简介
一般来说?Celery?是python可以执行定时任务, 但是不支持动态添加定时任务 (Django有插件可以动态添加), 而且对于不需要?Celery?的项目, 就会让项目变得过重.
APScheduler?支持持久化, 且可以动态添加定时任务.
$pip install apscheduler
APScheduler的各个组件的关系, 如下图:
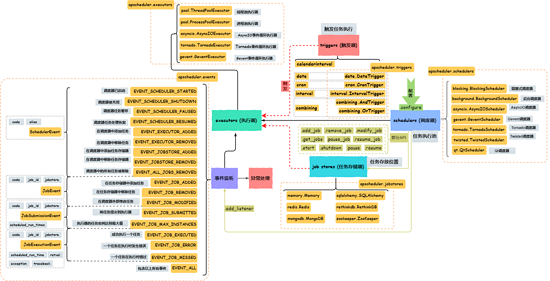
一般使用
步骤:
-
创建调度器
-
配置调度器
- 任务存储器
- 执行器
- 全局配置
-
添加任务
-
运行调度任务
-
修改/删除任务
除此之外, 可以监听事件, 执行自定义的函数
import datetime
from pytz import timezone
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.executors.pool import ProcessPoolExecutor
from apscheduler.jobstores.memory import MemoryJobStore
job_stores = {
'default': MemoryJobStore()
}
executors = {
'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
def hello_world():
print("hello world")
# 阻塞调度器
scheduler = BlockingScheduler()
scheduler.configure(jobstores=job_stores, executors=executors, job_defaults=job_defaults)
# 在当前时间的3秒后, 触发执行hello_world, 详情见: "触发器与调度器API"
scheduler.add_job(hello_world, "date", run_date=datetime.datetime.now() + datetime.timedelta(seconds=3),
timezone=timezone("Asia/Shanghai"))
scheduler.start()
调度器
配置作业存储器和执行器可以在调度器中完成。例如添加、修改、移除作业,根据不同的应用场景,可以选择不同的调度器,可选择的调度器如下:
# 阻塞式调度器 [ 调度器是你程序中唯一要运行的东西 ] from apscheduler.schedulers.blocking import BlockingScheduler # 后台调度器 [ 应用程序后台静默运行 ] from apscheduler.schedulers.background import BackgroundScheduler # AsyncIO调度器 [ 如果你的程序使用了 asyncio 库 ] from apscheduler.schedulers.asyncio import AsyncIOScheduler # Gevent调度器 [ 如果你的程序使用了 gevent 库 ] from apscheduler.schedulers.gevent import GeventScheduler # Tornado调度器 [ 如果你打算构建一个 Tornado 程序 ] from apscheduler.schedulers.tornado import TornadoScheduler # Twisted调度器 [ 如果你打算构建一个 Twisted 程序 ] from apscheduler.schedulers.twisted import TwistedScheduler # Qt调度器 [ 如果你打算构建一个 Qt 程序 ] from apscheduler.schedulers.qt import QtScheduler
在使用非阻塞的调度器时需要注意:?程序是否会退出从而无法执行任务
配置
有3种方式配置
方式一
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
# 键为名称
# 值为字典 实例化对象作为值, 参数直接在实例化时传入
jobstores = {
'mongo': MongoDBJobStore(),
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors,
job_defaults=job_defaults, timezone=utc)
方式二
from pytz import utc
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ProcessPoolExecutor
# 键为名称,值要为字典,type指定调度器, 其它键值对指定参数
jobstores = {
'mongo': {'type': 'mongodb'},
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': {'type': 'threadpool', 'max_workers': 20},
'processpool': ProcessPoolExecutor(max_workers=5)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BackgroundScheduler()
scheduler.configure(jobstores=jobstores, executors=executors, job_defaults=job_defaults, timezone=utc)
方式三
from apscheduler.schedulers.background import BackgroundScheduler
# 前缀 "apscheduler." 是硬编码的
# apscheduler.jobstores指定任务存储器
# apscheduler.executors指定执行器
# 最后的 "." 指定名称
scheduler = BackgroundScheduler({
'apscheduler.jobstores.mongo': {
'type': 'mongodb'
},
'apscheduler.jobstores.default': {
'type': 'sqlalchemy',
'url': 'sqlite:///jobs.sqlite'
},
'apscheduler.executors.default': {
'class': 'apscheduler.executors.pool:ThreadPoolExecutor',
'max_workers': '20'
},
'apscheduler.executors.processpool': {
'type': 'processpool',
'max_workers': '5'
},
'apscheduler.job_defaults.coalesce': 'false',
'apscheduler.job_defaults.max_instances': '3',
'apscheduler.timezone': 'UTC',
})
default?这个名字是可以手动指定,但不指定时,APScheduler会使用默认值(调用?add_executor?/?add_jobstore?)
执行器
处理作业的运行,通常通过在作业中提交指定的可调用对象到一个线程或者进程池来进行,当作业完成时,执行器会将通知调度器
步骤:
- 将执行器加入到调度器
- 添加任务时,指定执行器
# 线程池执行器 from apscheduler.executors.pool import ThreadPoolExecutor # 进程池执行器 from apscheduler.executors.pool import ProcessPoolExecutor # AsyncIO事件循环执行器 from apscheduler.executors.asyncio import AsyncIOExecutor # Gevent事件循环执行器 from apscheduler.executors.gevent import GeventExecutor # Tornado事件循环执行器 from apscheduler.executors.tornado import TornadoExecutor
默认ThreadPoolExecutor
ThreadPoolExecutor?和?ProcessPoolExecutor?分别调用?concurrent.futures.ThreadPoolExecutor?和?concurrent.futures.ProcessPoolExecutor?, 参数有:max_workers=10, pool_kwargs=None
使用例子
import datetime
from pytz import timezone
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.executors.pool import ThreadPoolExecutor
executors = {
'pool': ThreadPoolExecutor(max_workers=5)
}
def hello_world():
print("hello world")
scheduler = BlockingScheduler()
# 添加到配置文件
scheduler.configure(executors=executors)
# 指定执行器
scheduler.add_job(hello_world, "date", run_date=datetime.datetime.now() + datetime.timedelta(seconds=3),
timezone=timezone("Asia/Shanghai"), executor="pool")
scheduler.start()
任务存储器
存储被调度的作业,默认的作业存储器只是简单地把作业保存在内存中,其他的作业存储器则是将作业保存在数据库中,当作业被保存在一个持久化的作业存储器中的时候,该作业的数据会被序列化,并在加载时被反序列化,需要说明的是,?作业存储器不能共享调度器?。
步骤:
- 定义任务存储器
- 使用任务存储器
# 内存任务存储器 from apscheduler.jobstores.memory import MemoryJobStore # 使用SQLAlchemy ORM的任务存储器 from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore # MongoDB任务存储器 from apscheduler.jobstores.mongodb import MongoDBJobStore # Redis任务存储器 from apscheduler.jobstores.redis import RedisJobStore # RethinkDB任务存储器 from apscheduler.jobstores.rethinkdb import RethinkDBJobStore # ZooKeeper任务存储器 from apscheduler.jobstores.zookeeper import ZooKeeperJobStore
默认MemoryJobStore
一般使用
import datetime
from pytz import timezone
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.redis import RedisJobStore
job_stores = {
'redis': RedisJobStore()
}
def hello_world():
print("hello world")
scheduler = BlockingScheduler()
scheduler.configure(jobstores=job_stores)
scheduler.add_job(hello_world, "date", run_date=datetime.datetime.now() + datetime.timedelta(seconds=3),
timezone=timezone("Asia/Shanghai"), jobstore="redis")
scheduler.start()
SQLAlchemyJobStore使用
sqlalchemy + mysql
"""
SQLAlchemyJobStore(url=None, engine=None, tablename='apscheduler_jobs',
metadata=None, ..., tableschema=None, engine_options=None):
指定URL时,内部调用,create_engine
URL的字符串形式为 dialect[+driver]://user:password@host/dbname[?key=value..]
在哪里 dialect 是数据库名称,例如 mysql , oracle , postgresql 等,
以及 driver DBAPI的名称,例如 psycopg2 , pyodbc , cx_oracle 或者
# 使用DB API格式建立建立连接, 见PEP: https://www.python.org/dev/peps/pep-0249/
"""
import datetime
from pytz import timezone
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
MYSQL = {
"url": "mysql+pymysql://root:123456@localhost/test"
}
job_stores = {
'mysql': SQLAlchemyJobStore(**MYSQL)
}
def hello_world():
print("hello world")
scheduler = BlockingScheduler()
scheduler.configure(jobstores=job_stores)
scheduler.add_job(hello_world, "date", run_date=datetime.datetime.now() + datetime.timedelta(seconds=3),
timezone=timezone("Asia/Shanghai"), jobstore="mysql")
scheduler.start()
RedisJobStore使用
"""
RedisJobStore(db=0, jobs_key='apscheduler.jobs', run_times_key='apscheduler.run_times', ..., **connect_args)
调用 Redis(db=int(db), **connect_args)
Redis的参数:
host='localhost', port=6379,
db=0, password=None, socket_timeout=None,
socket_connect_timeout=None,
socket_keepalive=None, socket_keepalive_options=None,
connection_pool=None, unix_socket_path=None,
encoding='utf-8', encoding_errors='strict',
charset=None, errors=None,
decode_responses=False, retry_on_timeout=False,
ssl=False, ssl_keyfile=None, ssl_certfile=None,
ssl_cert_reqs='required', ssl_ca_certs=None,
ssl_check_hostname=False,
max_connections=None, single_connection_client=False,
health_check_interval=0, client_name=None, username=None
"""
import datetime
from pytz import timezone
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.redis import RedisJobStore
REDIS = {
'host': '127.0.0.1',
'port': '6379',
'db': 0,
}
job_stores = {
'redis': RedisJobStore(**REDIS)
}
def hello_world():
print("hello world")
scheduler = BlockingScheduler()
scheduler.configure(jobstores=job_stores)
scheduler.add_job(hello_world, "date", run_date=datetime.datetime.now() + datetime.timedelta(seconds=3),
timezone=timezone("Asia/Shanghai"), jobstore="redis")
scheduler.start()
其它自己查资料
全局配置
from apscheduler.schedulers.blocking import BlockingScheduler
job_defaults = {
'coalesce': False, # 关闭聚合(coalescing)功能
'max_instances': 3, # 默认限制最大实例数为 3
"timezone": "UTC", # 调度器的时区
}
scheduler = BlockingScheduler()
scheduler.configure(job_defaults=job_defaults)
关于coalescing, 见:错过的作业执行以及合并操作
调度器API
以下方法为调度器的API
添加任务
使用?.add_job?直接添加或使用?.scheduled_job?作为装饰器添加任务,
例如:
# ....
def hello_world():
print("hello_world")
scheduler = BlockingScheduler()
scheduler.add_job(hello_world, ...)
# ....
# ############## 或
# ...
scheduler = BlockingScheduler()
@scheduler.scheduled_job(...)
def hello_world():
print("hello_world")
# ...
add_job?签名 (?scheduled_job参数相同?)
def add_job(self, func, trigger=None, args=None, kwargs=None, id=None, name=None, misfire_grace_time=undefined, coalesce=undefined, max_instances=undefined, next_run_time=undefined, jobstore='default', executor='default', replace_existing=False, **trigger_args)
- func:?任务函数
- trigger:?触发器
- args:?给func的位置参数
- kwargs:?给func的关键字参数
- id: 指定任务的标识
- name: 任务的说明
- misfire_grace_time: 见:错过的作业执行以及合并操作
- coalesce: 如果调度器确定任务应该连续运行一次以上,则运行一次而不是多次, 见:错过的作业执行以及合并操作
- max_instances: 任务允许的最大并发运行实例数
- next_run_time: 没用过
- jobstore?指定任务存储器
- executor?指定执行器
- replace_existing :?
True?时, 用相同的?id?替换现有任务
.add_job?返回?apscheduler.job.Job?实例, 见:?Job
触发器为空时, 立即执行
例子
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
def hello_world():
print("hello_world")
scheduler = BlockingScheduler()
scheduler.add_job(hello_world, "date", run_date=datetime.datetime.now() + datetime.timedelta(seconds=3),
timezone="Asia/Shanghai")
scheduler.start()
触发器
触发器中包含调度逻辑,每个作业都有自己的触发器来决定下次运行时间。除了它们自己初始配置以外,触发器完全是无状态的。
-
date?日期触发只执行一次
签名:
classapscheduler.triggers.date.DateTrigger(run_time: datetime.datetime, timezone: Union[datetime.tzinfo, str] = 'local') # run_time: 任务执行时间 datetime # timezone: 时区
例子:
from datetime import date from apscheduler.schedulers.blocking import BlockingScheduler scheduler = BlockingScheduler() def my_job(text): print(text) # 在2021年12月3日执行 scheduler.add_job(my_job, 'date', run_date=date(2021, 12, 3), args=['text']) scheduler.start()
立即执行
from datetime import date from apscheduler.schedulers.blocking import BlockingScheduler scheduler = BlockingScheduler() def my_job(text): print(text) # 立刻运行 scheduler.add_job(my_job, 'date', args=['text'], timezone="Asia/shanghai") scheduler.start()
-
interval?间隔触发每隔一段时间执行一次
签名:
classapscheduler.triggers.interval.IntervalTrigger(*, weeks: float = 0, days: float = 0, hours: float = 0, minutes: float = 0, seconds: float = 0, microseconds: float = 0, start_time: Optional[datetime.datetime] = None, end_time: Optional[datetime.datetime] = None, timezone: Union[datetime.tzinfo, str] = 'local') # weeks 间隔礼拜数 (int) # days 间隔天数 (int) # hours 间隔小时数 (int) # minutes 间隔分钟数 (int) # seconds 间隔秒数 (int) # start_date 周期执行的起始时间点(datetime|str) # end_date 最后可能触发时间 (datetime|str) # timezone 计算date/time类型时需要使用的时区 (datetime.tzinfo|str)
例子:
from datetime import datetime from apscheduler.schedulers.blocking import BlockingScheduler def job_function(): print("Hello World") schedulers = BlockingScheduler() # 每隔2秒, 执行一次 schedulers.add_job(job_function, 'interval', seconds=2, timezone="Asia/shanghai") schedulers.start() -
cron?周期触发使用类似?
crontab?的格式定义触发时间签名:
classapscheduler.triggers.cron.CronTrigger(*, year: Optional[Union[int, str]] = None, month: Optional[Union[int, str]] = None, day: Optional[Union[int, str]] = None, week: Optional[Union[int, str]] = None, day_of_week: Optional[Union[int, str]] = None, hour: Optional[Union[int, str]] = None, minute: Optional[Union[int, str]] = None, second: Optional[Union[int, str]] = None, start_time: Optional[Union[datetime.datetime, str]] = None, end_time: Optional[Union[datetime.datetime, str]] = None, timezone: Optional[Union[str, datetime.tzinfo]] = None) """ 参数: year(int|str) 4 位年份 month(int|str) 2 位月份(1-12) day(int|str) 一个月内的第几天(1-31) week(int|str) ISO 礼拜数(1-53) day_of_week(int|str) 一周内的第几天(0-6 或者 mon, tue, wed, thu, fri, sat, sun) hour(int|str) 小时(0-23) minute(int|str) 分钟(0-59) second(int|str) 秒(0-59) start_date(datetime|str) 最早可能触发的时间(date/time),含该时间点 end_date(datetime|str) 最后可能触发的时间(date/time),含该时间点 timezone(datetime.tzinfo|str) 计算 date/time 时所指定的时区(默认为 scheduler 的时区) """
不指定参数时, 为?
*一般使用:
from apscheduler.schedulers.blocking import BlockingScheduler def job_function(): print("Hello World") scheduler = BlockingScheduler() # 每分钟的第2秒执行一次 scheduler.add_job(job_function, 'cron', second=2, timezone="Asia/shanghai") scheduler.start()假如熟练使用corn, 可以使用corntab语法,
表达 应用字段 描述 *any 任意时间 */aany 每隔多长时间, 如:? */10 4 * * *?, 4点每隔10分钟执行一次(4:10 4:20 ...)a-bany 在? a-b?范围内的通配符a-b/cany 在? a-b?范围内可被?c?整除的通配符xth yday 表示一个月内的第? x?个礼拜的星期?ylast xday 表示一个月内最后的星期? x?触发lastday 表示月末当天触发 x,y,zany 其他表达式可以组合的形式, 即不连续的时间 例子:
注意没有?
cron?, 直接指定触发器from apscheduler.schedulers.blocking import BlockingScheduler from apscheduler.triggers.cron import CronTrigger def job_function(): print("Hello World") scheduler = BlockingScheduler() # 五个占位符: # 第一个 一小时的第几分钟 # 第二个 一天的第几个小时 # 第三个 一月的第几天 # 第四个 一年的第几月 # 第五个 一周的星期几 # 例子: """ 45 22 * * * 每天22:45 0 17 * * 1 每周一的17:00 0 4 1,15 * * 1号或15号的4:00 40 4 * * 1-5 周一到周五的4:40 */10 4 * * * 四点的每10分钟(4:10、4:20......) """ # 每2分钟执行一次 scheduler.add_job(job_function, CronTrigger.from_crontab("*/2 * * * *", timezone="Asia/shanghai")) scheduler.start() -
calendarinterval
见:?apscheduler.triggers.calendarinterval -
combining
见:?apscheduler.triggers.combining
移除任务
当从 scheduler 中移除一个 job 时,它会从关联的 job store 中被移除,不再被执行。
两种方法:
job = scheduler.add_job(myfunc, 'interval', minutes=2)
job.remove()
# 或使用ID
scheduler.add_job(myfunc, 'interval', minutes=2, id='my_job_id')
scheduler.remove_job('my_job_id')
修改任务
例子:
job = scheduler.add_job(myfunc, 'interval', minutes=2, id="my_job_id")
job.modify(args=["lczmx", ]max_instances=6, name='Alternate name')
# 根据ID修改
scheduler.modify_job("my_job_id", args=["lczmx", ])
# 重新调度
scheduler.reschedule_job('my_job_id', trigger='cron', minute='*/5')
暂停或恢复任务
通过 Job 实例或者 scheduler 本身你可以轻易地暂停和恢复 job 。当一个 job 被暂停,它的下一次运行时间将会被清空,同时不再计算之后的运行时间,直到这个 job 被恢复。
from apscheduler.schedulers.blocking import BlockingScheduler
def job_function():
print("Hello world")
scheduler = BlockingScheduler()
job = scheduler.add_job(job_function, "interval", seconds=2, timezone="Asia/shanghai", id="my_job_id")
# ################# 暂停 ###########
job.pause()
# 或
scheduler.pause_job("my_job_id")
# ################# 恢复 ###########
job.resume()
# 或
scheduler.resume_job("my_job_id")
scheduler.start()
查看任务信息
from apscheduler.schedulers.blocking import BlockingScheduler
def job_function():
print("Hello world")
scheduler = BlockingScheduler()
job = scheduler.add_job(job_function, "interval", seconds=2, timezone="Asia/shanghai", id="my_job_id")
# 获取某个任务的信息, 需要id, 可以指定job store
print(scheduler.get_job("my_job_id"))
# 获取全部任务信息列表, 可以指定job store
print(scheduler.get_jobs())
# 格式化输出任务信息, 可以指定job store
# !! 内部调用print
scheduler.print_jobs()
scheduler.start()
终止调度器
# 一般使用 # 默认会等待 目前 正在执行 所有任务执行完 scheduler.shutdown() # 使用wait参数指定不等待 scheduler.shutdown(wait=False)
暂停/恢复调度器
from apscheduler.schedulers.blocking import BlockingScheduler
def job_function():
print("Hello world")
scheduler = BlockingScheduler()
job = scheduler.add_job(job_function, "interval", seconds=2, timezone="Asia/shanghai", id="my_job_id")
# 休眠这个调度器
scheduler.pause()
# 恢复这个调度器
scheduler.resume()
# 使用 .start , 唤醒处于暂停状态的调度器
scheduler.start(paused=True)
scheduler.start()
添加事件
你可以为 scheduler 绑定事件监听器(event listen)。Scheduler 事件在某些情况下会被触发,而且它可能携带有关特定事件的细节信息。
使用?.add_listener?来添加时间监听, 参数:
- callback 回调函数
- mask 事件
所有事件有如下表
| 事件 | 说明 | 回调函数的参数(Event类) |
|---|---|---|
| EVENT_SCHEDULER_STARTED | 调度器已启动 | SchedulerEvent |
| EVENT_SCHEDULER_SHUTDOWN | 调度器被关闭 | SchedulerEvent |
| EVENT_SCHEDULER_PAUSED | 调度器任务暂停 | SchedulerEvent |
| EVENT_SCHEDULER_RESUMED | 调度器任务处理恢复 | SchedulerEvent |
| EVENT_EXECUTOR_ADDED | 在调度器中添加任务 | SchedulerEvent |
| EVENT_EXECUTOR_REMOVED | 在调度器中移除任务 | SchedulerEvent |
| EVENT_JOBSTORE_ADDED | 在调度器中添加任务存储器 | SchedulerEvent |
| EVENT_JOBSTORE_REMOVED | 在调度器中移除任务存储器 | SchedulerEvent |
| EVENT_ALL_JOBS_REMOVED | 调度器中的所有任务被移除 | SchedulerEvent |
| EVENT_JOB_ADDED | 在任务存储器中添加任务 | JobEvent |
| EVENT_JOB_REMOVED | 在任务存储器中移除任务 | JobEvent |
| EVENT_JOB_MODIFIED | 在调度器外部修改任务 | JobEvent |
| EVENT_JOB_SUBMITTED | 将任务提交到执行器 | JobSubmissionEvent |
| EVENT_JOB_MAX_INSTANCES | 执行器的可执行任务数达到最大值 | JobSubmissionEvent |
| EVENT_JOB_EXECUTED | 成功执行一个任务 | JobExecutionEvent |
| EVENT_JOB_ERROR | 一个任务在执行时发生错误 | JobExecutionEvent |
| EVENT_JOB_MISSED | 一个任务在执行时错过 | JobExecutionEvent |
| EVENT_ALL | 所有事件 | 根据上面事件动态传入类 |
与调度器相关事件:?apscheduler.events.SchedulerEvent?属性
code alias
与任务相关事件:?apscheduler.events.JobEvent?属性
code job_id jobstore
向执行器提交任务的相关事件:?apscheduler.events.JobSubmissionEvent?属性
code job_id jobstore scheduled_run_times
任务执行在执行器的相关事件:?apscheduler.events.JobExecutionEvent?属性
code job_id jobstore scheduled_run_time retval exception traceback
例子:
from apscheduler.schedulers.blocking import Blockin gScheduler
from apscheduler.events import *
from apscheduler.events import SchedulerEvent
def my_listener(event):
if event.exception:
print('发生异常')
else:
print('任务已经执行')
def job_function():
print("Hello world")
scheduler = BlockingScheduler()
# 立即执行
job = scheduler.add_job(job_function, timezone="Asia/shanghai")
scheduler.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
scheduler.start()
故障排查
如果 scheduler 没有如预期般正常运行,可以尝试将?apscheduler?的?logger?的日志级别提升到?DEBUG?等级。
如果你还没有在一开始就将日志启用起来,那么你可以:
import logging
logging.basicConfig()
logging.getLogger('apscheduler').setLevel(logging.DEBUG)
这会提供 scheduler 运行时大量的有用信息。
最大允许实例
默认情况下,每个任务同时只会有一个实例在运行。这意味着如果 一个任务到达计划运行时间点时,前一个任务尚未完成,那么这个 任务最近的一次运行计划将会 misfire(错过)。
可以通过在?添加任务?时指定?max_instances?关键字参数, 来设置具体任务的最大实例数目,以便?scheduler?随后可以?并发?地执行它。
错过的作业执行以及合并操作
即: coalescing
有时候?scheduler?无法在被调度的任务的计划运行时间点去执行这个任务。
常见的原因是: 这个 任务是在持久化的?job store?中,恰好在其打算运行的时刻?scheduler?被关闭或重启了。
这样,这个 任务 就被定义为 misfired (错过)。?scheduler?稍后会检查 任务每个被错过的执行时间的?misfire_grace_time?选项(可以单独给每个 任务设置或者给 scheduler 做全局设置),以此来确定这个执行操作是否要继续被触发。?这可能到导致连续多次执行。
如果这个行为不符合你的实际需要,可以使用?coalescing?来,?回滚所有?的被?错过?的执行操作为?唯一?的一个操作。如果对 任务启用?coalescing?,那么即便 scheduler 在队列中看到这个 任务一个或多个执行计划,scheduler 都?只会触发一次?。
注意:
如果因为进程(线程)池中没有可用的进程(线程)而导致 任务的运行被推迟了,那么 执行器 会直接跳过它,因为相对于原计划的执行时间来说实在太 "晚" 了。
如果在你的应用程序中出现了这种情况,你可以增加 执行器的线程(进程)的数目,或者调整?misfire_grace_time?,设置一个更高的值。

?
?