��pythonʵ�ֶ�дexcel�ļ�
һ������xlrd��xlwt��
pipi��װָ��
$ pip install xlrd
$ pip install xlwt
����ʵ��Ч��
ʵ�ֵĹ���Ϊ:��"��Ч.XLS"excel�ļ���ÿ�����ڲ�ͬ�еĽ����,ȫ���ۼ�����,Ȼ�浽��new.XLS���±����ж�Ӧ���������±���C�� ����(��һ��) �ܽ��(�ڶ���)
(��ȡ"��Ч.XLS"excel,�����ݽ����������ŵ���new.XLS����excel�С�)
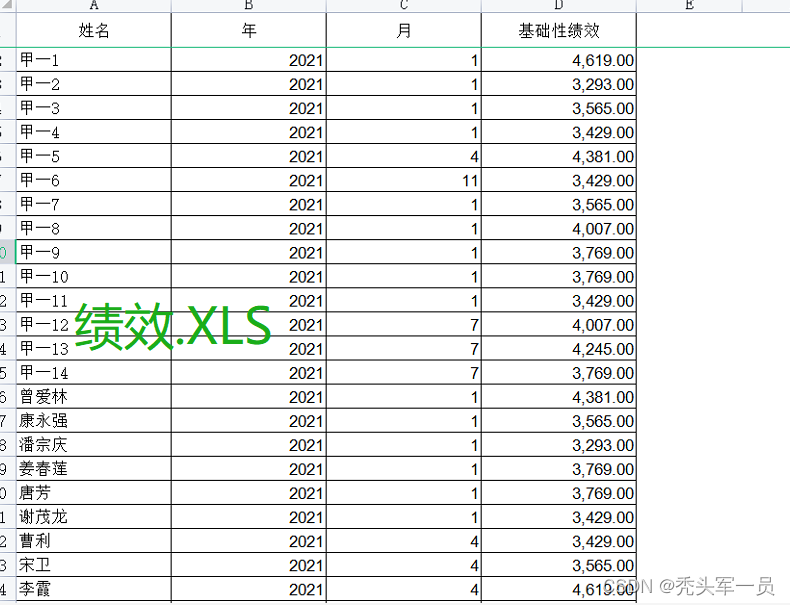
(��Ч.XLS)
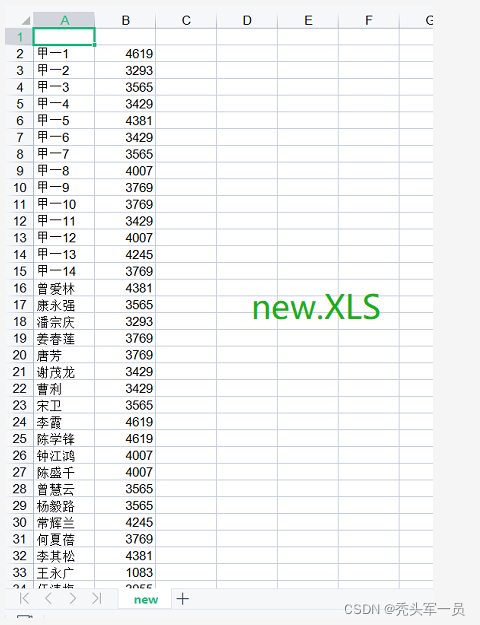
(new.XLS)
��������ʵ�ִ���
import xlrd
import xlwt
# ��ȡexcel�ļ�
datas = xlrd.open_workbook(r'F:\excel\��Ч.XLS') # ��һ������Ϊ��policy.xlsx����excel�ļ�
# ��ȡ����sheet����
table = datas.sheets()[0] # ͨ���±�ȡ��ͬ��sheet��
# table=datas.sheet_by_name('sheet1') #����ͨ��sheet�������ȥѡ�����ı�
# sheet_name = datas.sheet_names() # �ҳ����еı���
nrows = table.nrows # ����һ��sheet�������е�����
ncols = table.ncols # ����һ��sheet�������е�����
# ��excel����д������,�ȴ�(����)һ����excel,�½�����,��������,���
# �½�excel
wb = xlwt.Workbook() # ��һ����excel�ļ�,ע�������Workbook,��һ��W�Ǵ�д
# �½�����
ws = wb.add_sheet('new') # ����һ������,Ҳ��������Ϊ��������һ������
index = 0
last_name = "1" # ������ʱ�������
shuzu_name = {} # ���������
shuzu_sum = {} # �����money
# ʵ�ֵĹ���Ϊ:��excel�ļ���ÿ�����ڲ�ͬ�еĽ����,ȫ���ۼ�����,Ȼ�浽�±����ж�Ӧ���������±���--�� ����(��һ��) �ܽ��(�ڶ���)
for rownum in range(1, nrows): # ѭ��ȡֵ���������е��������,�����1��ʼ���ų��ļ��еĵ�һ�б���
row = table.row_values(rownum) # ͨ��ָ������ȡ��ÿһ�е�ֵ
policy_name = str(row[0]) # ���� # row[0]��ʾ��һ������
money = int(row[3]) # money # ��� # row[3]��ʾ�����н��
if policy_name == last_name: # ����������һ�γ��ֹ�,�����Ӻ��¼
shuzu_sum[index] += money
last_name = policy_name # ��ʱ�洢����,��������Ա�
else: # ��������δ���ֹ�,��index��ǰһλ,���ڶ���һ����Ԫ�صĴ洢,�洢policy_name,���洢��ʼ���
index += 1
shuzu_name[index] = policy_name
shuzu_sum[index] = int(money)
last_name = policy_name
# �������ݵ������½���excel������ȥ,ѭ����������,�ܽ��,����Ϊ����ֵ,ÿ�в���һ���˵���Ϣ,����Ϊ����,����ÿ���˵��������ܽ��
for rowindex in range(1, index + 1):
ws.write(rowindex, 0,
shuzu_name[rowindex]) # ws.write(����, ����, �����ֵ) �����������: rowindx(��ʾ��),0��ʾ��,shuzu_name[rowindex]��ʾ��������ݡ�
ws.write(rowindex, 1, shuzu_sum[rowindex])
# �����½���excel(���仰˵,�ڵ�ǰĿ¼��,��ָ����Ŀ¼���½�һ������,����������)
wb.save(r'F:\excel\new.XLS') # �������
�ġ���β
��ƪΪpythonʵ��excel�����ļ�¼,���������,���岻����ɿ�ע�͡�
������,�Ϲ��,��ͺͷ ��־,����Ϊ���˱ʼ�,Ҳ��Ϊ�������,��ҿ��Բο�ʹ��,������Ҳ���������
�������½���ȨΪ��������,ԭ��ȨΪ��������~