前言
初学Python爬虫,记录自己的成长,不喜勿喷
一、受害者
受害者简介:http://tool.liumingye.cn/music(哈哈,嗯,这样是不是不太友好啊),在网上找到一个可以下载部分收费音乐的网站,然后就突发奇想的要把知识运用一下。
二、失败
1.前言
一开始我是想直接用request模块爬的,但最终因为一个加密的步骤没有解决,所以最后退而取其次选择了selenium,真的是有点慢啊。(这里记录一下自己的失败吧),如果有大佬路过希望告知一下解决方法,不胜感激。
2.使用request
进入网站,随便搜一个歌曲。可以发现在下载按钮下面并没有藏着链接。

然后我点击下载按钮,弹出下载框,这下能找到链接了,显然这是一个动态加载出来的。
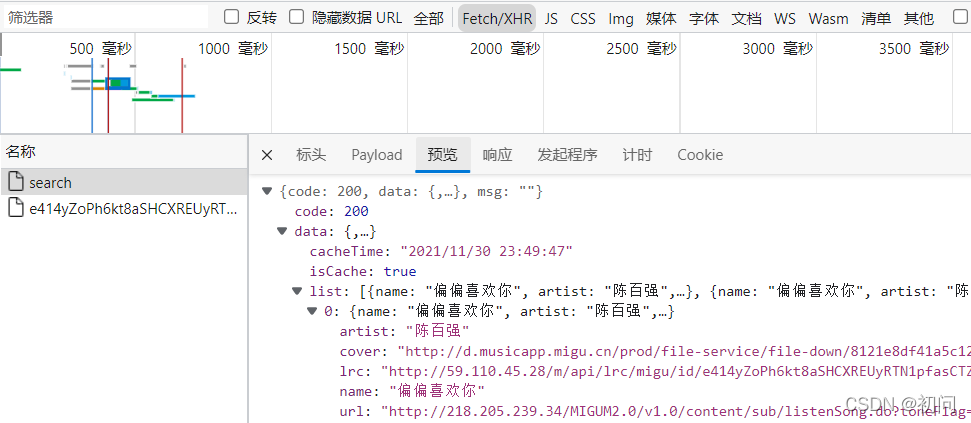
找到XHR在里面发现一个search的请求数据是json字符串。我心想,成了。
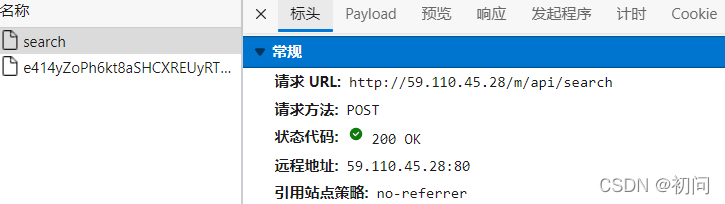
一看请求头,是一个post请求,提交的表单数据是加密了的,我心想,完了。

作为一个初生牛犊不怕虎的人,谁不想搞清楚他的密码呢?然后我就想通过一步一步的设置断点,然后实在没参透它加密的过程。大叹一声,算了!selenium不香吗?
以上就是整个失败过程了,懂的教教我。
三、成功~selenium
前面的装驱动部分就不细说了,网上这样的教程挺多的。把驱动放在python的路径中就行了。 这部分应该是比较简单的了,除了基本上就是打开浏览器,然后通过输入参数,点击按键,提取数据,最终拿到网址,然后下载歌曲。import requests
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
import time
#设置无头浏览器(调试过程中不要打开)
# opt = Options()
# opt.add_argument("--headless")
# opt.add_argument("--disable-gpu")
# web = Chrome(options=opt)
web = Chrome()
web.get("http://tool.liumingye.cn/music/?page=searchPage") #进入初始搜索界面,这一步比较慢
m = input("请输入要下载的歌曲(中间用空格隔开):\n")
musics = m.split(' ') #读入数据,用空格分隔成列表。方便后面遍历下载
for music in musics:
#找到搜索框
search = web.find_element(by="xpath", value='//*[@id="input"]')
#将搜索框中的历史检索词清空掉
search.clear()
#传入关键词,如歌名。后面跟\n回车,就不用在输入完后点击搜索按钮了
search.send_keys('{}\n'.format(music))
time.sleep(1) #这一步是因为,如果浏览器没有加载完就执行下一步find_element会报错,所以得休息1s
#提取音乐及歌手
musicName = web.find_element(by='xpath', value='//*[@id="player"]/div[1]/ol/li[1]/span[4]').text
musician = web.find_element(by='xpath', value='//*[@id="player"]/div[1]/ol/li[1]/span[5]').text
#点击下载按钮,动态加载出链接,然后提取href属性
kk = web.find_element(by='xpath', value='//*[@id="player"]/div[1]/ol/li[1]/span[1]')
kk.click()
link = web.find_element(by='xpath', value='//*[@id="m-download"]/div/div/div[2]/div[4]/div[2]/a[1]').get_attribute("href")
time.sleep(1) #同上
##下面几个步骤是,回到最初搜索界面,方便循环下载歌曲的
web.find_element(by='xpath', value='//*[@id="m-download"]/div/div/div[3]/button').click()
web.find_element(by='xpath', value='//*[@id="main"]/div[1]/div[2]/a[2]').click()
通过提取的url下载并保存歌曲
rques = requests.get(link)
resp = rques.content
rques.close()
with open('Music/{}-{}.mp3'.format(musicName, musician), mode='wb') as f:
f.write(resp)
print("{}----下载完成".format(music))
web.close()
总结
总的来说,这个爬虫没有什么意义,里面没有多线程或协程,就当是练习吧。