前面的文章通过源代码详解Cerebro是中心系统,负责控制各个部件(例如Strategy,Data feeds,Observers等)进行协同工作。
简而言之,量化最重要的就是两点:数据和策略,其他的都是辅助。下面我们从数据相关类入手,深入学习backtrader中数据的保存以及运作机制。
在系列文章3中,已经说明过加载数据的几种方式,在我们的示例中,采用的是加载Pandas数据方法:
stock_hfq_df = pd.read_csv("../data/sh000300沪深300.csv",index_col='date',parse_dates=True)
start_date = datetime(2021, 9, 1) # 回测开始时间
end_date = datetime(2021, 9, 30) # 回测结束时间
data = bt.feeds.PandasData(dataname=stock_hfq_df, fromdate=start_date, todate=end_date) # 加载数据
为啥要使用Pandas方式输入数据呢?主要考虑到Pandas方便进行数据的预处理,而且目前常用量化数据python自动获取模块(例如akshare)返回的都是Pandas格式数据,为了后续直接获取数据方便处理,我们统一使用PandasData进行说明。
由于数据相关类众多,关系错综复杂,我们先从他们的关系入手。
数据家族关系图谱

牢牢记住这个图喔,这是咱们的家谱。
Note:图中类名后面加标号直接和未加标号同名类定义完全相同,比如LineRoot1和Lineroot是相同的。主要是为了图形清爽,不然太多交叉,看不清楚。
吐槽下csdn,居然不支持SVG,不太清晰,应该也能看清。
PandasData的实例化
在学习初始化代码之前,请大家回去看看系列文章3中关于元类的描述,其中两点这里重复一下:
- 所有类实例化的时候通过元类的__call__完成,不同的类可以在实例化的时候进行一些特殊化的处理(也就是可以控制类的生成)。
- 参数通过donew完成映射。
请看数据类关系图中PandasData继承关系,从AbstractDataBase开始就继承元类了。所以Pandas实例化的时候,首先就会调用MetaBase的__call__.MetaBase的__call__代码如下(比较重要,这里再贴一遍)
__call__(cls, *args, **kwargs):
cls, args, kwargs = cls.doprenew(*args, **kwargs)
_obj, args, kwargs = cls.donew(*args, **kwargs)
_obj, args, kwargs = cls.dopreinit(_obj, *args, **kwargs)
_obj, args, kwargs = cls.doinit(_obj, *args, **kwargs)
_obj, args, kwargs = cls.dopostinit(_obj, *args, **kwargs)
return _obj
可以看出,在__call__中会顺序执行doprenew,donew,dopreinit,doinit和dopostinit。为啥第一个返回cls,而其他返回obj?因为只有new的时候才会实例化,prenew的时候还没实例化呢,只能返回cls(class),在这里可以对类的定义进行一些处理。
好,PadasData实例化开始了,首先调用doprenew,到底调用哪个类的doprenew,根据面向对象原理,看MetaBase哪个子类会重写这个函数,请根据家谱从上往下看,没有任何类重新这个函数,那么只好调用MetaBase自己的doprenew,就是啥也没做:
def doprenew(cls, *args, **kwargs):
return cls, args, kwargs
继续往下走,就该donew了,一样的道理,看看哪个子类重写了这个函数,喔,是MetaLineSeries,那么就进入它的donew开始处理了:
def donew(cls, *args, **kwargs):
'''
Intercept instance creation, take over lines/plotinfo/plotlines
class attributes by creating corresponding instance variables and add
aliases for "lines" and the "lines" held within it
'''
# _obj.plotinfo shadows the plotinfo (class) definition in the class
plotinfo = cls.plotinfo()
for pname, pdef in cls.plotinfo._getitems():
setattr(plotinfo, pname, kwargs.pop(pname, pdef))
# Create the object and set the params in place
_obj, args, kwargs = super(MetaLineSeries, cls).donew(*args, **kwargs)
# set the plotinfo member in the class
_obj.plotinfo = plotinfo
# _obj.lines shadows the lines (class) definition in the class
_obj.lines = cls.lines()
# _obj.plotinfo shadows the plotinfo (class) definition in the class
_obj.plotlines = cls.plotlines()
# add aliases for lines and for the lines class itself
_obj.l = _obj.lines
if _obj.lines.fullsize():
_obj.line = _obj.lines[0]
for l, line in enumerate(_obj.lines):
setattr(_obj, 'line_%s' % l, _obj._getlinealias(l))
setattr(_obj, 'line_%d' % l, line)
setattr(_obj, 'line%d' % l, line)
# Parameter values have now been set before __init__
return _obj, args, kwargs
要点:
- 首先实例化一个AutoInfoClass并进行参数的设置,并记录到plotinfo属性。这个主要用于画图,先不说。
- 下一步就是调用MetaLineSeries父类的donew进行实例化和参数映射。看图,MetaLineSeries父类是MetaLineRoot,然后MetaLineRoot的donew代码:
def donew(cls, *args, **kwargs):
_obj, args, kwargs = super(MetaLineRoot, cls).donew(*args, **kwargs)
# Find the owner and store it
# startlevel = 4 ... to skip intermediate call stacks
ownerskip = kwargs.pop('_ownerskip', None)
_obj._owner = metabase.findowner(_obj,
_obj._OwnerCls or LineMultiple,
skip=ownerskip)
# Parameter values have now been set before __init__
return _obj, args, kwargs
干啥了?继续调用MetaLineRoot的父类的donew,他的父类是MetaParas,这个就不继续贴代码了(代码系列文章3讲过了),就是调用MetaBase的donew,donnew再对PandasData类进行实例化(走了这么大一圈,才到正主啊),并将参数映射到类属性。记住,这个时候的obj就是是PandasData类的实例了!
继续回到MetaLineRoot的donew了,实例化Pandas之后,然后就调用 metabase类findowner函数,这个比较重要,但是对于PandasData对象,没有owner,所以容后再讲。
再就回到MetaLineSeries到的donew了,继续:
- 记录前面实例化的AutoInfoClass到属性plotinfo中。
- 下面是是重头戏,看是实例化Lines了,这个太重要了,单独章节描述。
- 后面就是实例化AutoInfoClass保存到plotlines(这里针对的是具体的line的画图)。这一块先不讲。
- PandasData实例的lines别名为l,同时将实例各个line属性的别名记好(还记得之前文章说明的各种访问line的方法吗?都是这里处理的)。
至此,pandas实例化完成了。
题外话:这里可以看出元类的好处了,普通类实例化很简单,而元类实例化的时候可以根据需要进行定制,将大量的初始化工作抽象到元类完成。
Lines的实例化和初始化
Datas中数据是保存到Line的,所以实例化的同时,会实例化Lines。
从家谱中可以看出,lines只是一个普通类。所以实例化的时候会用__new__实例化,并调用__init__方法初始化,初始化代码如下:
def __init__(self, initlines=None):
'''
Create the lines recording during "_derive" or else use the
provided "initlines"
'''
self.lines = list()
for line, linealias in enumerate(self._getlines()):
kwargs = dict()
self.lines.append(LineBuffer(**kwargs))
# Add the required extralines
for i in range(self._getlinesextra()):
if not initlines:
self.lines.append(LineBuffer())
else:
self.lines.append(initlines[i])
要点:
- 首先就是初始化一个lines容器,然后针每一个的line实例化一个LineBuffer。初始lines包含close,low, high, open, volume, openinterest,还有一个datetime。
- 还有一些额外的line也会实例化Linebuffer(应该就是后续可以定制的line,暂时不用)。
下面就是关键的LinebBuffer了,具体数据就存放在这里。
LineBuffer的实例化和初始化
看咱们的家谱,发现LineBuffer也继承了元类,那么他的实例化肯定也是要受到MetaBase的控制。元类实例化的时候首先会调用doprenew,LineBuffer继承路线上并没有doprenew,那还是调用MebaBase的doprenew,啥也没干。继续下一步就是donew了,继续看继承路线上,还是MetaLineRoot的donew,对了,刚刚pandas类也调用了这个。大家回头看下代码:
- 继续调用MetaLineRoot的父类的donew,他的父类是MetaParas,在MetaParas中继续调用Metabase的donew,donnew再对LineBuffer类进行实例化,并将参数映射到类属性。记住,这个时候的obj是LineBuffer类的实例了!
- 下一个步骤就是调用findowner找到谁是这个LineBuffer实例的主人,这个函数通过查找堆栈信息看看到底是谁实际创建了自己。也就是谁拥有这个LineBuffer实例。猜猜看,是谁?是PandasData实例。猜对了吗?你可以从头看,就是Pandas实例化的时候实例化了lines,然后lines实例化了LineBuffer。为啥要记录这个呢?你看看家谱错综复杂的关系,还有很多没画出来,不知道自己爸爸是谁不行啊。
下面就是doinit了(dopreinit在家谱中没有重写,所以实际没做啥,不提),调用的是LineBuffer的__init__了:
def __init__(self):
self.lines = [self]
self.mode = self.UnBounded
self.bindings = list()
self.reset()
self._tz = None
就是几个属性的初始化,lines先把自己加进去。然后调用reset重置内存存储的结构和索引:
def reset(self):
''' Resets the internal buffer structure and the indices
'''
if self.mode == self.QBuffer:
# add extrasize to ensure resample/replay work because they will
# use backwards to erase the last bar/tick before delivering a new
# bar The previous forward would have discarded the bar "period"
# times ago and it will not come back. Having + 1 in the size
# allows the forward without removing that bar
self.array = collections.deque(maxlen=self.maxlen + self.extrasize)
self.useislice = True
else:
self.array = array.array(str('d'))
self.useislice = False
self.lencount = 0
self.idx = -1
self.extension = 0
由于当前模式为UnBounded,所以初始化为一个array.array. array是python提供的一个array模块(python万物皆为类,你认为是array类就行了),用于提供基本数字,字符类型的数组,容纳字符号,整型,浮点等基本类型。这个array在初始化的时候可以指定类型(Type code),例如这里’d’指定存储float类型的数字(因为咱们股票价格是浮点数),最小8个字节。然后初始化一些基本信息,注意这里idx记为-1.
至此,PandasData实例化完成。想想看,通过元类,这个实例化过程干了多少事!
PandasData的初始化
PandasData的donew完成之后,下一步就是dopreinit了。顺着家谱去找,PandasData的父类中MetaAbstractDataBase重写了dopreinit,看看这里面做了啥?
def dopreinit(cls, _obj, *args, **kwargs):
_obj, args, kwargs = \
super(MetaAbstractDataBase, cls).dopreinit(_obj, *args, **kwargs)
# Find the owner and store it
_obj._feed = metabase.findowner(_obj, FeedBase)
_obj.notifs = collections.deque() # store notifications for cerebro
_obj._dataname = _obj.p.dataname
_obj._name = ''
return _obj, args, kwargs
- 首先是调用父类的dopreinint,不用看了,dopreinit都没有定义,直接到MetaBase走一圈啥也没做。
- 第二步找Pandas的owner,这里返回为空,因为PandasData是实例化的初始发起者,他自己没有owner。
- 初始化notifs用于存储发送给Cerebro的通知。
- 名称name赋值为空串。
dopreinit之后,就是doinit了。看家谱,就是PandasData类本身的__init__函数了:
def __init__(self):
super(PandasData, self).__init__()
# these "colnames" can be strings or numeric types
colnames = list(self.p.dataname.columns.values)
if self.p.datetime is None:
# datetime is expected as index col and hence not returned
pass
# try to autodetect if all columns are numeric
cstrings = filter(lambda x: isinstance(x, string_types), colnames)
colsnumeric = not len(list(cstrings))
# Where each datafield find its value
self._colmapping = dict()
# Build the column mappings to internal fields in advance
for datafield in self.getlinealiases():
defmapping = getattr(self.params, datafield)
if isinstance(defmapping, integer_types) and defmapping < 0:
# autodetection requested
for colname in colnames:
if isinstance(colname, string_types):
if self.p.nocase:
found = datafield.lower() == colname.lower()
else:
found = datafield == colname
if found:
self._colmapping[datafield] = colname
break
if datafield not in self._colmapping:
# autodetection requested and not found
self._colmapping[datafield] = None
continue
else:
# all other cases -- used given index
self._colmapping[datafield] = defmapping
- 第一步就是调用父类的__init__,顺着家谱往上走,爸爸们没做啥,忽略。
- 下一步就是将输入参数dataname(pandas数据DataFrame)的列名记录到colnames中,对于我们的例子,对应的[‘Unnamed: 0’ ‘open’ ‘high’ ‘low’ ‘close’ ‘volume’]。
- 参数datetime通常不用输入,用于指示datetime在哪一列,通常咱们都是放到第一列(索引为0)。
- 再检查下有没有列名字是数字的,是数字的话,直接记录到_colmapping。什么时候是数字?就是参数直接输入line对应的列索引。如果参数中指定了列名称所在的列(数字),那么系统就不会通过名字来映射,直接使用数字。当然数字为-1<0的话,也会查找列并记录列名字。我们例子中,所有都是字符串形式。
- 下面一步就是将Pandas.DataFrame的列名称和PandasData的数据字段做好映射。PandasData的缺省字段包括:[‘datetime’, ‘open’, ‘high’, ‘low’, ‘close’, ‘volume’, ‘openinterest’]。映射关系放到_colmapping字典中,结果:{‘close’: ‘close’, ‘low’: ‘low’, ‘high’: ‘high’, ‘open’: ‘open’, ‘volume’: ‘volume’} .
至此,PandasData初始化也完成了。
PandasData的数据加载
PandasData的reset
还记得Cerebro如何使用datas?第一件事情就是reset(在Cerebro的runstrategies函数里):
for data in self.datas:
data.reset()
if self._exactbars < 1: # datas can be full length
data.extend(size=self.params.lookahead)
data._start()
if self._dopreload:
data.preload()
好,下面看看data如何reset。
看代码,PandasData类中没有reset啊?别忘了咱们是面向对象,拿出家谱,沿着类家族继续往上找,找到LineSeries有一个reset,而且你再瞅一眼,data的操作都在这里呢。看看代码:
def reset(self):
'''
Proxy line operation
'''
for line in self.lines:
line.reset()
看看,其实就是就是一个代理,遍历调用line(对应LineBuffer实例)的reset。有多少个line?看看前面lines类的初始化代码,包括close,low, high, open, volume, openinterest,还有一个datetime,一共7个。每一个line都会进行reset。reset代码前面讲过了,就是初始化一个array.array用于存储数据。
PandasData的_start
_start函数在PandasData类中就有定义:
def _start(self):
self.start()
if not self._started:
self._start_finish()
嗯,调用start,然后_strat_finish函数。
start函数PandasData类有定义:
def start(self):
super(PandasData, self).start()
# reset the length with each start
self._idx = -1
# Transform names (valid for .ix) into indices (good for .iloc)
if self.p.nocase:
colnames = [x.lower() for x in self.p.dataname.columns.values]
else:
colnames = [x for x in self.p.dataname.columns.values]
for k, v in self._colmapping.items():
if v is None:
continue # special marker for datetime
if isinstance(v, string_types):
try:
if self.p.nocase:
v = colnames.index(v.lower())
else:
v = colnames.index(v)
except ValueError as e:
defmap = getattr(self.params, k)
if isinstance(defmap, integer_types) and defmap < 0:
v = None
else:
raise e # let user now something failed
self._colmapping[k] = v
-
第一步就是调用父类的start函数,又得看家谱了,是咱们的AbstractDataBase爸爸,看看干了啥:
def start(self): self._barstack = collections.deque() self._barstash = collections.deque() self._laststatus = self.CONNECTED初始化了两个双边队列_barstack和_barstash(deque类),并记录一个状态。为啥用deque?这个是类似于list的容器,可以在队列头部和尾部添加、删除元素,可以快速高效地进行数据的操作。这个主要用于暂时存储数据。
-
初始化索引为-1.这个需要注意,方便后续+1都可以得到0的起始索引。
-
colnames保存Padas.DataFrame(也就是原始数据)的列名字。
-
_colmapping还记得吗?PandasData类初始化时候处理的,里面记录的是PandasData类对应的原始数据的列名字,这里统一修改为原始数据的列索引(当然如果已经是参数输入数字的话,就直接记录),现在变成了:{‘close’: 4, ‘low’: 3, ‘high’: 2, ‘open’: 1, ‘volume’: 5, ‘openinterest’: None, ‘datetime’: None} ,后面两个没有对应的列。datetime没有是因为原始数据中date直接作为索引了,colnames中就没有了。datatime直接从原始数据第一列(索引为0)提取。
start之后继续调用_start_finish了,但是PandasData类中没有这个定义,所以找家谱图,找到AbstractDataBase,提供了_start_finish函数:
def _start_finish(self):
# A live feed (for example) may have learnt something about the
# timezones after the start and that's why the date/time related
# parameters are converted at this late stage
# Get the output timezone (if any)
self._tz = self._gettz()
# Lines have already been create, set the tz
self.lines.datetime._settz(self._tz)
# This should probably be also called from an override-able method
self._tzinput = bt.utils.date.Localizer(self._gettzinput())
# Convert user input times to the output timezone (or min/max)
if self.p.fromdate is None:
self.fromdate = float('-inf')
else:
self.fromdate = self.date2num(self.p.fromdate)
if self.p.todate is None:
self.todate = float('inf')
else:
self.todate = self.date2num(self.p.todate)
# FIXME: These two are never used and could be removed
self.sessionstart = time2num(self.p.sessionstart)
self.sessionend = time2num(self.p.sessionend)
self._calendar = cal = self.p.calendar
if cal is None:
self._calendar = self._env._tradingcal
elif isinstance(cal, string_types):
self._calendar = PandasMarketCalendar(calendar=cal)
self._started = True
- 设置data的时区以及各个lines datatime的时区。
- 将参数输入的时间变换为数字形式,就是以公元1年1月1日零时记为1,每过1天就增加1,不够一天按照按照比例记(比如中午12点,记为0.5)。通过这样的方法,把时间转化为一个独一无二的数字,方便对数据的快速处理。
- 记录日历信息到_calendar,具体使用后续再说。
- 标记start完成。
PandasData的preload
还是老规矩,在家谱图里面找:AbstractDataBase提供了preload函数,preload循环调用load函数,加载数据:
def preload(self):
while self.load():
pass
def load(self):
while True:
# move data pointer forward for new bar
self.forward()
if self._fromstack(): # bar is available
return True
if not self._fromstack(stash=True):
_loadret = self._load()
if not _loadret: # no bar use force to make sure in exactbars
# the pointer is undone this covers especially (but not
# uniquely) the case in which the last bar has been seen
# and a backwards would ruin pointer accounting in the
# "stop" method of the strategy
self.backwards(force=True) # undo data pointer
# return the actual returned value which may be None to
# signal no bar is available, but the data feed is not
# done. False means game over
return _loadret
# Get a reference to current loaded time
dt = self.lines.datetime[0]
# A bar has been loaded, adapt the time
if self._tzinput:
# Input has been converted at face value but it's not UTC in
# the input stream
dtime = num2date(dt) # get it in a naive datetime
# localize it
dtime = self._tzinput.localize(dtime) # pytz compatible-ized
self.lines.datetime[0] = dt = date2num(dtime) # keep UTC val
# Check standard date from/to filters
if dt < self.fromdate:
# discard loaded bar and carry on
self.backwards()
continue
if dt > self.todate:
# discard loaded bar and break out
self.backwards(force=True)
break
# Pass through filters
retff = False
for ff, fargs, fkwargs in self._filters:
# previous filter may have put things onto the stack
if self._barstack:
for i in range(len(self._barstack)):
self._fromstack(forward=True)
retff = ff(self, *fargs, **fkwargs)
else:
retff = ff(self, *fargs, **fkwargs)
if retff: # bar removed from systemn
break # out of the inner loop
if retff: # bar removed from system - loop to get new bar
continue # in the greater loop
# Checks let the bar through ... notify it
return True
# Out of the loop ... no more bars or past todate
return False
- 首先就是调用PandasData的forward函数,一样的,家谱图在父类LineSeries中提供forward函数:
def forward(self, value=NAN, size=1):
self.lines.forward(value, size)
就是直接调用lines的forward,lines类函数直接传递到line(LineBuffer)的forward函数:
def forward(self, value=NAN, size=1):
'''
Proxy line operation
'''
for line in self.lines:
line.forward(value, size=size)
LineBuffer的forward函数:
def forward(self, value=NAN, size=1):
''' Moves the logical index foward and enlarges the buffer as much as needed
Keyword Args:
value (variable): value to be set in new positins
size (int): How many extra positions to enlarge the buffer
'''
self.idx += size
self.lencount += size
for i in range(size):
self.array.append(value)
关键点在这里:
- 索引加1(缺省步幅)。还记得缺省idx是多少?-1,所以第一次调用这个函数就变成0了。
- 长度加1
- array中加入NAN无效值(初始化值)
继续load函数:
- 调用_fromstack从_barstack或者_barstash中获取数据,现在无法获取,因为_start的时候是空的。
- 没有获取到数据,那么就调用_load函数了,这里特别注意,由于pandasData类重写了_load函数,所以开始调用PandasData自己的加载函数了。
def _load(self):
self._idx += 1
if self._idx >= len(self.p.dataname):
# exhausted all rows
return False
# Set the standard datafields
for datafield in self.getlinealiases():
if datafield == 'datetime':
continue
colindex = self._colmapping[datafield]
if colindex is None:
# datafield signaled as missing in the stream: skip it
continue
# get the line to be set
line = getattr(self.lines, datafield)
# indexing for pandas: 1st is colum, then row
line[0] = self.p.dataname.iloc[self._idx, colindex]
# datetime conversion
coldtime = self._colmapping['datetime']
if coldtime is None:
# standard index in the datetime
tstamp = self.p.dataname.index[self._idx]
else:
# it's in a different column ... use standard column index
tstamp = self.p.dataname.iloc[self._idx, coldtime]
# convert to float via datetime and store it
dt = tstamp.to_pydatetime()
dtnum = date2num(dt)
self.lines.datetime[0] = dtnum
# Done ... return
return True
解析如下:
-
首先索引加1,从0开始。知道为啥初始化为-1的好处了吧。如果索引大于原始数据(注意dataname参数输入的是Pandas.DataFrame)的行数。表明加载完成(返回False,停止外层循环)。
-
根据data中每个line的别名(初始化的时候是close,low, high, open, volume, openinterest),在原始数据(Pandas.DataFrame)中找到对应的列编号(对应编号前面讲过,记录在_colmapping中)。然后将对应列的原始数据加入到line(例如close)的array.array中。这里就会有第一个数据了,例如array(‘d’, [1302.084])
-
然后就是找datetime,datetime通常作为索引放到第一列,所以从第一列取一个数据,并调用date2num转换为数字记录到所有line的datetime中,可以看出,所有line的时间必须一样。
注意,_load函数一次只取一次数据,下面继续看load函数:
- 加载数据之后,如果数据中输入了时区,那么就转化为本地时间,并更新datetime line的数据为新的日期数值。
- 如果小于参数起始日期(fromdate)或者大于参数中终止日期(enddate),就会调用backwards函数。和forward一样,经过LineSeries的backforward直接到LineBuffer的backforward函数:
def backwards(self, size=1, force=False):
''' Moves the logical index backwards and reduces the buffer as much as needed
Keyword Args:
size (int): How many extra positions to rewind and reduce the
buffer
'''
# Go directly to property setter to support force
self.set_idx(self._idx - size, force=force)
self.lencount -= size
for i in range(size):
self.array.pop()
-
首先将idx回退,加第一个数据的时候是0,回退到-1了。长度也减去回退的步幅(这里是1)。然后就需要将之前加值删除掉(array的pop函数删除掉一个元素,缺省是最新加的一个数据)。那么array就变成array(‘d’)了,没数据。也就是不符合起始时间的数据不会被加载。注意,是每一个line(close,high,low等等)都会回退。
-
回退之后,如果是小于起始日期,则继续循环。如果是大于终止日期,那么就停止,数据加载完成。
-
load函数就这样一直循环到日期等于起始日期,加入起始日期的数据,并对数据进行过滤处理(过滤器_filters后面再讲)。处理完毕,就到回到preload了。preolod没干啥,继续load了。
-
首先forward,由于之前已经加了一个数据,所以这里idx变成1了,同时在array.array在加一个空值。
-
然后_load了(看前面描述)再加一个数据到array.array中,这样循环下去,直到大于终结日期(注意大于终结日期的第一个数据会backward),或者取得的数据大于原始数据长度(也就是数据取完了),循环结束。
-
load循环结束,回到preload函数(AbstractDataBase),也终止循环,并且调用_last进行最后的处理(这里可以再次过滤),具体代码不贴了。
-
再然后调用home函数,和forward路线一样,直接到LineBuffer的home,就是将每个line的idx设置为初始值(-1),长度计数(lencount)设置为0。这个主要用于加载数据的计数。如果要获取某个line的数据个数,可以使用buflen。这样状态恢复至加载前的状态。
def home(self):
''' Rewinds the logical index to the beginning
The underlying buffer remains untouched and the actual len can be found
out with buflen
'''
self.idx = -1
self.lencount = 0
至此,preload完毕,总体上就是将原始数据(来自Pandas.Dataframe)填写到Linebuffer对象的array.array.
PandasData的next
前面看代码Cerebro在runstrategies函数中调用preload的代码,前面是有一个条件的:
if self._dopreload:
data.preload()
就是要满足_dopreload的时候才能预加载,实际上,如下几种情况不会预加载:
- 数据源datas包含实时(live)数据。
- 数据源包含resample和replay数据。
那么这些情况下如何加载数据呢?那就是在next过程中加载。
看Cerebro的_runnext函数中一段(整体在下一章使用中说明)
for d in datas:
qlapse = datetime.datetime.utcnow() - qstart
d.do_qcheck(newqcheck, qlapse.total_seconds())
drets.append(d.next(ticks=False))
直接调用数据的next函数,我们来找next函数。家谱图,发现了next在AbstractDataBase,看看是如何处理的:
def next(self, datamaster=None, ticks=True):
if len(self) >= self.buflen():
if ticks:
self._tick_nullify()
# not preloaded - request next bar
ret = self.load()
if not ret:
# if load cannot produce bars - forward the result
return ret
if datamaster is None:
# bar is there and no master ... return load's result
if ticks:
self._tick_fill()
return ret
else:
self.advance(ticks=ticks)
# a bar is "loaded" or was preloaded - index has been moved to it
if datamaster is not None:
# there is a time reference to check against
if self.lines.datetime[0] > datamaster.lines.datetime[0]:
# can't deliver new bar, too early, go back
self.rewind()
else:
if ticks:
self._tick_fill()
else:
if ticks:
self._tick_fill()
# tell the world there is a bar (either the new or the previous
return True
可以看出,主要也是调用load函数加载数据,load函数前面讲过,这里不再讨论了。
PandasData的过滤和调整
前面介绍原始数据,有时候咱们还需要进行 一定的处理才能使用。backtrader提供了Resample,Replay,下面分别讨论。
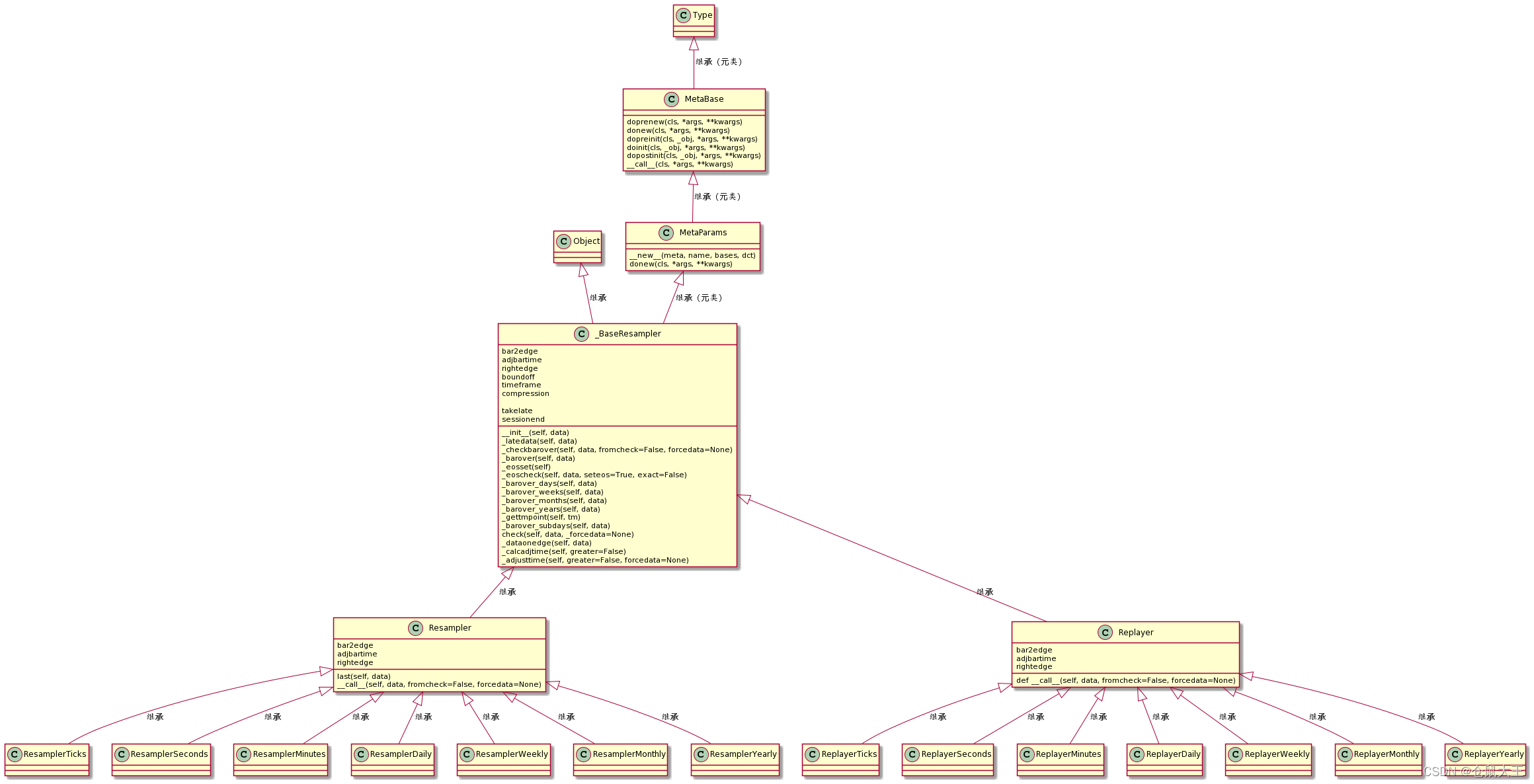
虽然没有数据类关系图谱那么复杂,但是为了方便解读,还是提供下resampler以及Replayer的关系图谱。
Resample和Replay关系图谱
Resampling
有时候咱们的策略中,同时要看日线和周线,咱们原始数据是每天的(甚至还有每小时每分钟的),那咋办?backtrader给你提供了resampledata函数。
Resampling主要用于将粒度小的数据重新抽样为粒度大的数据,例如日线转为周线。
backtrader内置了过滤器对象,可以进行对原始数据进行处理。通过如下代码可以简单实现:
stock_hfq_df = pd.read_csv("../data/sh000001上证指数.csv",index_col='date',parse_dates=True)
start_date = datetime(2021, 9,1 ) # 回测开始时间
end_date = datetime(2021, 9, 10) # 回测结束时间
data = bt.feeds.PandasData(dataname=stock_hfq_df, fromdate=start_date) # 加载数据
cerebro.adddata(data) # 将数据传入回测系统
cerebro.resampledata(data,timeframe=bt.TimeFrame.Weeks)
- 首先要实例化一个原始数据。
- 然后更改时间长度。通常两个方法:一个是直接输入时间粒度(timeframe),比如一周;另外一个压缩比(compression),比如compression为2,表示2行压缩为1行。
resampledata函数上一篇文章在Cerebro解读的时候讲过,这里再明确下:
def resampledata(self, dataname, name=None, **kwargs):
'''
Adds a ``Data Feed`` to be resample by the system
If ``name`` is not None it will be put into ``data._name`` which is
meant for decoration/plotting purposes.
Any other kwargs like ``timeframe``, ``compression``, ``todate`` which
are supported by the resample filter will be passed transparently
'''
if any(dataname is x for x in self.datas):
dataname = dataname.clone()
dataname.resample(**kwargs)
self.adddata(dataname, name=name)
self._doreplay = True
return dataname
- 首先从已经加入的data中找到参数中指定的需要resample的数据,所以一定要注意,这个函数只能针对已有数据。然后从克隆一个完全一样的数据。注意,克隆后完全是新的地址空间,但是内容是完全一样。CloneDatabase在数据家族中的地位参见第一章家谱图右下角,可以看出,他继承了AbastractDatabase,也就是它和普通数据类操作差不多,只是重写了start/preload/_load/Advace函数,也就是这几个处理有不同。
- 然后调用data的resample函数,这里又涉及到元类了,顺着家谱,找到AbstractDataBase(好眼熟啊,又是它):
def resample(self, **kwargs):
self.addfilter(Resampler, **kwargs)
def addfilter(self, p, *args, **kwargs):
if inspect.isclass(p):
pobj = p(self, *args, **kwargs)
self._filters.append((pobj, [], {}))
if hasattr(pobj, 'last'):
self._ffilters.append((pobj, [], {}))
else:
self._filters.append((p, args, kwargs))
直接就调用addfilter加载滤器类(Resampler)了。注意这个函数输入的既可以是类,也可以是实例。当前使用的是类,先实例化得到具体对象,然后加入到数据的_filters. 眼熟吧?在数据load的时候会调用(往前搜索下)。
看到这里,你可以看到,Resample加入的数据,和原数据完全一样,就是增加一个Resampler的对象,在加载数据的时候进行针对性处理。
下面看看Resampler类了。
Resampler的实例化和初始化
根据家谱来看,Resampler父类有元类,所以实例化还得到MetaBase走一圈,套路一样,就不详细描述,只解析过程波及的函数。
根据家谱图,只有MetaParams重写donew函数,这个函数解析过,重点是进行参数到属性的映射,并完成实例化。
关键参数包括(从家谱中找,所有祖先的属性都会继承到Resampler实例中):
| 参数 | 缺省值 | 含义 |
|---|---|---|
| adjbartime | TRUE | 使用边界时间调整采样后的时间,而不是最后看到的时间戳。如果重新采样时间粒度为5s。那么时间调整为hh:mm:05 即使在这个时间宽度范围内最后一个bar的时间戳是hh:mm:04.33。 |
| bar2edge | TRUE | 以时间边界为目标的重采样。比如说,将ticks(时间戳)按照5秒粒度重新采样,则生成的5秒粒度将对齐如下: xx:00,xx:05,xx:10… |
| boundoff | 0 | 就是向前移动一定数量数据(bar)用来resample。比如说,现在是1分钟粒度抽样为15分钟粒度,系统缺省是从 00:01:00 到00:15:00 15个1分钟粒度的数据产生1个15分钟粒度。如果这个值设置为1,那么向前移动一位,从 00:00:00 到00:14:00也是15个1分钟粒度的数据产生一个15分钟粒度的数据。 |
| compression | 1 | 压缩比(compression),比如compression为2,表示2个小粒度数据压缩为1个目标粒度数据。 |
| rightedge | TRUE | 使用边界时间的右边缘作为采用后的时间,一样,如果采用目标长度是5s: 设置为False:hh:mm:00到hh:mm:04之间的秒数抽样为为hh:mm:00(边界的开始时间) 设置为True,那么抽样后为hh:mm:05(边界结束时间) |
实例化之后,就开始初始化了。看家谱图,找到_BaseResampler的__init__,里面主要就是参数的初始化,关键是将自己和data对象绑定。代码就不贴了。
Resmapler的数据加载
Resampler的数据加载,加载过程和普通data差不多,只是加载的是DataClone。首先是在runstrategis函数中调用_start函数,这个函数DataClone在重写:
def _start(self):
# redefine to copy data bits from guest data
self.start()
# Copy tz infos
self._tz = self.data._tz
self.lines.datetime._settz(self._tz)
self._calendar = self.data._calendar
# input has already been converted by guest data
self._tzinput = None # no need to further converr
# Copy dates/session infos
self.fromdate = self.data.fromdate
self.todate = self.data.todate
# FIXME: if removed from guest, remove here too
self.sessionstart = self.data.sessionstart
self.sessionend = self.data.sessionend
def start(self):
super(DataClone, self).start()
self._dlen = 0
self._preloading = False
-
首先调用DataClone父类的start,父类就是AbstractDataBase,如何start和普通Data一样,请反向搜索查看。然后各条line的设定时区。记录起始结束日期。特别注意的是,这里的_preloading的时候都是False。
-
然后就是调用dataclone的next(参见4.4节,也许你说了,也没看到4.4节啊,主要是MarkDown不支持自动加编号,顺着标题看第4个一级标题,第4个二级标题)。再调用DataClone的_load函数了,代码如下:
def _load(self): # assumption: the data is in the system # simply copy the lines if self._preloading: # data is preloaded, we are preloading too, can move # forward until have full bar or data source is exhausted self.data.advance() if len(self.data) > self.data.buflen(): return False for line, dline in zip(self.lines, self.data.lines): line[0] = dline[0] return True # Not preloading if not (len(self.data) > self._dlen): # Data not beyond last seen bar return False self._dlen += 1 for line, dline in zip(self.lines, self.data.lines): line[0] = dline[0] return True如果不是预加载,直接从DataClone的原始数据(本例这两个就是Data0,在初始化的时候已绑定)中将所有Line拷贝到CloneData的lines中。
Resampler的使用
我们已经知道,数据加载数据的时候会调用过滤器对数据进行处理。在AbstractDataBase的load函数中,在加载数据完成之前(请看前述PandasData的preload章节),最后会经过filters进行处理,代码如下:
# Pass through filters
retff = False
for ff, fargs, fkwargs in self._filters:
# previous filter may have put things onto the stack
if self._barstack:
for i in range(len(self._barstack)):
self._fromstack(forward=True)
retff = ff(self, *fargs, **fkwargs)
else:
retff = ff(self, *fargs, **fkwargs)
if retff: # bar removed from systemn
break # out of the inner loop
if retff: # bar removed from system - loop to get new bar
continue # in the greater loop
- 代码先看看之前是否有filter处理过,这就要看_barstack(为啥加stack,就是为了回溯之前的处理)。咱们这里是第一个filter,所以直接到 ff(self, *fargs, **fkwargs)。ff是Resampler对象,加个括号和参数啥意思?这个是显式调用Resampler类的__call__。这一段代码过于晦涩难懂,考虑到这个对我们理解Backtrader作用不大,我们只需要知道如何使用即可,后续就不深入解读这一块代码(说不定有时间再仔细看看)。
Resampler作用的结果
我们重点看看经过Resampler处理之后数据的呈现,这样我们可以根据需要使用它来达到我们的期望。首先我们有这样一个原始数据。将每天粒度(日线)改为每周粒度(周线)。
| 日期 | 星期 | 原始close | Resample后的close |
|---|---|---|---|
| 2021/9/1 | 3 | 3567.101 | - |
| 2021/9/2 | 4 | 3597.043 | - |
| 2021/9/3 | 5 | 3581.734 | - |
| 2021/9/6 | 1 | 3621.859 | 3581.734 |
| 2021/9/7 | 2 | 3676.587 | 3581.734 |
| 2021/9/8 | 3 | 3675.187 | 3581.734 |
| 2021/9/9 | 4 | 3693.13 | 3581.734 |
| 2021/9/10 | 5 | 3703.11 | 3581.734 |
| 2021/9/13 | 1 | 3715.372 | 3703.11 |
| 2021/9/14 | 2 | 3662.602 | 3703.11 |
| 2021/9/15 | 3 | 3656.223 | 3703.11 |
| 2021/9/16 | 4 | 3607.092 | 3703.11 |
| 2021/9/17 | 5 | 3613.966 | 3703.11 |
| 2021/9/22 | 3 | 3628.49 | 3613.966 |
| 2021/9/23 | 4 | 3642.22 | 3613.966 |
| 2021/9/24 | 5 | 3613.067 | 3613.966 |
| 2021/9/27 | 1 | 3582.831 | 3613.067 |
| 2021/9/28 | 2 | 3602.218 | 3613.067 |
| 2021/9/29 | 3 | 3536.294 | 3613.067 |
| 2021/9/30 | 4 | 3568.167 | 3613.067 |
这个就是原始的的数据,下面看看Resampler过滤后的数据:
- 首先,第一周的数据,因为需要根据第一周的数据生成周线;
- 下一周开始,周线记录的是上一周周五的数据。
从以上图标,可以清晰地看出Resampler是如何处理的。
Replaying
Replay对应的过滤器是Replayer,从关系图谱可以看出,基本上和Resampler差不多。从名字来看,数据就是重新播放一下,关键是数据的生成或者说使用过程,这个需要在next过程中查看,后续统一描述。
自定义过滤器
如果我们要定制自己的过滤规则怎么办?可以继承Resampler类值处理,但是我觉得这个完全没必要。如果有更复杂的数据定制需求,咱们可以在Backtrader加载之前使用Pandas进行预处理啊,Pandas多强大,还需要自己编码处理数据?
PandasData的使用
Pandas的数据被使用,在两种情况:
- 数据已经预加载并且参数设置runonce为True(缺省值)
- 其他情况下都是_runnext
在Cerebro的_runonce中使用
数据加载之后,系统如何使用这些数据呢?这个使用主要还是看Cerebro如何调度,这里还是以Cerebro的_runonce函数对data的处理为线索:
while True:
# Check next incoming date in the datas
dts = [d.advance_peek() for d in datas]
dt0 = min(dts)
if dt0 == float('inf'):
break # no data delivers anything
# Timemaster if needed be
# dmaster = datas[dts.index(dt0)] # and timemaster
slen = len(runstrats[0])
for i, dti in enumerate(dts):
if dti <= dt0:
datas[i].advance()
# self._plotfillers2[i].append(slen) # mark as fill
else:
# self._plotfillers[i].append(slen)
pass
在_runonce函数中,循环进行数据(所有数据indicator等)的协调处理,首先就是数据时间的对齐,如何做到的呢?为了更容易说明,我们示例中加入了两个数据:第一个数据起始(索引为0)时间2021/9/3(对应数字为738036),第二个数据(索引为1)的起始时间2021/9/3(对应数字为738034)。看看是如何处理的:
-
首先调用data的advance_peek,这个函数在哪里,在家谱中找,喔,在AbstractDataBase中:
def advance_peek(self): if len(self) < self.buflen(): return self.lines.datetime[1] # return the future return float('inf') # max date else逻辑很简单,取得data的下一个时间,如果是第一次取数据,下一个就是0(也就是第一个),因为索引初始化为-1。
-
将两个data的第一个日期值取回放到dts数组中,这个dts是[738036.0, 738034.0]. 并取其最小值(对应最早日期9月1日)到dt0.
-
下一步就是循环dts,走到dts中小于等于dt0的data,说白了,就是找到初始日期最早的data,然后对该data调用advance。
-
advance函数在家谱中,一样追溯到AbstractDataBase中:
def advance(self, size=1, datamaster=None, ticks=True):
if ticks:
self._tick_nullify()
# Need intercepting this call to support datas with
# different lengths (timeframes)
self.lines.advance(size)
直接调用lines的advance,lines只是的代理,再调用所有该data的所有lines的,到LineBuffer的advance:
def advance(self, size=1):
''' Advances the logical index without touching the underlying buffer
Keyword Args:
size (int): How many extra positions to move forward
'''
self.idx += size
self.lencount += size
就是所有line索引后移,长度计数增加。这里idx变为0了。注意,这里只改索引,不涉及底层数据。再看下一轮循环:
- 取下一个日期值放到dts数组中。取得是哪个值呢,请注意,data0的idx没动,还是-1,data1已经advance中idx变为0了。所以advance_peek返回的时间:data0还是第一个数据,data1是第二个数据了。dts=[738036.0, 738035.0],看data1的时间已经后退到9月2日了。
- 然后继续找到最早的数据,还是data1,然后继续advace。索引变为1了。
- 在继续循环,一样的原理,dts就是[738036.0, 738036.0]了,两个时间终于相同了。这种情况下,data0和data1都需要advance,idx后移。data0的idx为0,data1的idx=2了。也就是data0和data1基于时间线对齐了。
- 后续就一同后移(next),数据提供给Strategies使用了,具体如何用,咱们后续在Strategies类中再详细解读。
在Cerebro的_runnext中使用
由于_runnext函数中大量对数据的处理,虽然上一篇文章已经描述过,但是不够细节,这里再以数据处理的视角重点解析,代码如下:
def _runnext(self, runstrats):
'''
Actual implementation of run in full next mode. All objects have its
``next`` method invoke on each data arrival
'''
datas = sorted(self.datas,
key=lambda x: (x._timeframe, x._compression))
datas1 = datas[1:]
data0 = datas[0]
d0ret = True
rs = [i for i, x in enumerate(datas) if x.resampling]
rp = [i for i, x in enumerate(datas) if x.replaying]
rsonly = [i for i, x in enumerate(datas)
if x.resampling and not x.replaying]
onlyresample = len(datas) == len(rsonly)
noresample = not rsonly
clonecount = sum(d._clone for d in datas)
ldatas = len(datas)
ldatas_noclones = ldatas - clonecount
lastqcheck = False
dt0 = date2num(datetime.datetime.max) - 2 # default at max
while d0ret or d0ret is None:
# if any has live data in the buffer, no data will wait anything
newqcheck = not any(d.haslivedata() for d in datas)
if not newqcheck:
# If no data has reached the live status or all, wait for
# the next incoming data
livecount = sum(d._laststatus == d.LIVE for d in datas)
newqcheck = not livecount or livecount == ldatas_noclones
lastret = False
# Notify anything from the store even before moving datas
# because datas may not move due to an error reported by the store
self._storenotify()
if self._event_stop: # stop if requested
return
self._datanotify()
if self._event_stop: # stop if requested
return
# record starting time and tell feeds to discount the elapsed time
# from the qcheck value
drets = []
qstart = datetime.datetime.utcnow()
for d in datas:
qlapse = datetime.datetime.utcnow() - qstart
d.do_qcheck(newqcheck, qlapse.total_seconds())
drets.append(d.next(ticks=False))
d0ret = any((dret for dret in drets))
if not d0ret and any((dret is None for dret in drets)):
d0ret = None
if d0ret:
dts = []
for i, ret in enumerate(drets):
dts.append(datas[i].datetime[0] if ret else None)
# Get index to minimum datetime
if onlyresample or noresample:
dt0 = min((d for d in dts if d is not None))
else:
dt0 = min((d for i, d in enumerate(dts)
if d is not None and i not in rsonly))
dmaster = datas[dts.index(dt0)] # and timemaster
self._dtmaster = dmaster.num2date(dt0)
self._udtmaster = num2date(dt0)
# slen = len(runstrats[0])
# Try to get something for those that didn't return
for i, ret in enumerate(drets):
if ret: # dts already contains a valid datetime for this i
continue
# try to get a data by checking with a master
d = datas[i]
d._check(forcedata=dmaster) # check to force output
if d.next(datamaster=dmaster, ticks=False): # retry
dts[i] = d.datetime[0] # good -> store
# self._plotfillers2[i].append(slen) # mark as fill
else:
# self._plotfillers[i].append(slen) # mark as empty
pass
# make sure only those at dmaster level end up delivering
for i, dti in enumerate(dts):
if dti is not None:
di = datas[i]
rpi = False and di.replaying # to check behavior
if dti > dt0:
if not rpi: # must see all ticks ...
di.rewind() # cannot deliver yet
# self._plotfillers[i].append(slen)
elif not di.replaying:
# Replay forces tick fill, else force here
di._tick_fill(force=True)
# self._plotfillers2[i].append(slen) # mark as fill
elif d0ret is None:
# meant for things like live feeds which may not produce a bar
# at the moment but need the loop to run for notifications and
# getting resample and others to produce timely bars
for data in datas:
data._check()
else:
lastret = data0._last()
for data in datas1:
lastret += data._last(datamaster=data0)
if not lastret:
# Only go extra round if something was changed by "lasts"
break
# Datas may have generated a new notification after next
self._datanotify()
if self._event_stop: # stop if requested
return
if d0ret or lastret: # if any bar, check timers before broker
self._check_timers(runstrats, dt0, cheat=True)
if self.p.cheat_on_open:
for strat in runstrats:
strat._next_open()
if self._event_stop: # stop if requested
return
self._brokernotify()
if self._event_stop: # stop if requested
return
if d0ret or lastret: # bars produced by data or filters
self._check_timers(runstrats, dt0, cheat=False)
for strat in runstrats:
strat._next()
if self._event_stop: # stop if requested
return
self._next_writers(runstrats)
# Last notification chance before stopping
self._datanotify()
if self._event_stop: # stop if requested
return
self._storenotify()
if self._event_stop: # stop if requested
return
首先说明下,这次咱们使用的是两个数据作为例子:
- 一个是按照日期粒度的原始数据。
- 一个是Resample按照周粒度的重新抽样数据。
再看代码:
- 首先按照粒度对数据进行排序,原始数据粒度为天,所以保存到data0中,其他数据保存到datas1(注意,这个是列表,可以保存多个数据)。
- 下一段就是统计有多少数据是resample和replay的数据,以及是clone的数据,记好标记。
- dt0初始化为最大时间(9999年12月31日)的日期数值。
- 开始循环,对实时数据以及通知的处理忽略,快进到数据的处理,记录好数据处理开始的时间。
- 开始每个数据的处理,首先记录下从时间差(当前data处理减去上一步记录的数据处理时间)。然后调用data的do_qcheck函数。根据家谱图,找到AbastractDataBase中:
def do_qcheck(self, onoff, qlapse):
# if onoff is True the data will wait p.qcheck for incoming live data
# on its queue.
qwait = self.p.qcheck if onoff else 0.0
qwait = max(0.0, qwait - qlapse)
self._qcheck = qwait
? 将时间差记住,后续处理数据的时候要等待对应的是时间。
然后就是调用data的next函数(4.4节已有描述),并记录返回值到drets。next中会加载符合时间要求的数据(注意普通数据和resample数据加载方法不一样)。同时,对于Resample的data(DataClone)返回值是False。
根据返回值,提取普通数据的date值最小的data,也就是时间最早的data,记为主数据(dmaster)。分别记录具体时间和日期值。
后续检查drets返回值为False的数据(也就是Resample的DataClone数据),首先调用_check函数进行过滤(Resample)处理。然后就是调用next函数。在家谱图中咱们看到DataClone继承AbstractDataBase,因此调用的是它的next。AbastractDataBase的next函数参见4.4节描述,这里就不再一次贴代码了。先调用AbstractDataBase的load,再调用CloneDataBase的_load函数(因为被重写了,参见家谱图),这个DataClone的处理和普通Data的处理有不同,就是直接从clone的原始数据获取,不过这里,并没有获取到数据(过滤策略),所以dts[1]并没有记录到时间。只有获取到一个数据,才会记录这个时间。还记得dts[0]的时间是什么时候?原始数据的起始时间2021年9月1日。
后面的处理就和data关系不大了,就到了Strategies的next驱动。
总体上,和_runonce相比,_runnext由于数据并没有预加载,所以在next过程中驱动加载。
这里只是描述了数据在Cerebro的使用,而关键在Strategies中如何使用,这一块下一篇文章中专题讲。
如何增加自定义的数据
前面我们说过,lines包含close,low, high, open, volume, openinterest,还有一个datetime。如果我选股需要更多的数据怎么办?比如PE(市盈率)、ROE(净资产收益率)和turnover(换手率)等等。如果你有基本的面向对象知识,通过我们上述代码解析,就可以很容易知道如何办了。咱们自定义一个数据类,从PandasData继承:
class MyCustomdata(PandasData):
lines = ('turnover',)
params = (('turnover',-1),)
简单两行代码:
- 首先增加一个line(也可以加多个,这里只是一个示例)。那其他的lines呢?从PandasData继承啊。这里有一点注意下,如果只增加一个line,别忘了元组里面逗号不能省,为啥?前面文章讲过。
- 添加一个参数,指示该Line(turnover)对应的原始数据PandasFrame的列号。如果是-1的话,就是让系统从原始数据Pandas.DataFrame列名称中匹配查找。
看看,是如何的简单!甚至不用重写任何函数。这就是面向对象程序的伟大,所有的处理细节都抽象到父类完成。突然想到有个介绍backtrader的专家,说面向对象没必要,还是过程编程比较好,呵呵。Backtrader的目标就是易于使用,为啥易于使用?那是因为复杂的事情框架都做了啊。
好,继续,那这个自定义类怎么用呢?用法就是和PandasData一样:
stock_hfq_df = pd.read_csv("../data/sh600000.csv",index_col='date',parse_dates=True)
start_date = datetime(2021, 9,1 ) # 回测开始时间
end_date = datetime(2021, 9, 30) # 回测结束时间
data=MyCustomdata(dataname=stock_hfq_df, fromdate=start_date,todate=end_date)
看看咱们数据加载好没有,可以在strategies的next函数中增加打印看看:
def next(self):
self.log('Close:%.3f' % self.data0.close[0])
self.log('turnover, %.8f' % self.data0.turnover[0])
结果:
…(省略若干)
2021-09-27, Close:127.110
2021-09-27, turnover, 0.00142096
2021-09-28, Close:127.260
2021-09-28, turnover, 0.00113589
2021-09-29, Close:127.110
2021-09-29, turnover, 0.00136304
2021-09-30, Close:126.830
2021-09-30, turnover, 0.00099448
嗯,数据加载成功,咱们在策略中就可以使用换手率了。
总结
本文我们详细讲解了Backtrader中数据相关类的关系以及初始化、数据加载等过程,并提供了自定义数据类的方法。其中元类的使用,有志于编制大型框架的同学可以参考。
当然,我们是以使用者的角度来进行解读,还有一些数据类并未波及。没关系,如果后续在使用过程中有波及,我们会针对性解读。
除了PandasData,还有直接从CSV读取数据的类GenericCSVData,这个只要看看类继承关系,基于我们前面的代码解读,就很容易理解和使用,不再描述。
至此,咱们的数据已经ready,那么下一步就是看Strategies如何使用这些数据进行回测。