老师要求我们把豆瓣电影Top250的电影爬下来,一开始觉得应该很简单,爬取一页或者几个是挺简单的,但是如果要把250个电影全部爬下来还是有点困难呢。主要遇到两点困难:
1.IP被封,决绝办法:用代理IP
2.需要验证码:

?

?那这怎么办呢?嘿嘿,难不倒我,我们不用去破解验证码,降低访问频率就可以
下面我们二话不说,直接上代码!!!
'''负责网页的爬取'''
def pach(url):
import requests
import time
import random
from lxml import etree
proxies = {"http": "120.194.55.139:6969"}
cookie = {
'Cookie': 'll="118174"; bid=tM6XNnqpZGw; __gads=ID=b856470f1040f298-229b0b9151cf0025:T=1638338161:RT=1638338161:S=ALNI_MaEdnBz_wjupMfpWkxY9bPEe1ypjw; _vwo_uuid_v2=DA6BC2B2730784262A1D6B601AF31610E|2a79a1a13e9345a9f31c20ba29fdcb4e; __yadk_uid=Ld477I1YQ3VoISOtyL9XwmlNzlcduMYA; dbcl2="249008593:3/r8a+ZSWdI"; ck=h22C; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1638441355%2C%22https%3A%2F%2Faccounts.douban.com%2F%22%5D; _pk_id.100001.4cf6=3253dcc614ccb4ac.1638338162.6.1638441355.1638370241.; _pk_ses.100001.4cf6=*; __utma=30149280.1716974694.1637678964.1638369435.1638441355.7; __utmb=30149280.0.10.1638441355; __utmc=30149280; __utmz=30149280.1638441355.7.2.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utma=223695111.601230768.1638338162.1638369435.1638441355.6; __utmb=223695111.0.10.1638441355; __utmc=223695111; __utmz=223695111.1638441355.6.2.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; push_noty_num=0; push_doumail_num=0'}
heads = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.34"}
random=random.randint(3,6)
time.sleep(random) # 降低访问速度
res = requests.get(url, headers=heads, cookies=cookie, proxies=proxies)
html = res.text
s = etree.HTML(html)
return s
'''每一页的url'''
def url_page():
urls = []
for page in range(0, 250, 25):
url = 'https://movie.douban.com/top250' + "?start=%s" % page
urls.append(url)
return urls
'''爬到每一个电影url,去重'''
def lj_url(s):
move = s.xpath("//ol//li/div/div/a/@href")
moves = list(set(move))
moves.sort(key=move.index)
return moves
'''详细内容的爬取'''
def details(move_s):
move_details = [] #存到详细内容的列表
titles = ["电影名", "导演", "编剧", "主演", "类型", "制片国家/地区", "语言", "上映日期", "片长", '豆瓣评分', '评价人数','在哪看', '排名']
name = ''.join(move_s.xpath("//h1/span[1]/text()"))
move_details.append(name)
details = ''.join(move_s.xpath("//div[@id='info']//text()"))
details = details.replace(" ", "").split()
for d in details:
list = d.split(":")
if list[0] in titles:
move_details.append(list[-1])
score = ''.join(move_s.xpath("//strong/text()"))
move_details.append(score)
people = ''.join(move_s.xpath("//a[@class='rating_people']/span/text()"))
move_details.append(people)
look = ''.join(move_s.xpath("//ul[@class='bs']//li/a/text()"))
look_money = ''.join(move_s.xpath("//ul[@class='bs']//li//span/text()"))
look = look.replace(" ", "").split()
look_money = look_money.replace(" ", "").split()
watchs = ''
for l, l_m in zip(look, look_money):
watch = "%s:%s;" % (l, l_m)
watchs += watch
move_details.append(watchs)
ranking = ''.join(move_s.xpath("//span[@class='top250-no']/text()"))
move_details.append(ranking)
return move_details, titles
'''存到excel表格'''
def excel_file(all_move_details, titles):
import xlwt
workbook = xlwt.Workbook(encoding="utf-8") # 创建一个工作簿
worksheet = workbook.add_sheet("sheet1") # 创建一个工作表
row = -1
high = 0 # 表格的行数
long = -1 # 表格的列数
for title in titles:
row += 1
worksheet.write(0, row, title)
for a_move in all_move_details:
high += 1
for a_details in a_move:
long += 1
worksheet.write(high, long, a_details)
long = -1
workbook.save("豆瓣电影top250.xls")
if __name__ == '__main__':
all_move_details = []
titles = []
urls_page = url_page() # 每一页的url列表,一共10页
for url_pg in urls_page:
page_s = pach(url_pg)
moves = lj_url(page_s) # 每一页里面有25条电影链接
for mv in moves:
move_s = pach(mv)
move_details, tit = details(move_s)
titles = tit
all_move_details.append(move_details)
excel_file(all_move_details, titles)
以上代码写的不是很好,不过没关系,能爬下来就行
爬取成果展示:
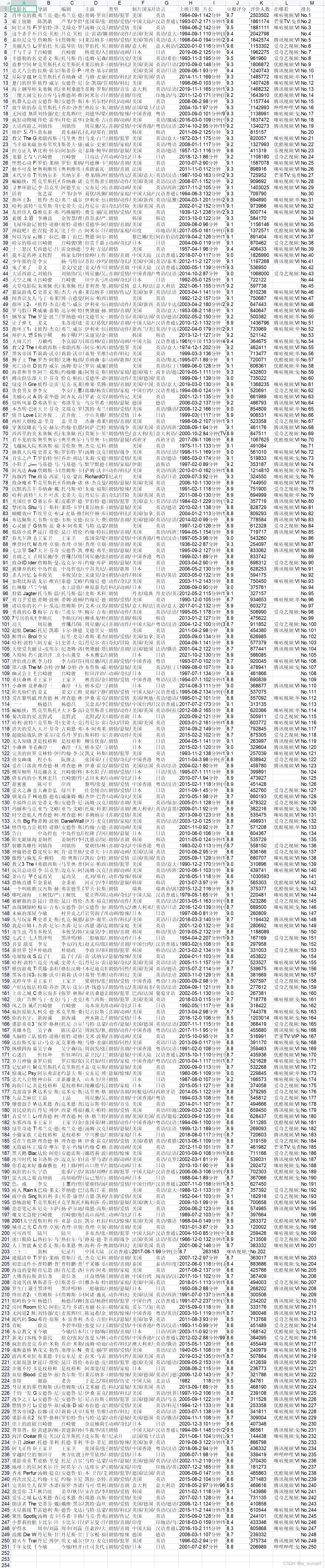
?nice!