SANER 2020�ϵ�һƪPoster
���
����ִ�����������Ժͳ��������һ������Ҫ�ļ�����·����ը�Ƿ���ִ����һ�������ص����⡣Ϊ�˻����������,���������һ�ֻ���Q-learning���㷨��ָ������ִ�С�
����
Q-learning�㷨��һ��model-free off-policy���㷨������һ��״̬,�㷨�ܹ�����һ�������ij���expected return�����expected return Ҳ����Q-value��Q-valueԽ��,��ζ�Ŷ��� A t A_{t} At?��״̬ S t S_{t} St?�ϲ������õij��ڽ����
�ڷ���ִ��������,Q-learning���״̬��ʾ����ִ�е�����䡣������ʾ����ִ����������֧���ʱ,ѡ��true��֧����false��֧����������е��ؼ���ʱ,����ֵΪ���ġ�
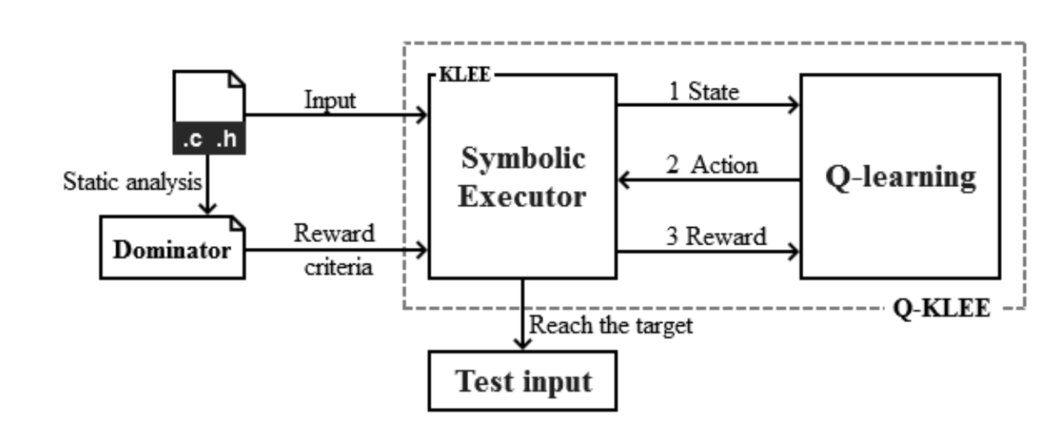
����ʵ����,������Դ�����趨Ŀ�����,�����þ�̬������ȡ·���ϵĹؼ��㡣Ȼ��,������ִ��������֧���ʱ,�Ὣ��ǰ״̬����Ϣ����Q-learning,���һ�ȡ��action�Ľ���(true or false)������ �� ? g r e e d y \varepsilon-greedy ��?greedy����,klee�� �� \varepsilon ���ĸ���ѡ��Q����ֵ,Ҳ�� 1 ? �� 1-\varepsilon 1?���ĸ������ѡ��һ��action��Ȼ����ÿ����֧������,�ٷ��ظ�Q-learning reward,������Q����ֻ�г������е��ؼ����ʱ��,reward��Ϊ����,���������Ϊ���ġ�
���������ֹ��,����û�е���Ŀ�����,����ͻ�����ִ�С����������,klee�ᷢ��fail�źŸ�Q-learning,Q-learning��ѡ��һ���µ�ִ��״̬��KLEE��ѡ����Ҫ������������:
- �оٳ��ϸ�ִ�й��������п��ܵĺ�ѡ״̬
- ����ÿ����ѡ״̬�ĸ���
- ѡ�������ʵ���Ϊ�µ�״̬
�ٸ�����,�����ڵ�һ��ִ�й�����û�е���Ŀ�����ֹ��,���ķ�֧ѡ��������101(true false true),����ÿ��fork������������״̬,���Ժ�ѡ״̬��(0,11,100)��ǰ״̬�ĸ���������ǰ��״̬�ĵ��۳˵õ��ġ�����:
P ( 100 ) = P ( 1 ) ? P ( 1 �O 0 ) ? P ( 10 �O 0 ) P(100) = P(1) * P(1|0) * P(10|0) P(100)=P(1)?P(1�O0)?P(10�O0)
һֱ�����������,ֱ������Ŀ���,���߳�ʱ��
����
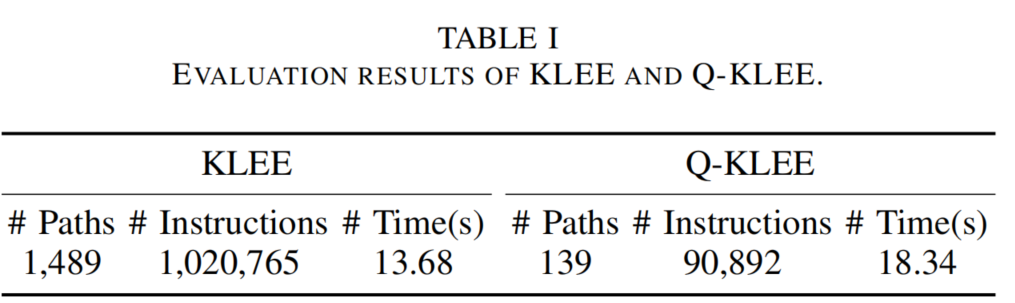
��sv-benchmark�ϲ�����60������,�����ɸѡ·����ȷʵ�ǹ����˺ܶ�·�������ǻ��ѵ�ʱ��Ҳ���ࡣ��Ϊ��Ҫ����Q-learning��valueֵ��