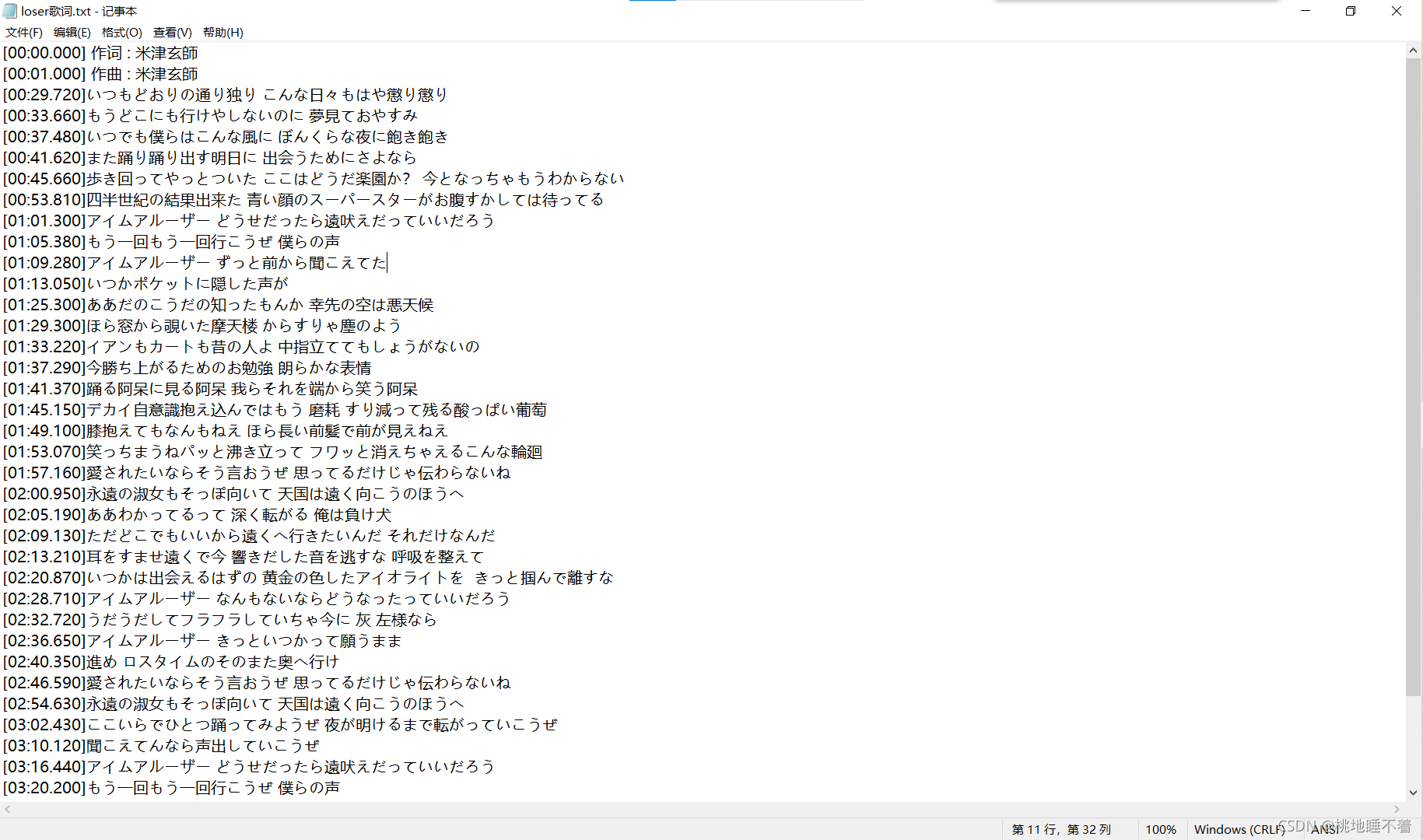
- 菜单

- 1:获取歌词
- 2:歌曲评论词云图


代码讲解
cookie
- 这边使用的是Selenium模拟登录的方法
- 函数如下:
def get_cookies():
driver = webdriver.Firefox()#启动浏览器
url = 'https://music.163.com/'
driver.get(url) # 发送请求
# 打开之后,手动登录一次
time.sleep(3)
input('完成登陆后点击enter:')
time.sleep(3)
dictcookies = driver.get_cookies() # 获取cookies
cookie = [item["name"] + "=" + item["value"] for item in dictcookies]
cookiestr = ';'.join(item for item in cookie)
print(cookiestr)
with open('wyycookie.txt', 'w') as f:
f.write(cookiestr)
print('cookies保存成功!')
driver.close()
- 这一行代码是将driver中获取到的cookie转换成requests能直接使用的格式
cookie = [item["name"] + "=" + item["value"] for item in dictcookies]
cookiestr = ';'.join(item for item in cookie)
- 然后写入文件
with open('wyycookie.txt', 'w') as f:
f.write(cookiestr)
print('cookies保存成功!')
driver.close()
- 读取cookie
def read_cookie():
try:
print("[INFO]:正常尝试读取本地cookie")
with open('wyycookie.txt', 'r', encoding='utf8') as f:
Cookies = f.read()
# print(Cookies)
except:
print("[ERROR]:读取失败,请手动登录并更新")
get_cookies()
read_cookie()
return Cookies
- 这边也有读取的机制和读取失败的机制
歌曲ID
- 网易云每一首歌曲都是有唯一ID的
- 并且网易云的URL中几乎都是用ID进行传参数的
- 所以我们需要将歌名转换成ID
def get_ID(name):
url = 'https://music.163.com/api/search/get/web?csrf_token=hlpretag=&hlposttag=&s={'+str(name)+'}&type=1&offset=0&total=true&limit=1'
r = rs.get(url, headers=headers)
r.encoding = 'utf-8'
str_r=r.text
dict_r = json.loads(str_r)
#print(dict_r)
#print(dict_r["result"]['songs'][0]['id'])
ID=dict_r["result"]['songs'][0]['id']
return ID
获取评论
- 这边找到了一个接口
- 也没使用解析库
- 直接提取出来了
def get_comments(id):
comments=[]
url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_{}?limit=100&offset='.format(id)
r = rs.get(url, headers=headers)
r.encoding = 'utf-8'
str_r = r.text
dict_r = json.loads(str_r)
test=dict_r["comments"][1]
#print(','.join(map(str, sorted(dict_r.keys()))))
#print(test)
for i in range(100):
comment=dict_r["comments"][i]['content']
comments.append(comment)
#print(comment)
# for i in comments:
# print(i)
return comments
获取歌单中的歌曲和ID
- 这个其实不属于本项目
- 但是刚好做了
- 就一起放出来了
def get_list(musiclistid):
Info = []
url = 'https://music.163.com/playlist?id={}'.format(musiclistid)
rs = requests.session()
r = rs.get(url, headers=headers)
soup = BeautifulSoup(r.content, 'lxml')
hide = soup.find('ul', {'class': 'f-hide'})
a = hide.find_all('a')
for every in a:
data = []
uid = re.search(r'id=(.*)', every['href'], re.M | re.I)
uid = uid.group(1)
data.append(uid)
data.append(every.text)
Info.append(data)
# for i in Info:
# print(i[0])
return Info
- 输出的结果就是歌单里的所有的歌名和ID
获取歌词
- 这边也是找到了一个接口
- 然后提取出来
- 并且解析
- 最后保存为txt文本
def get_poem(name,id):
url = 'https://music.163.com/api/song/lyric?id={}&lv=1&kv=1&tv=-1'.format(id)
r = rs.get(url, headers=headers)
r.encoding = 'utf-8'
str_r = r.text
dict_r = json.loads(str_r)
print(dict_r['lrc']['lyric'])
with open(name+'歌词.txt', 'w') as f:
f.write(dict_r['lrc']['lyric'])
print('歌词保存成功!')
分词
def cut_words(top_search):
top_cut=[]
for top in top_search:
top_cut.extend(list(jieba.cut(top))) #使用精确模式切割词汇
return top_cut
生成词云图
- 这个没什么好说的
- 可以参考以前做的豆瓣评论词云图博客
def commment_pic(comment):
all_words = cut_words(comment)
stop = []
words_cut = []
for word in all_words:
if word not in stop:
words_cut.append(word)
word_count = pd.Series(words_cut).value_counts()
back_ground = imread("F:\\flower.jpg")
wc = WordCloud(
font_path="C:\\Windows\\Fonts\\simhei.ttf", # 设置字体
background_color="white", # 设置词云背景颜色
max_words=400, # 词云允许最大词汇数
mask=back_ground, # 词云形状
max_font_size=400, # 最大字体大小
random_state=90 # 配色方案的种数
)
wc1 = wc.fit_words(word_count) # 生成词云
plt.figure()
plt.imshow(wc1)
plt.axis("off")
# plt.get_current_fig_manager().full_screen_toggle()
plt.show()
主菜单
def main():
#print_menu()
while True:
print_menu()
# 获取用户输入
try:
num = int(input("[INFO]:请输入需要的操作:"))
except ValueError:
# except Exception:
print("输入错误,请重新输入(1.2.3)")
continue
except IndexError:
print("请输入一个有效值:(1.2.3)")
continue
# 根据用户的数据执行相应的功能
if num == 1:
name=input("[INFO]:请输入歌曲名称:")
id=get_ID(name)
print(id)
get_poem(name,id)
print("=" * 500)
elif num == 2:
name = input("[INFO]:请输入歌曲名称:")
id = get_ID(name)
comments=get_comments(id)
commment_pic(comments)
print("=" * 500)
elif num == 3:
name = input("[INFO]:请输入歌曲名称:")
id = get_ID(name)
save_music(name,id)
print("=" * 500)
elif num == 4:
print("[END]:感谢您的使用,欢迎下次再见")
print("=" * 500)
break
else:
print("[ERROR]:输入错误")
print("=" * 500)
def print_menu():
print ("="*500)
print ("[INFO]:1. 获取指定音乐歌词")
print ("[INFO]:2. 生成指定音乐评论词云图")
print ("[INFO]:3. 下载歌曲")
print ("[INFO]:4. 退出系统")
print("=" * 500)
最后的主函数
if __name__ == "__main__":
print("=" * 500)
print("[INFO]:欢迎使用zack的网易云音乐系统")
Cookies=read_cookie()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'Cookie': '{}'.format(Cookies)}
main()
代码展示
from lxml import etree
import requests
import time
import json
from selenium import webdriver
from bs4 import BeautifulSoup
import re
import jieba
from wordcloud import WordCloud
import pandas as pd
from imageio import imread
import matplotlib.pyplot as plt
def read_cookie():
try:
print("[INFO]:正常尝试读取本地cookie")
with open('wyycookie.txt', 'r', encoding='utf8') as f:
Cookies = f.read()
# print(Cookies)
except:
print("[ERROR]:读取失败,请手动登录并更新")
get_cookies()
read_cookie()
return Cookies
def get_cookies():
driver = webdriver.Firefox()
url = 'https://music.163.com/'
driver.get(url) # 发送请求
# 打开之后,手动登录一次
time.sleep(3)
input('完成登陆后点击enter:')
time.sleep(3)
dictcookies = driver.get_cookies() # 获取cookies
cookie = [item["name"] + "=" + item["value"] for item in dictcookies]
cookiestr = ';'.join(item for item in cookie)
print(cookiestr)
with open('wyycookie.txt', 'w') as f:
f.write(cookiestr)
print('cookies保存成功!')
driver.close()
rs = requests.session()
def get_comments(id):
comments=[]
url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_{}?limit=100&offset='.format(id)
r = rs.get(url, headers=headers)
r.encoding = 'utf-8'
str_r = r.text
dict_r = json.loads(str_r)
test=dict_r["comments"][1]
#print(','.join(map(str, sorted(dict_r.keys()))))
#print(test)
for i in range(100):
comment=dict_r["comments"][i]['content']
comments.append(comment)
#print(comment)
# for i in comments:
# print(i)
return comments
def get_ID(name):
url = 'https://music.163.com/api/search/get/web?csrf_token=hlpretag=&hlposttag=&s={'+str(name)+'}&type=1&offset=0&total=true&limit=1'
r = rs.get(url, headers=headers)
r.encoding = 'utf-8'
str_r=r.text
dict_r = json.loads(str_r)
#print(dict_r)
#print(dict_r["result"]['songs'][0]['id'])
ID=dict_r["result"]['songs'][0]['id']
return ID
def get_list(musiclistid):
Info = []
url = 'https://music.163.com/playlist?id={}'.format(musiclistid)
rs = requests.session()
r = rs.get(url, headers=headers)
soup = BeautifulSoup(r.content, 'lxml')
hide = soup.find('ul', {'class': 'f-hide'})
a = hide.find_all('a')
for every in a:
data = []
uid = re.search(r'id=(.*)', every['href'], re.M | re.I)
uid = uid.group(1)
data.append(uid)
data.append(every.text)
Info.append(data)
# for i in Info:
# print(i[0])
return Info
def get_poem(name,id):
url = 'https://music.163.com/api/song/lyric?id={}&lv=1&kv=1&tv=-1'.format(id)
r = rs.get(url, headers=headers)
r.encoding = 'utf-8'
str_r = r.text
dict_r = json.loads(str_r)
print(dict_r['lrc']['lyric'])
with open(name+'歌词.txt', 'w') as f:
f.write(dict_r['lrc']['lyric'])
print('歌词保存成功!')
def cut_words(top_search):
top_cut=[]
for top in top_search:
top_cut.extend(list(jieba.cut(top))) #使用精确模式切割词汇
return top_cut
def commment_pic(comment):
all_words = cut_words(comment)
stop = []
words_cut = []
for word in all_words:
if word not in stop:
words_cut.append(word)
word_count = pd.Series(words_cut).value_counts()
back_ground = imread("F:\\flower.jpg")
wc = WordCloud(
font_path="C:\\Windows\\Fonts\\simhei.ttf", # 设置字体
background_color="white", # 设置词云背景颜色
max_words=400, # 词云允许最大词汇数
mask=back_ground, # 词云形状
max_font_size=400, # 最大字体大小
random_state=90 # 配色方案的种数
)
wc1 = wc.fit_words(word_count) # 生成词云
plt.figure()
plt.imshow(wc1)
plt.axis("off")
# plt.get_current_fig_manager().full_screen_toggle()
plt.show()
def main():
#print_menu()
while True:
print_menu()
# 获取用户输入
try:
num = int(input("[INFO]:请输入需要的操作:"))
except ValueError:
# except Exception:
print("输入错误,请重新输入(1.2.3)")
continue
except IndexError:
print("请输入一个有效值:(1.2.3)")
continue
# 根据用户的数据执行相应的功能
if num == 1:
name=input("[INFO]:请输入歌曲名称:")
id=get_ID(name)
print(id)
get_poem(name,id)
print("=" * 500)
elif num == 2:
name = input("[INFO]:请输入歌曲名称:")
id = get_ID(name)
comments=get_comments(id)
commment_pic(comments)
print("=" * 500)
elif num == 4:
print("[END]:感谢您的使用,欢迎下次再见")
print("=" * 500)
break
else:
print("[ERROR]:输入错误")
print("=" * 500)
def print_menu():
print ("="*500)
print ("[INFO]:1. 获取指定音乐歌词")
print ("[INFO]:2. 生成指定音乐评论词云图")
print ("[INFO]:4. 退出系统")
print("=" * 500)
if __name__ == "__main__":
print("=" * 500)
print("[INFO]:欢迎使用zack的网易云音乐系统")
Cookies=read_cookie()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'Cookie': '{}'.format(Cookies)}
main()
- 慢用
- 晚安