- 访问指定的URL需要导入【urllib.request】、【urllib.error】包,获取网页的HTML数据。
- 解析HTML数据需要导入【BeautifulSoup】包,将网页的HTML数据解析成树形结构并返回。
- 在HTML文件结构中,标签是层层嵌套的,每一个标签可以看作是树形结构的一个结点,通过调用select()方法可以查询指定的结点并返回。
- 以【’.item’】为例,表示在当前结点下查询class="item"的标签;以【’.bd>p’】为例,表示在当前结点下查询class="bd"的标签的子标签<p>。
- 查询的结果以列表的形式存储,每个元素即为一个标签,若要得到标签的内容,获取text属性值即可,如【title = tag[0].text】。
- 标签的属性值以字典的形式存储,若要得到某个属性值,传入其属性名即可,如【link = tag[0][‘href’]】。
- 利用正则表达式对获取到的字符串进行处理。
- 注意控制访问的速度,避免触发网站的反爬机制。
import random
import re
import time
import urllib.error
import urllib.request
import xlwt
from bs4 import BeautifulSoup
def main():
baseurl = 'https://movie.douban.com/top250?start='
data = getData(baseurl)
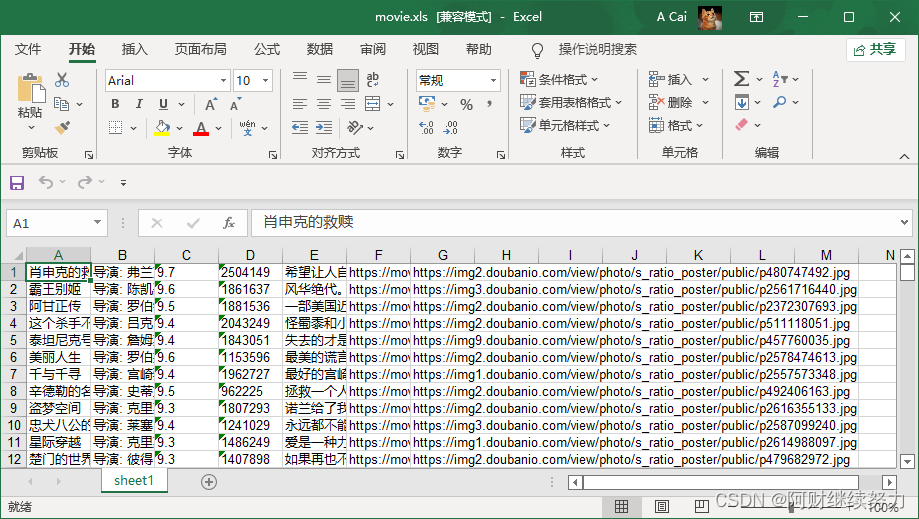
path = 'movie.xls'
saveData(path, data)
def getData(baseurl):
data = []
for i in range(10):
url = baseurl + str(i * 25)
print(time.strftime('%Y-%m-%d %H:%M:%S'), url)
html = getHtml(url)
bs = BeautifulSoup(html, 'html.parser')
# 数据块 <div class="item">
for item in bs.select('.item'):
temp = []
# 标题 <span class="title">肖申克的救赎</span>
tag = item.select('.title')
if len(tag) > 0:
title = tag[0].text
else:
title = ''
temp.append(title)
# 详情 <p class="">
tag = item.select('.bd>p')
if len(tag) > 0:
detail = tag[0].text
detail = detail.strip()
detail = re.sub(r'\xa0', ' ', detail)
detail = re.sub(r'\n\s+', ' ', detail)
else:
detail = ''
temp.append(detail)
# 评分 <span class="rating_num" property="v:average">9.7</span>
tag = item.select('.rating_num')
if len(tag) > 0:
score = tag[0].text
else:
score = 0
temp.append(score)
# 人数 <span>2504130人评价</span>
tag = item.select('.star>span')
if len(tag) > 0:
people = tag[3].text
people = re.findall(r'\d+\.?\d*', people)[0]
else:
people = 0
temp.append(people)
# 概括 <span class="inq">希望让人自由。</span>
tag = item.select('.inq')
if len(tag) > 0:
summary = tag[0].text
else:
summary = ''
temp.append(summary)
# 链接 <a href="https://movie.douban.com/subject/1292052/">
tag = item.select('.pic>a')
if len(tag) > 0:
link = tag[0]['href']
else:
link = ''
temp.append(link)
# 图片 <img width="100" alt="肖申克的救赎" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp" class="">
tag = item.select('.pic>a>img')
if len(tag) > 0:
image = tag[0]['src']
else:
image = ''
temp.append(image)
data.append(temp)
time.sleep(random.uniform(3, 5))
return data
def getHtml(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36 Edg/96.0.1054.53'
}
request = urllib.request.Request(url=url, headers=headers, method='GET')
response = None
try:
response = urllib.request.urlopen(request, timeout=2)
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
return response
def saveData(path, data):
book = xlwt.Workbook()
sheet = book.add_sheet('sheet1')
for i in range(len(data)):
for j in range(len(data[i])):
sheet.write(i, j, data[i][j])
book.save(path)
if __name__ == '__main__':
main()