Python+Selenium动态网页的信息爬取
一、Selenium
(一)Selenium简介
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
(二)安装环境
1.安装依赖・
要开始使用selenium,需要安装一些依赖
conda install selenium
1.安装驱动
要使用selenium去调用浏览器,还需要一个驱动,不同浏览器的webdriver需要独立安装
各浏览器下载地址:selenium官网驱动下载
Firefox浏览器驱动:geckodriver
Chrome浏览器驱动:chromedriver , taobao备用地址
IE浏览器驱动:IEDriverServer
Edge浏览器驱动:MicrosoftWebDriver
Opera浏览器驱动:operadriver
PhantomJS浏览器驱动:phantomjs
二、自动填充百度网页的查询关键字并完成自动搜索
1.检查百度源代码中搜素框的id以及搜素按钮的id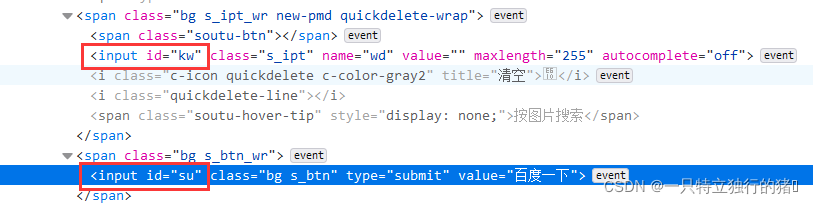
2.获取百度网页
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
driver.get("https://www.baidu.com/")
运行的话,此时会打开百度的起始页

3.填充搜索框
p_input = driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('一只特立独行的猪'))
print(p_input.text)
- location,是元素的位置;
- size是元素的大小
- send_keys是给元素传入值,这里,我们再传入python之后,会自动展开搜索
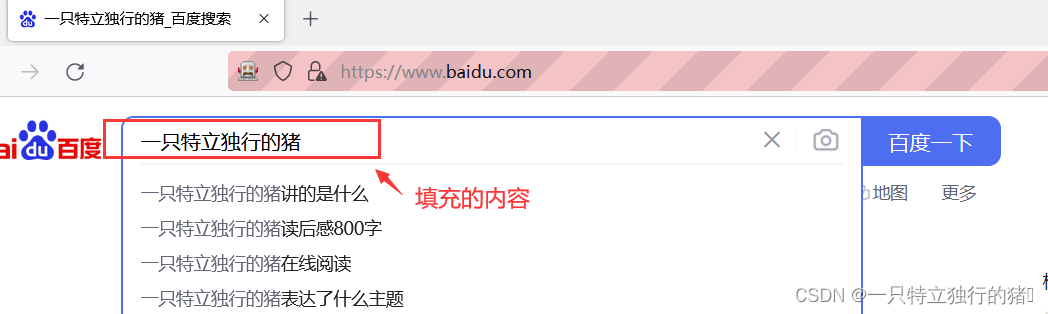
4.模拟点击
用另一个input,也就是按钮的点击事件来实现;或者是form表单的提交事件
p_btn = driver.find_element_by_id('su')
p_btn.click()
5.最终效果
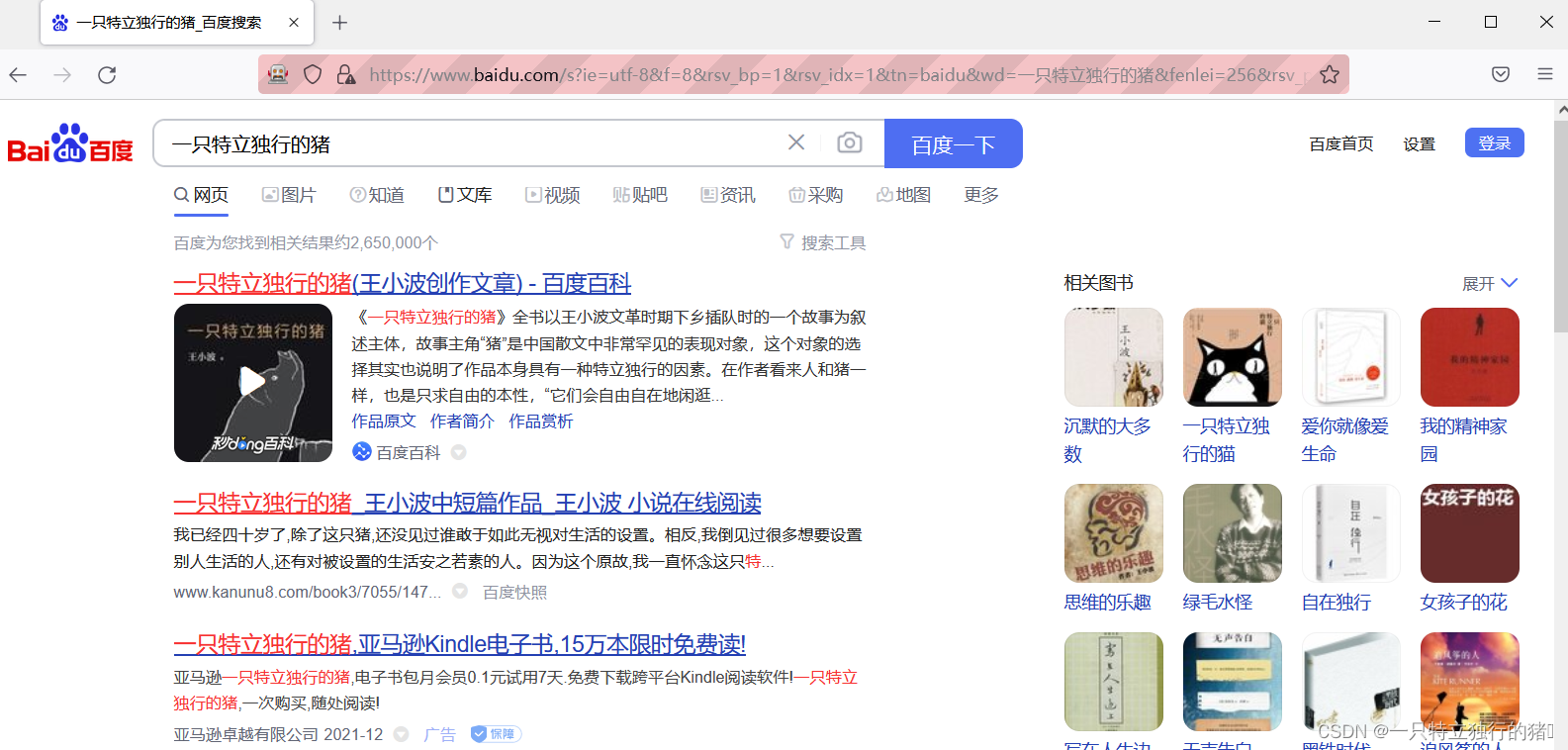
三、爬取一个动态网页的数据
(一)网站链接
http://quotes.toscrape.com/js/
(二)分析网页
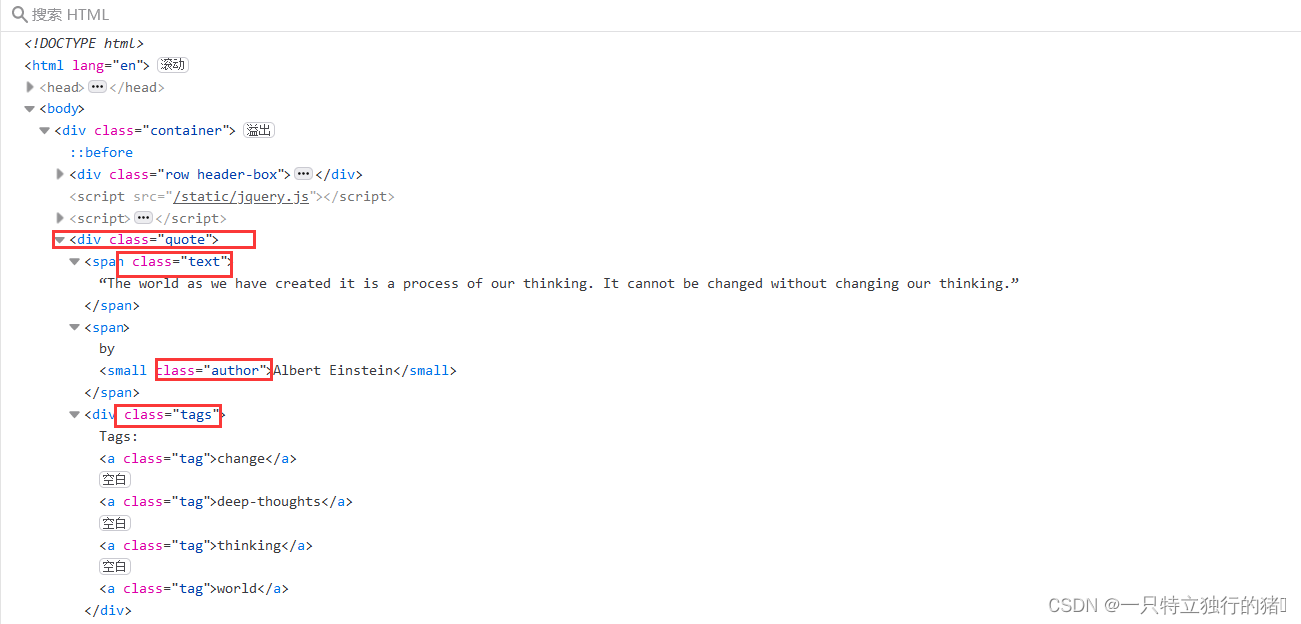
1.爬取网页元素
- 含有quote类的标签即为所要的标签
- text类名言,author为作者,tags为标签
2.按钮属性
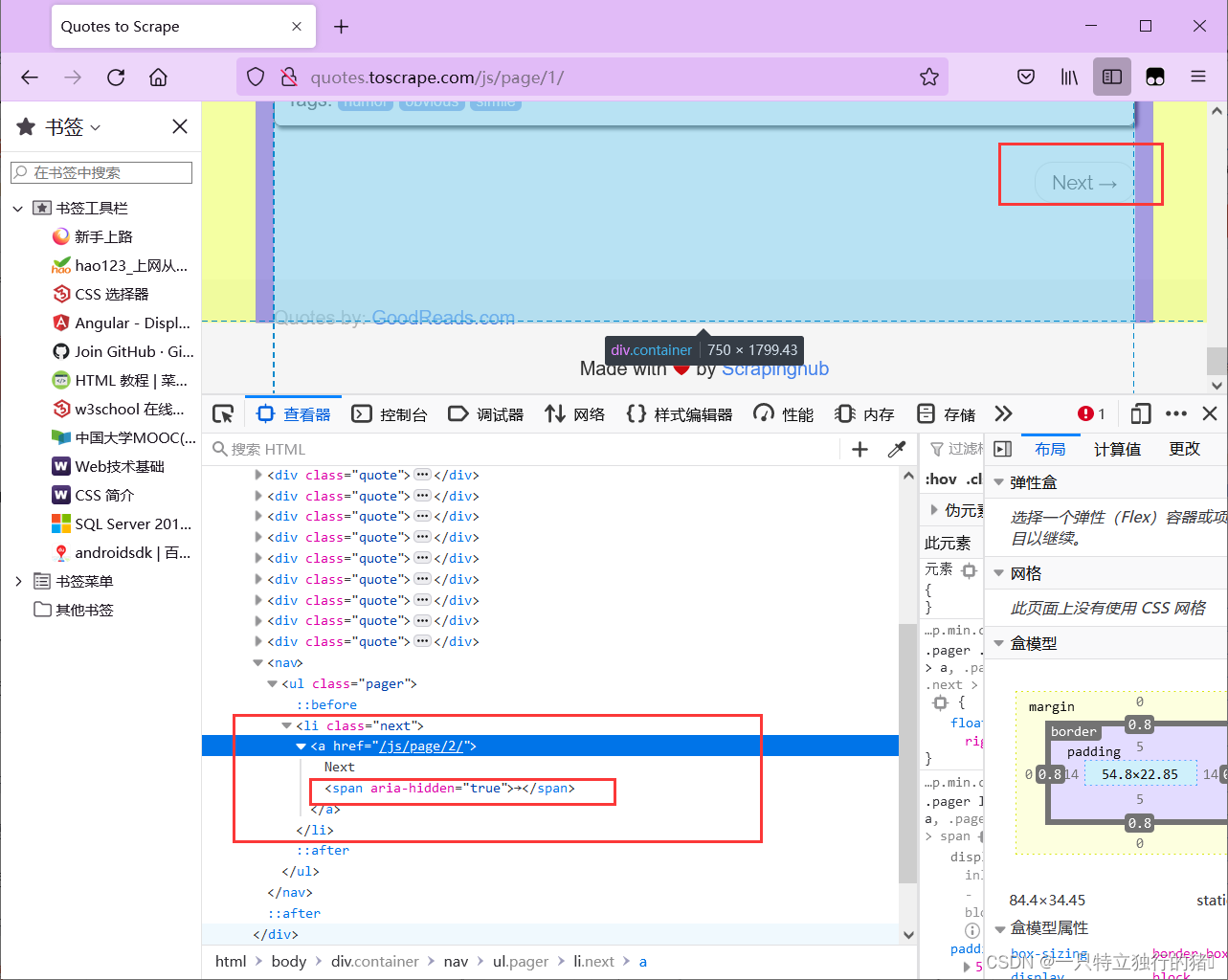
爬取一页后,需要进行翻页,即点击翻页按钮。
可发现Next按钮只有href属性,无法定位。且第一页只有下一页按钮,之后的页数有上一页和下一页按钮,则也无法通过xpath定位,而其子元素span(即箭头)在第一页中的属性aria-hidden是唯一的,在之后的页数中存在aria-hidden该属性,但Next的箭头总是最后一个。
因此可以通过查找最后一个有aria-hidden属性的span标签,进行点击以跳转到下一页:
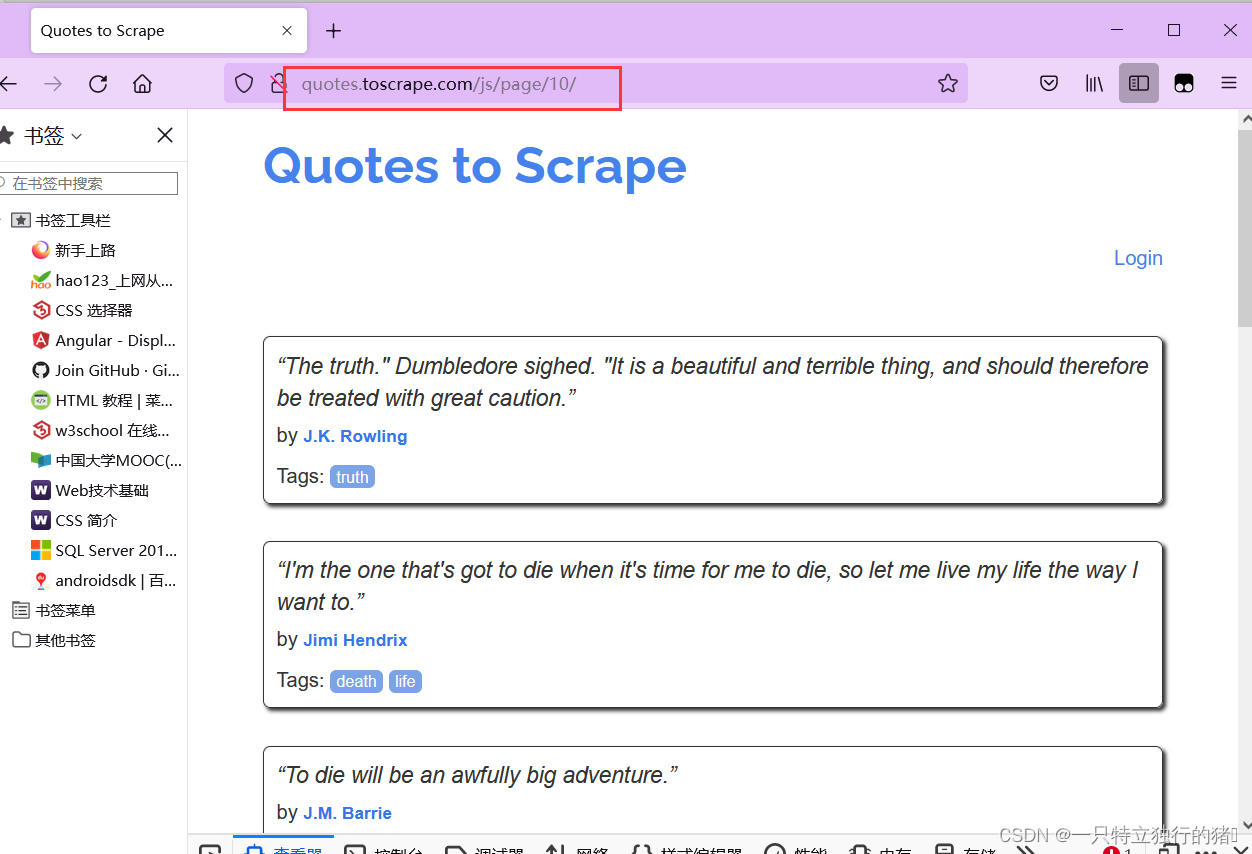
(3)网站页数
点击Nest,可以发现网站有10页
(三)代码实现
1.代码
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# 名言所在网站
driver.get("http://quotes.toscrape.com/js/")
# 所有数据
subjects = []
# 单个数据
subject=[]
#定义csv表头
quote_head=['名言','作者','标签']
#csv文件的路径和名字
quote_path='名人名言.csv'
#存放内容的列表
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
n = 10
for i in range(0, n):
driver.find_elements_by_class_name("quote")
res_list=driver.find_elements_by_class_name("quote")
# 分离出需要的内容
for tmp in res_list:
saying = tmp.find_element_by_class_name("text").text
author =tmp.find_element_by_class_name("author").text
tags =tmp.find_element_by_class_name("tags").text
subject=[]
subject.append(saying)
subject.append(author)
subject.append(tags)
print(subject)
subjects.append(subject)
subject=[]
write_csv(quote_head,subjects,quote_path)
print('成功爬取第' + str(i + 1) + '页')
if i == n-1:
break
driver.find_elements_by_css_selector('[aria-hidden]')[-1].click()
time.sleep(2)
driver.close()
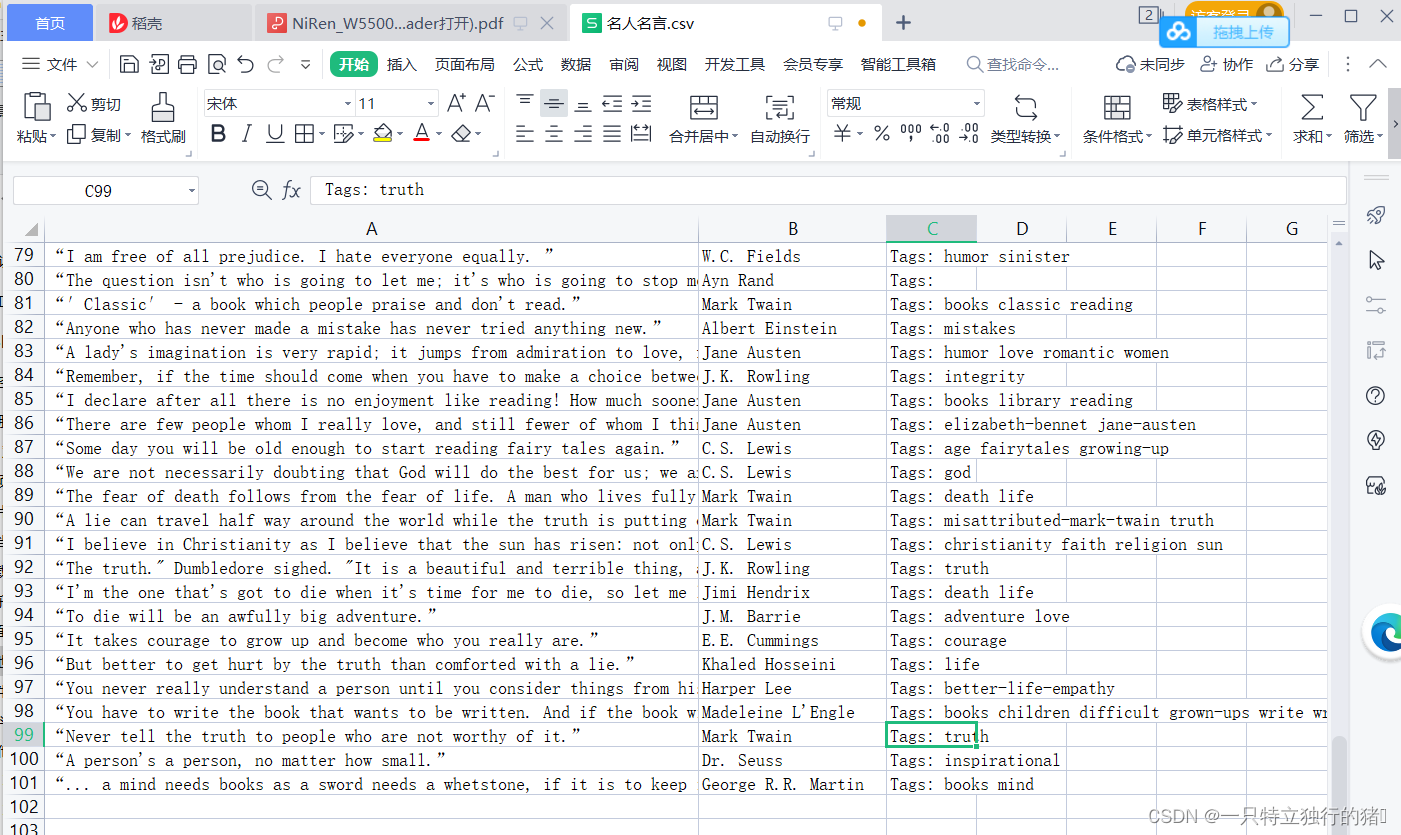
2.保存的爬取结果

表中信息一共有100条
四、爬取京东网站上的感兴趣书籍信息
(一)爬取网站
(二)网页分析
1.查看网站首页,输入框和搜索按钮
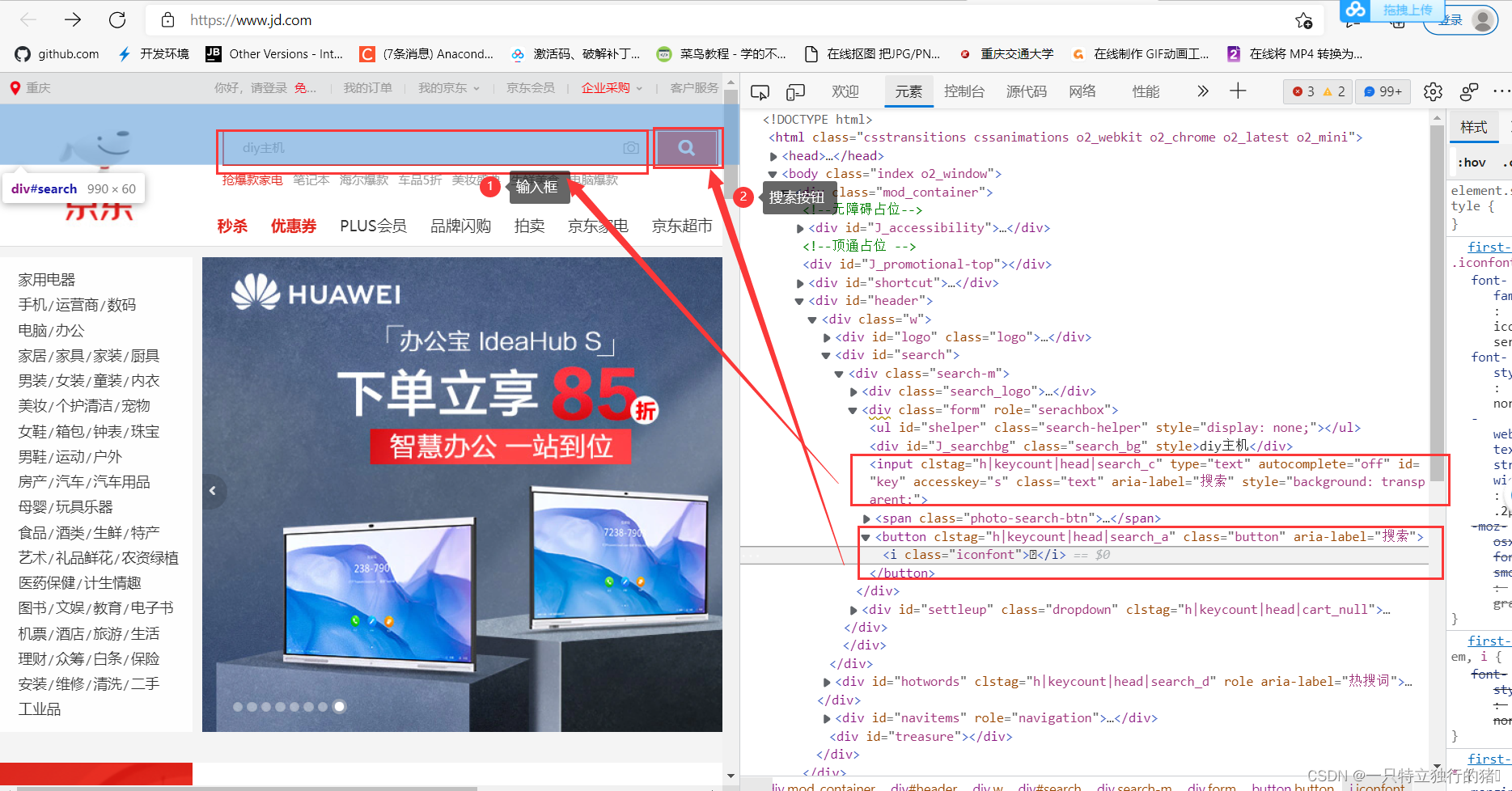
2.书籍展示列表,在J_goodsList下
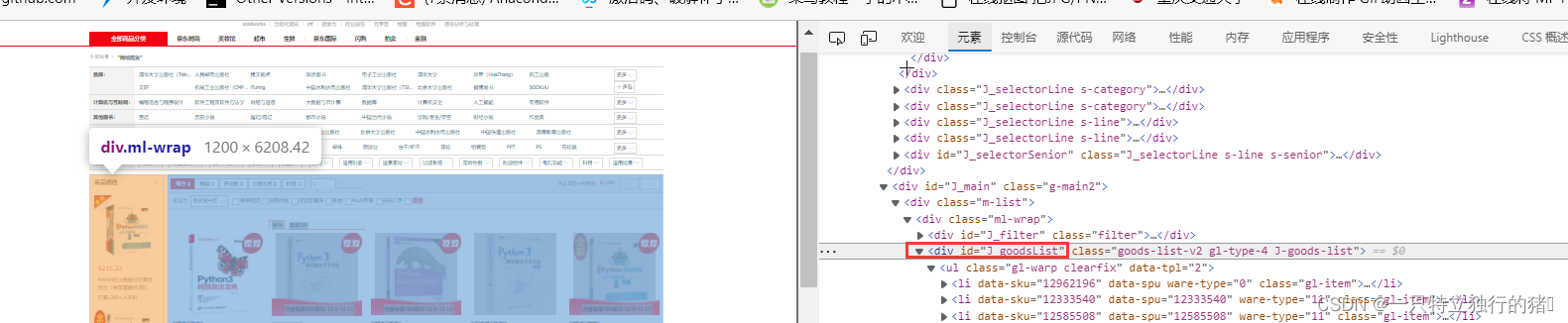
3.标签一一对应
每一个书籍详情就一个li标签
有很多个li标签
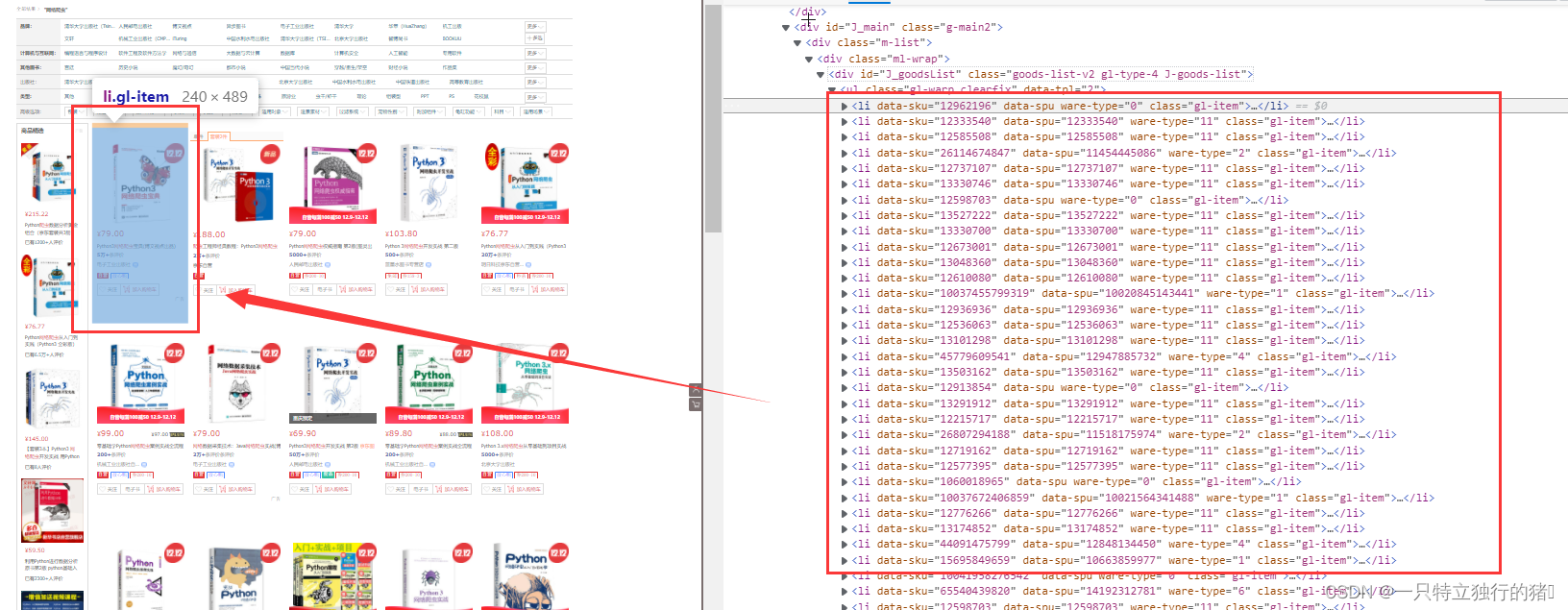
4.li中的具体内容

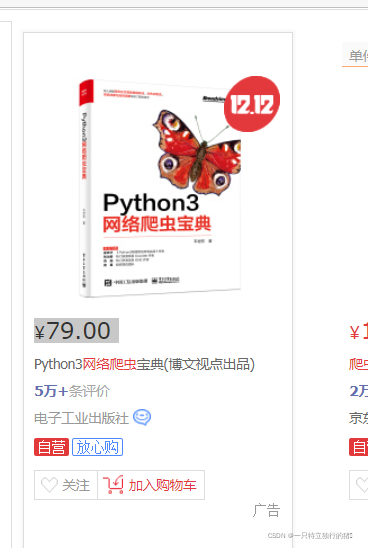
(1)价格

(2)书名
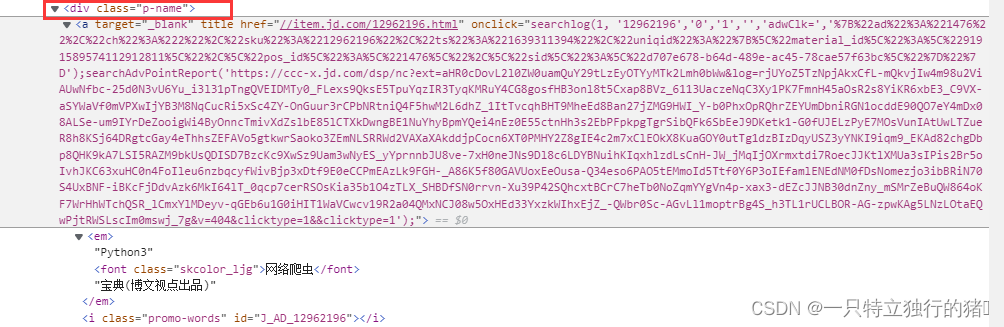
(3)出版社

5.下一页

(三)代码实现
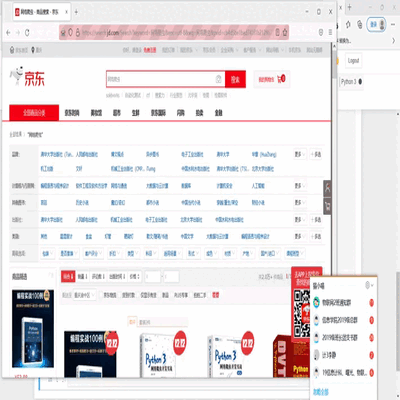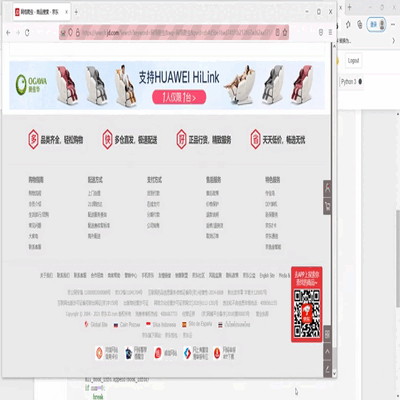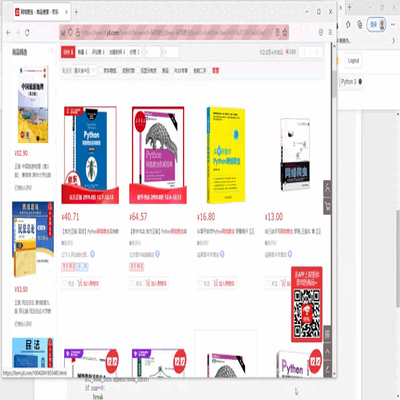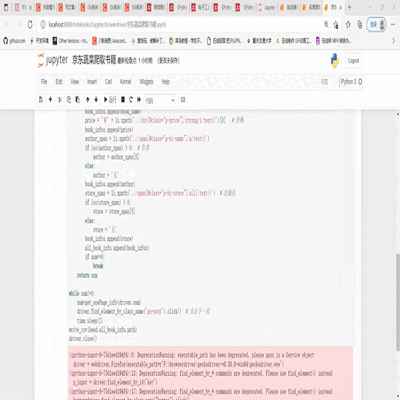
1.代码
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from lxml import etree
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# 京东所在网站
driver.get("https://www.jd.com/")
# 输入需要查找的关键字
p_input = driver.find_element_by_id('key')
p_input.send_keys('网络爬虫') # 找到输入框输入
time.sleep(1)
# 点击搜素按钮
button=driver.find_element_by_class_name("button").click()
time.sleep(1)
all_book_info = []
num=200
head=['书名', '价格', '作者', '出版社']
#csv文件的路径和名字
path='网络爬虫.csv'
def write_csv(head,all_book_info,path):
with open(path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(head)
fileWriter.writerows(all_book_info)
# 爬取一页
def get_onePage_info(web,num):
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(2)
page_text =driver.page_source
# with open('3-.html', 'w', encoding='utf-8')as fp:
# fp.write(page_text)
# 进行解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//li[contains(@class,"gl-item")]')
for li in li_list:
num=num-1
book_infos = []
book_name = ''.join(li.xpath('.//div[@class="p-name"]/a/em/text()')) # 书名
book_infos.append(book_name)
price = '¥' + li.xpath('.//div[@class="p-price"]/strong/i/text()')[0] # 价格
book_infos.append(price)
author_span = li.xpath('.//span[@class="p-bi-name"]/a/text()')
if len(author_span) > 0: # 作者
author = author_span[0]
else:
author = '无'
book_infos.append(author)
store_span = li.xpath('.//span[@class="p-bi-store"]/a[1]/text()') # 出版社
if len(store_span) > 0:
store = store_span[0]
else:
store = '无'
book_infos.append(store)
all_book_info.append(book_infos)
if num==0:
break
return num
while num!=0:
num=get_onePage_info(driver,num)
driver.find_element_by_class_name('pn-next').click() # 点击下一页
time.sleep(2)
write_csv(head,all_book_info,path)
driver.close()
2.爬取结果
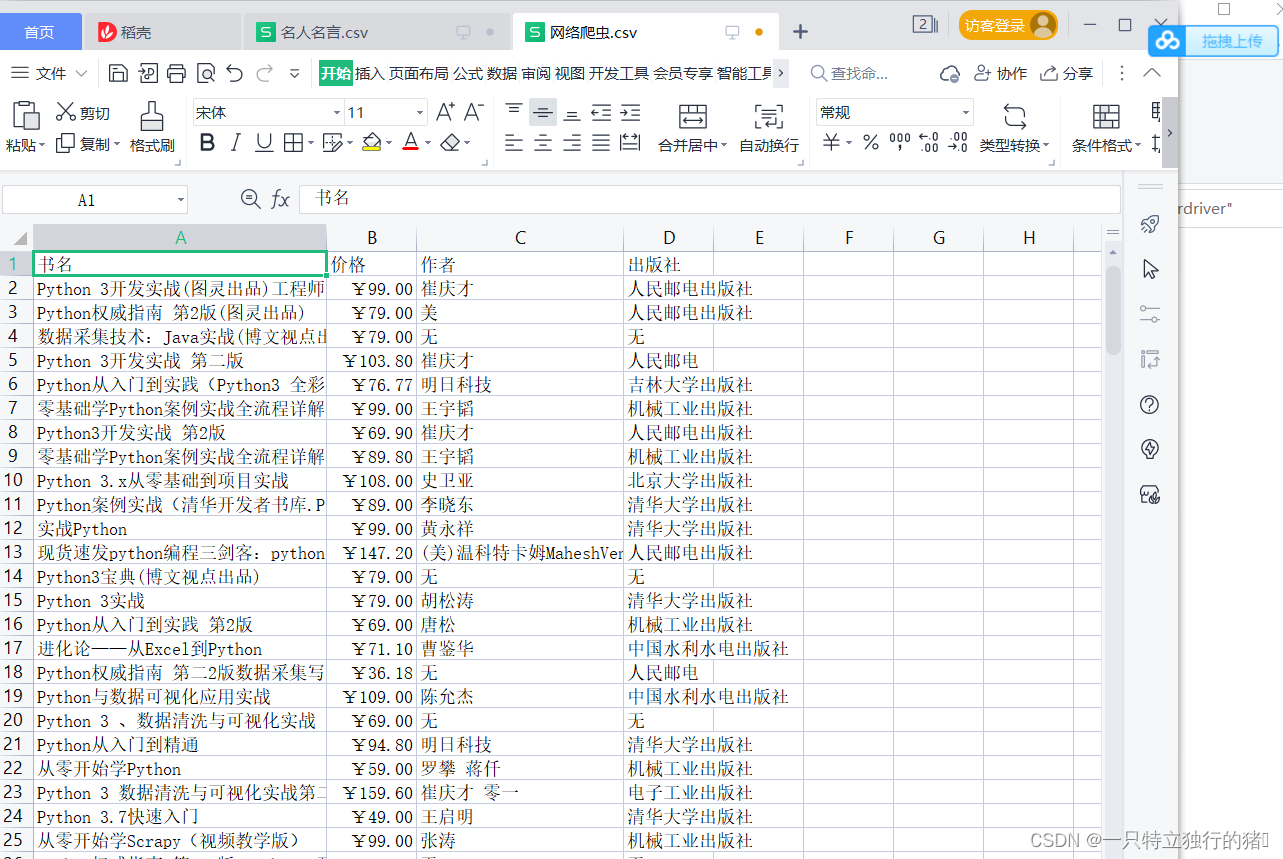
四、总结
本次实验是基于Python语言爬取网页的内容,对Selenium爬取网页的原理过程更加了解。
五、参考资料
Python+Selenium使用(一)- 自动打开百度并进行搜索
Python动态网页的信息爬取
Python基于Selenium实现爬取京东特定商品
Selenium:requests+Selenum爬取京东所有图书类的数据
selenium教程