前言
目录:0x00 - Python学习笔记
上一篇中提到列表和元组的一部分知识,他们非常相似,因为他们同属于序列。
序列是指一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(称为索引)访问它们。
他们中的成员还有:字符串、列表、元组、集合和字典。
他们的操作包括:索引、切片、加、乘、检查成员。
但要注意的是:集合和字典不支持索引、切片、相加和相乘操作。
字符串的序列属性
- 索引
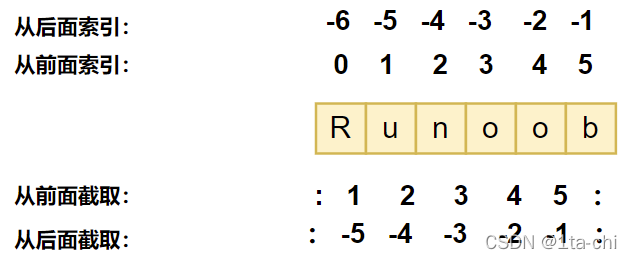
>>> str1 = 'ctf_is_fun!'
>>> str1[2]
'f'
- 切片
>>> str1 = 'ctf_is_fun!'
>>> str1[2:5]
'f_i'
>>> str1[:5]
'ctf_i'
>>> str1[2:]
'f_is_fun!'
>>> str1[:]
'ctf_is_fun!'
- 加
使用加和切片的方法更新字符串
>>> str1 = 'ctffun!'
>>> str1 = str1[:3] + '_is_' + str1[3:]
>>> str1
'ctf_is_fun!'
其他方法
在Python3中所有的字符串都是Unicode字符串
>>> dir(str)
['__add__', '__class__', '__contains__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__',
'__getattribute__', '__getitem__', '__getnewargs__', '__getslice__', '__gt__', '__hash__', '__init__',
'__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__',
'__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'_formatter_field_name_split', '_formatter_parser', 'capitalize', 'center', 'count', 'decode',
'encode', 'endswith', 'expandtabs', 'find', 'format', 'index', 'isalnum', 'isalpha', 'isdigit',
'islower', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'partition',
'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines',
'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
它的作用只是返回相应形式,原字符串并不被修改
- 转大写
upper
>>> str1 = 'Hello world!'
>>> str1.upper()
'HELLO WORLD!'
>>> str1
'Hello world!'
- 转小写
lower
>>> str1 = 'Hello World!'
>>> str1.lower()
'hello world!'
- 首字母大写
capitalize
>>> str1 = 'hello'
>>> str1.capitalize()
'Hello'
>>> str1
'hello'
# 改变
>>> str1 = str1.capitalize()
>>> str1
'Hello world'
- 每个单词首字母大写
title
>>> str1 = 'hello world!'
>>> str1.title()
'Hello World!'
解码常用
既然是网络安全,自然会用到一些常用的便于解码的函数
- 统计次数
统计str在string中出现的次数:count(str, start= 0,end=len(string))
>>> str1 = 'asdqweadsadvsdasdcasdqqwecxz'
>>> str1.count('a')
5
>>> str1.count('a',3,20)
4
- 编码与解码
使用encode(编码类型)和decode(编码类型)编码与解码,其中还有其他默认参数,这里不做介绍
>>> str1 = 'flag{ctf_is_fun}'
>>> str1_base64 = str1.encode('base64')
>>> print('base64_encode:'+str1_base64)
base64_encode:ZmxhZ3tjdGZfaXNfZnVufQ==
>>> print('base64_decode:'+str1_base64.decode('base64'))
base64_decode:flag{ctf_is_fun}
- 检查是否有字母、数字组成
str.isalnum()
>>> str1 = 'lalalalalal'
>>> str2 = 'lalala..lal'
>>> str1.isalnum()
True
>>> str2.isalnum()
False
- 检查仅有数字组成
str.isdigit()
>>> str1 = '123456'
>>> str2 = '123546a'
>>> str1.isdigit()
True
>>> str2.isdigit()
False
- 返回字符串长度
len()
>>> str1 = 'asdqweadsadvsdasdcasdqqwecxz'
>>> len(str1)
28
在其他序列中,它用于返回元素个数
>>> tuple1 = (1, 2, 3, 4, 5, 8, 7, 6, 'asd')
>>> len(tuple1)
9
- 替换字符
str.replace(old, new[, max])将old替换为new,第三个参数指定范围
>>> str1 = 'asd sd qwe v d asd qwe g asd a'
>>> str1.replace(' ','-')
'asd-sd-qwe-v-d-asd-qwe-g-asd--a'
# 去十六进制的空格
>>> str1 = '02 12 45 48 32 15 45'
>>> str1.replace(' ','')
'02124548321545'
格式化
format
未知参数格式化
>>> "{0}_{1}_{2}".format('ctf','is','fun')
'ctf_is_fun'
关键字参数
>>> "{b}_{a}_{c}".format(a='is', b='ctf', c='fun')
'ctf_is_fun'
混合使用
>>> "{0}{{{b}_{a}_{c}}}".format('flag', a='is', b='ctf', c='fun')
'flag{ctf_is_fun}'
- 格式化符号
使用一些符号试字符串格式化,这是字符串独有的方式
| 符号 | 说明 |
|---|---|
%c | 个书画字符及ASCII码 |
%s | 格式化字符串 |
%d | 格式化整数 |
%o | 格式化无符号八进制数 |
%x | 格式化无符号十六进制数 |
%X | 格式化无符号十六进制数(大写) |
%f | 格式化定点数,可指小数后的精度 |
%e | 用科学计数法格式化定点数 |
%E | 同上 |
%g | 根据值的大小决定使用%f或%e |
%G | 同上 |
%c
>>> '%c%c%c%c' % (102,108,97,103)
'flag'
%d
>>> '%d + %d = %d' % (3, 2, 2+3)
'3 + 2 = 5'
>>> '%d' % 0x10
'16'
- 两个有趣的转义符
八进制:\o
十六进制:\x - 三个序列间的转换
# 用list将其他序列幻化为列表
>>> str1 = 'asdasd'
>>> list1 = list(str1)
>>> list1
['a', 's', 'd', 'a', 's', 'd']
>>> tuple1 = (1, 2, 3, 4, 5, 6)
>>> list2 = list(tuple1)
>>> list2
[1, 2, 3, 4, 5, 6]
# 用tuple将其他序列转化为元组
>>> list1 = [1, 2, 3, 4]
>>> tuple1 = tuple(list1)
>>> tuple1
(1, 2, 3, 4)
>>> str1 = 'asd123'
>>> tuple2 = tuple(str1)
>>> tuple2
('a', 's', 'd', '1', '2', '3')
# 最后一个有点魔幻,仅作参考
>>> list1 = [12, 45, 'asd']
>>> tuple1 = (555, 'qwe', 'z123')
>>> str1 = str(list1)
>>> str2 = str(tuple1)
>>> str1
"[12, 45, 'asd']"
>>> str2
"(555, 'qwe', 'z123')"