��Ϊpython��Ч�칫
???????ʲô�и�Ч�칫?????�Ǿ��Ǹ�Ч��!!!���������ʱ���������Ч�칫��ô��???????????�����Ч�칫:
??????????????���������
??????????????������ְ��н
??????????????�����˫�������(����)
???????���ǽ����ҿ�ʼ���Ŵ��һ��ѧϰ���ͨ��Python�������Ը�Ч�칫,���ڱ���֪ʶҲ����,���кõĽ������������ط���ӭ����!!!)
������ʾ,������û�л���,զ�ǾͰ��ո�ʽ,˼·���ͺ�,����İٶ�һ�¾ͺ���!
ע:�д���ĵط�һ��Ҫ�ô�,���ڻ���,��û�������Ҫ��Ҫ����!!!��Ȼ��,���ӻ���,�ֲ���,������������
ǰ��
�ϻ�����˵,����֪����Ч�칫������������ǡ�>Excel��Email��Word
���ǽ�ͨ��python�������ɵ���������!���˫��!!!ӭȢ����
ע��:�ڶ�������ҪΪ����Ϥ��һ����֪ʶ������������,�������,�ۺ����Ͳ�����!��������ۺ���ϰ!���ĺܻ���,��֤����ѧ��!!!
Python��Ч�칫
һ��openpyxl����excel-Part1(���Ҽ��ɴ�Խ����һ����!!!)
����openpyxl����excel-Part2
2.1������������
2.1.1����һ:��ȡ���˹�����Ϣ
����Ҫ��:
��11�µ�Ա����Ч�����ҵ�Ư������1��н����Ϣ,Ȼ������Ҫ���ⲿ����Ϣд�뵽Ư�����õĹ�����Ϣ����!��,����ô��
˼·:
1??what? ????????�ҵ���11��Ա����Ч��������plmm1������Ϣ����
2??where? -->���鿴������ݡ�,��11��Ա����Ч����,�ҵ�Ư������1��н����Ϣ��
???????????????????????�������鿴������ݡ�,��plmm1������Ϣ����,�ҵ���д�����ݵĵ�Ԫ��
3??run!!! ?????????�رչ�����,���д���,��plmm1������Ϣ����,�鿴д���Ч��
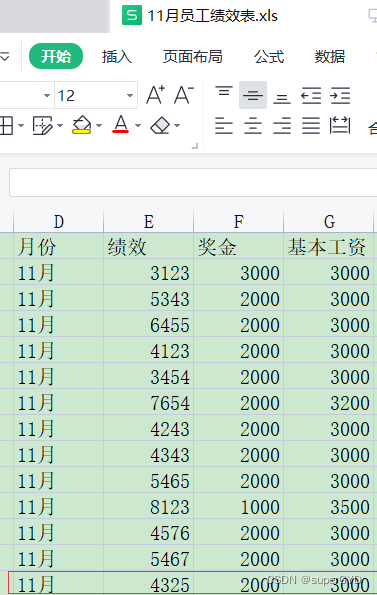
plmm1�Ĺ�����Ϣ���л�û����,��Ҫ���ܱ�������д������ſ���!��Ȼplmm1��ûǮ��Ŷ!
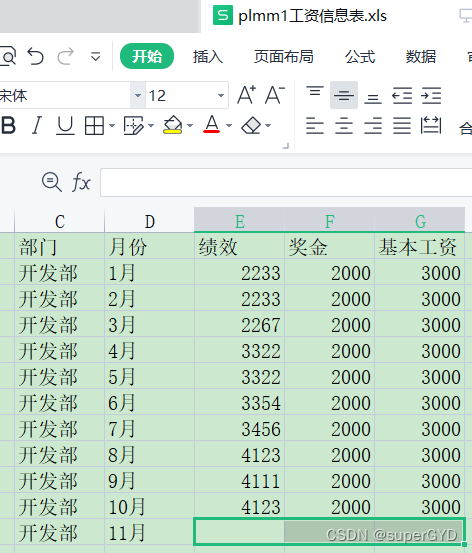
˼·����,�����д����??�ܼ�!
�����:
# ��openpyxl���load_workbook����
from openpyxl import load_workbook
# ��11��Ա����Ч�����Ĺ�����,��ȡ�������
performance_wb = load_workbook('./11��Ա����Ч��.xlsx')
performance_ws = performance_wb.active
# ��plmm1������Ϣ�����Ĺ�����,��ȡ�������
info_wb = load_workbook('./plmm1������Ϣ��.xlsx')
info_ws = info_wb.active
# ��ȡ����Ч��ֵ
performance = performance_ws['D14'].value
# ��ȡ������ֵ
bonus = performance_ws['E14'].value
# ��ȡ���������ʡ�ֵ
base = performance_ws['F14'].value
# д�롾��Ч��ֵ
info_ws['E12'].value = performance
# д�롾����ֵ
info_ws['F12'].value = bonus
# д�롾�������ʡ�ֵ
info_ws['G12'].value = base
# ����ԡ�plmm1������Ϣ������������д��
info_wb.save('./plmm1������Ϣ��.xlsx')
�������к�:
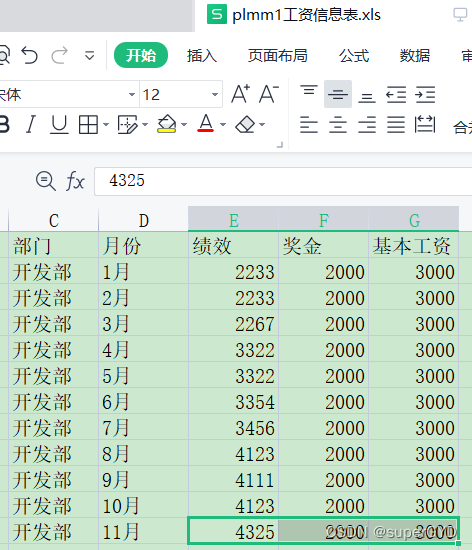
�ܽ�һ�°���һ:��ȡ��Ԫ�������,ԭ��д���������еĹ�����,���ڡ���Ԫ���д��ģʽ��
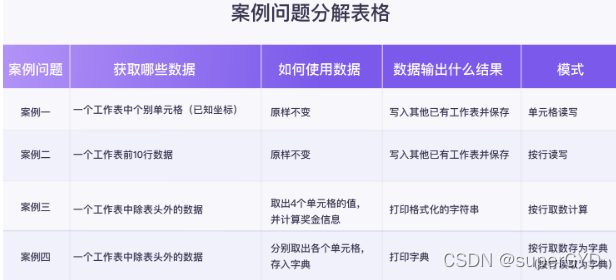
2.1.2������:����ǰʮ�м�Ч��Ϣ��
����Ҫ��:
��11�µ�Ա����Ч����ǰ11��������ȡ��д����һ���ļ���,��,����ô��(�밸��һ�������һ���ǶԵ�Ԫ�����,���ǶԶ��н��в���)
˼·:
1??what? ????????�ҵ���11��Ա����Ч����
2??where? -->���鿴������ݡ�,��11��Ա����Ч����,��ȡǰ11����Ϣ��
???????????????????????�½�������,����ȡ����Ϣд�뼴��
3??run!!! ?????????�رչ�����,���д���,���½��Ĺ�����,�鿴д���Ч��
�����:
# ��openpyxl���load_workbook��Workbook
from openpyxl import load_workbook, Workbook
# ��11��Ա����Ч��.xlsx��������
performance_wb = load_workbook('./11��Ա����Ч��.xlsx')
# ��ȡ�������
performance_ws = performance_wb.active
# �½�������
new_wb = Workbook()
# ��ȡ�������
new_ws = new_wb.active
# ��ȡperformance_ws��ǰʮһ������
for row in performance_ws.iter_rows(max_row=11, values_only=True):
# ������д���µĹ�����
new_ws.append(row)
# �����¹�����Ϊ��Ա����Ч��-ģ��.xlsx��
new_wb.save('Ա����Ч��-ģ��.xlsx')
????????�ܽ������ʵ���ǼĶ��ж�ȡ��д��,�Ȼ�ȡǰʮһ�е�����,�ٰ��в���,ÿ��ԭ��ʹ��,���д�뵽�½��Ĺ������С��ؼ����ڶԱ�����ķ���ʹ��,�Լ�ע��ϸ��(�����)
???????����һ�Ͱ�����,���IJ�ͬ������ȡ�����ݲ�һ��������һ��ȡ����������Ԫ�������,����������ȡ��ǰʮ�е����ݷ�Χ��
???????ͬʱ��,Ҳ��������ͬ��,����ԭ��ʹ������,��������Ľ������д�������������С�Ҳ����˵����ȡ���ݨC>���ʹ�����ݨC>���ʲô������Ļ����ṹ��,�����衱�Ÿ��Բ�ͬ�ġ���ʽ����
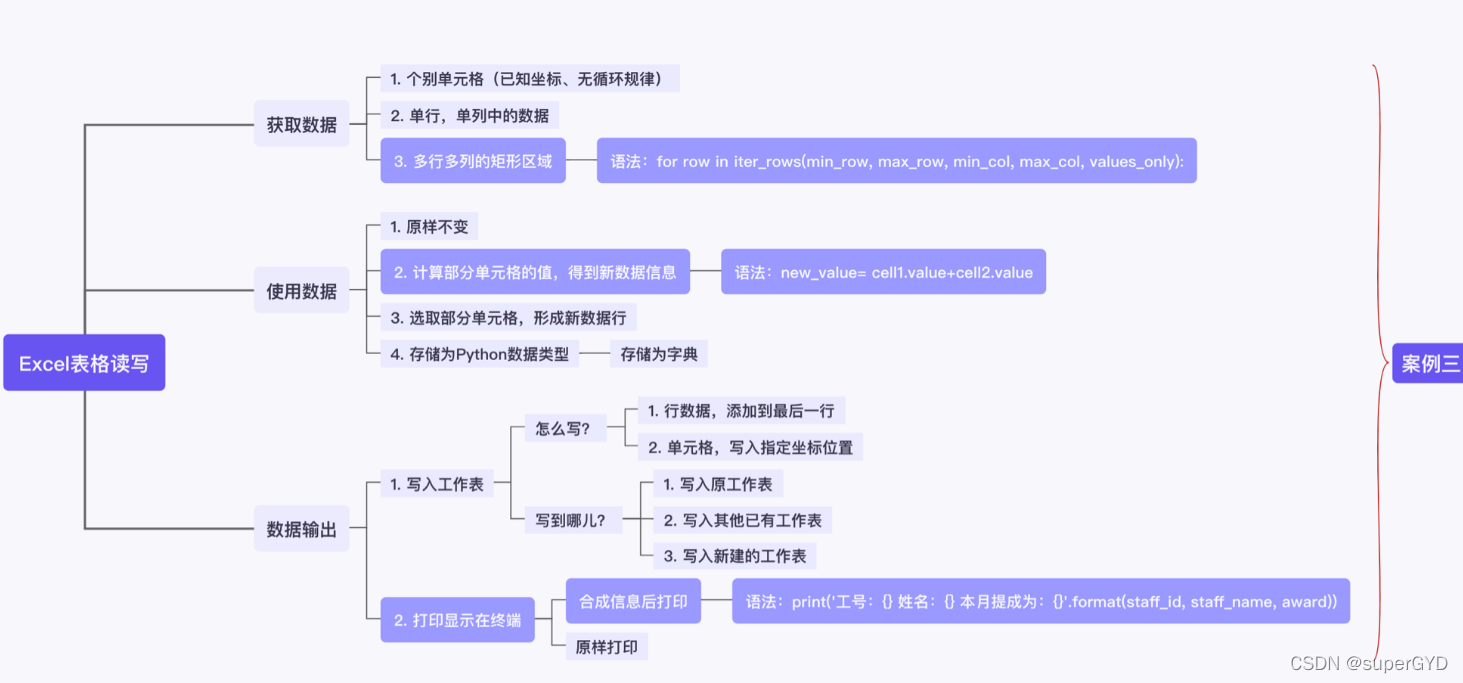
2.1.3Excel�ļ���д������ֽ�
????????���ǿ��Ը��ݡ���Ҫ��ȡ��Щ���ݷ�Χ��,�����ʹ�����ݡ�,��������������IJ��������������Excel�ļ���д�ࡱ�����⡣
????????����������������ġ��𰸡������ж��ֱ���,�Ӷ���������ͬ�Ĺ���Ч��,�����ͬ��ʵ������
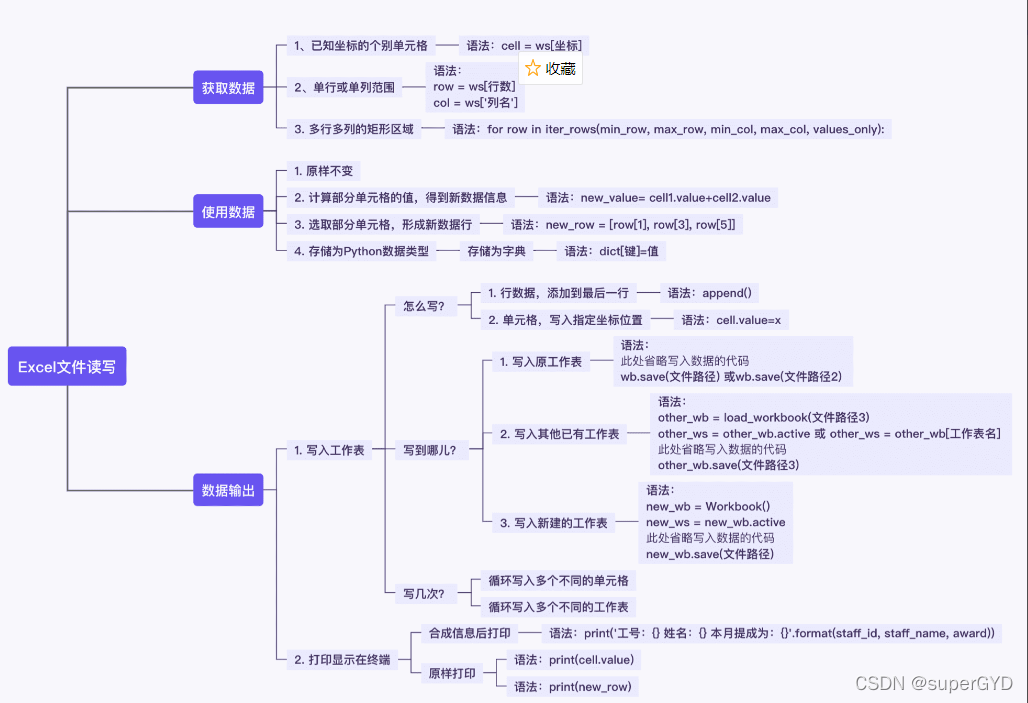
1. ��ȡ��Щ���ݷ�Χ
????????������Excel������Ļ�,��϶�֪��,��ʹ�Ƕ���ͬһ��������,ͬһ��������,������Ҫ��ȡ�����ݾͿ���ǧ�����
????????���硾10��н�ʼ�Ч����,������Ҫ����ĸ�������,Ҳ������Ҫǰʮ��������Ϊģ��,��������Ҫ����Ա�������ݽ��л��ܵȵȡ�
����Ҫ��ȡʲô���ݷ�Χ�ڵĵ�Ԫ��������,���¿��Է�Ϊ����:
1����֪����ĸ���Ԫ��
2�����л��з�Χ�ڵĵ�Ԫ��
3�����ж�����ɵľ��η�Χ�ڵĵ�Ԫ��
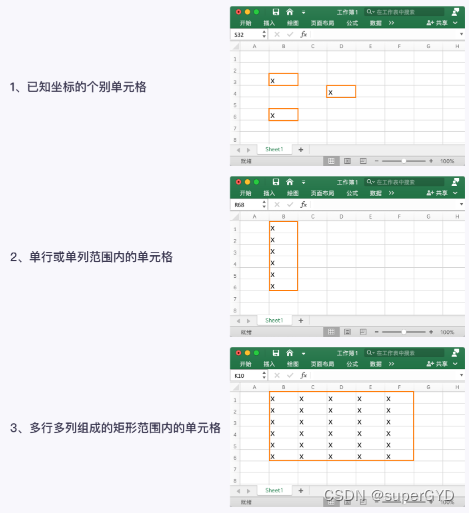
�����ַ�Χ�ڵĵ�Ԫ��,��ȡ����ɲ���ͬ

????????���Ե�����Excel�ļ���д����,��������ȷ��,��Ҫ�����������������ļ������������ļ�������������Щ���ݷ�Χ�ĵ�Ԫ��
????????ȷ�Ϻ��������,���ǾͿ���ѡ���Ӧ���,ȥ��ȡ��������

2. ���ʹ������
????????ȡ�����ݺ�,�Ϳ���ʹ�������ˡ�
????????��Ȼ��������������ʹ�����ݡ��ķ�ʽ�Ƚϼ�,���������˵��������һЩ������ʽ,��Ҳһ���ܹ����⡣�Ͼ����Ǿ�Դ���ճ���Excelʹ�á�
????????��ô����ԭ����д������,���ǻ����Դ��������г�ȡ����,���м���(��ѧ���㡢�ַ���ƴ�ӵ�),����ͨ������ɡ��롰��Ч��֮��,�õ��������н���Ľ�
????????����,�����Գ�ȡ����,�γ��µ�������,�����ȡ��ÿ�е�1�������1����Ԫ�������,�õ�һ���µ����ݡ�
????????��Ȼ�����Խ���õ�����,�洢ΪPython�е���������,�Ա����ʹ�á������ÿ�����ݴ�Ϊ�ֵ����͵ȵȡ�

3. ���������
????????���ݴ�����ʹ�ú�,�϶������һ�������ݽ������ôʹ��������,һ���õ�ʲô���µ����ݽ����?
????????ǰ�����ǿ�������Ҫ��д�뵽����������,����µĹ��������ݡ���ʵ��д�뵽�����������ַ�ʽ��Ҳ���в���ϸ��:
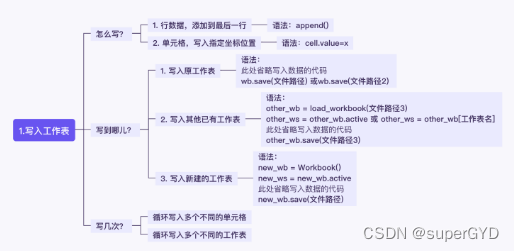
????????�������Ѿ�֪����,����һ�Ͱ������еġ�д�뵥Ԫ�����ݡ���д�������ݡ���
�����ԡ�ָ��������һ��д��,��ָ����д����������λ�õ�;������д����ͬ�Ĺ�����������,����ԭ���������������й������������½��������Ĺ������ȡ�
����,������ϡ�ѭ����,������ͬʱд�������ͬ�Ĺ�������,���߶����ͬ������λ���ϡ�
????????�ǻ���ỹ��������������?�����Խ������������ֱ�����,��ӡ���նˡ�

�������,���ǿ��Խ�����ֽ⻮��Ϊ��������:��ȡ����,ʹ������,�������,�����������̺��Ų�ͬ�ľ�����֡�
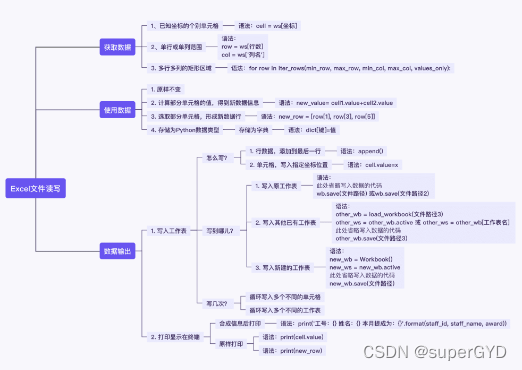
????????����һ����,��ȡ�������ǵ�����Ԫ��;Ȼ����ȡ����ԭ��д�뵽����ı������ڵ��͵ĵ�Ԫ���дģʽ��
????????����������,��ȡ�������Ǿ��������,һ��Ҫ����ȡ��;Ȼ����ȡ����ԭ��д�뵽����ı����С����ڵ��͵İ��ж�дģʽ

2.1.4������:���㲢��ӡ������Ϣ
����Ҫ��:
????????��Ȼ�Ǵӡ�11��Ա����Ч������ȡ����Ա���Ĺ�����Ϣ,Ȼ�����ÿ����Ա���ġ���Ч���롰��ɡ�����ֵ֮��,����������ܶ�,����չ̶���ʽ���ÿλԱ���Ľ�����Ϣ��
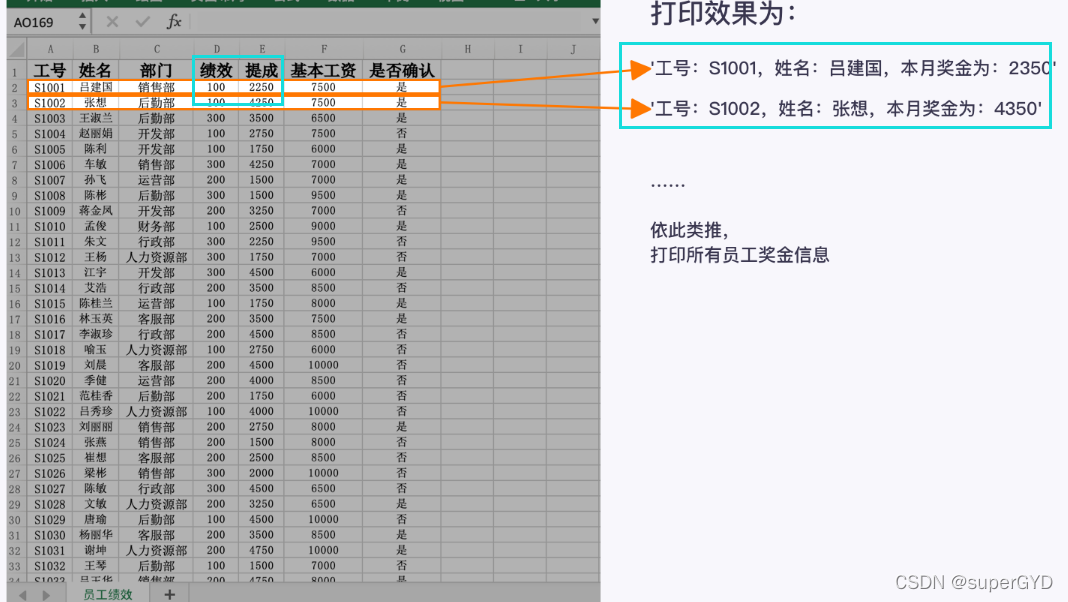
˼·:
���������Ҫ��,���ǿ��Խ������Ϊ������ʵ��:
1)ȡ������Ա����Ϣ�����ݷ�Χ:��11��Ա����Ч����������,ȡ�����ݷ�Χ��
2)��ȡ�������������:��ȡ������Ч���͡���ɡ�,��������������ݡ�
3)ƴ�Ӳ���ӡ:ƴ��Ա���������š�����,��ӡ���̶���ʽ����Ϣ��
�����:
# ��openpyxl���load_workbook��Workbook
from openpyxl import load_workbook, Workbook
# ��11��Ա����Ч��.xlsx��������
performance_wb = load_workbook('./11��Ա����Ч��.xlsx')
# ��ȡ�������
performance_ws = performance_wb.active
# ��ȡperformance_ws�г���ͷ�������
for row in performance_ws.iter_rows(min_row=2, values_only=True):
# ��ȡ�����š�
staff_id = row[0]
# ��ȡ��Ա��������
staff_name = row[1]
# ��ȡ����Ч��
performance = row[3]
# ��ȡ����ɡ�
bonus = row[4]
# ���㡰����
award = performance + bonus
# ��ӡ���
print('����:{},����:{},���½���Ϊ:{}'.format(staff_id, staff_name, award))
Сϸ��:
ʹ��iter_rows()ʱ,Ҫע��values_only����,�����ֵ��ͬ,�����ȡ��Ԫ��Ĵ���ͻͬ
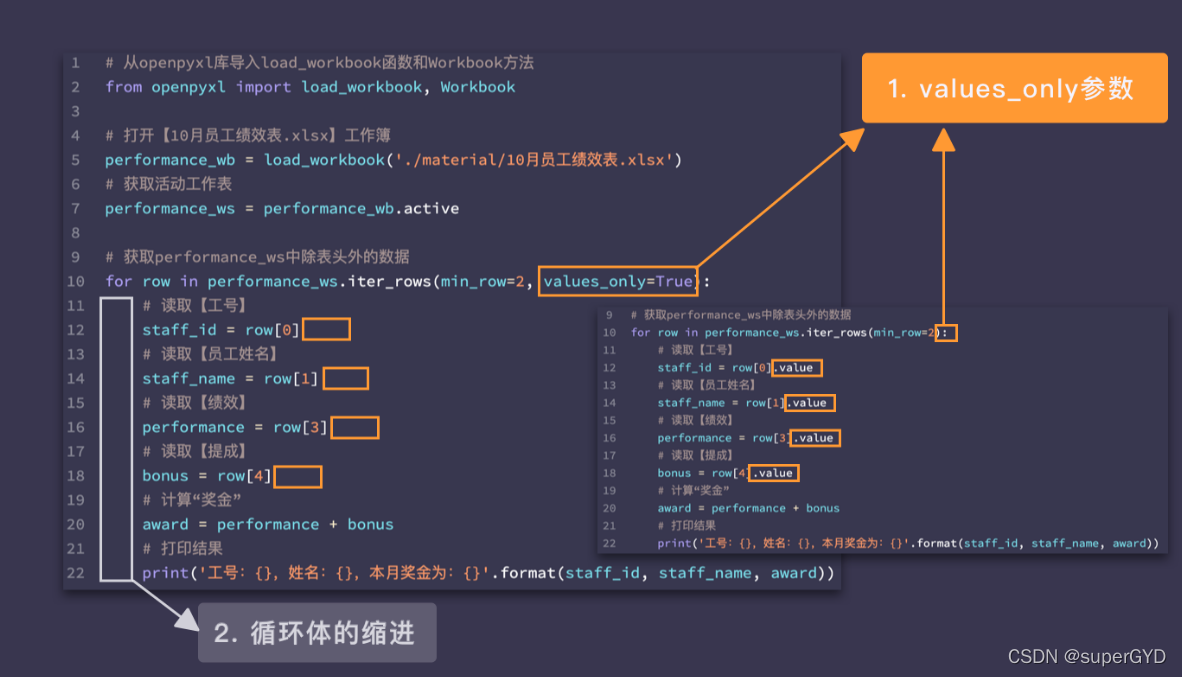
��Ҫע������!
2.1.4������:����н����Ϣ�ֵ�
����Ҫ��:
????????��Ȼ�ǡ�11��н�ʼ�Ч����,Ҫ������ܵ�н�ʱ���,��ȡ�������ݷ�Χ��������,Ȼ��ȡ��������Ϣ,�����Ӧ�洢���ֵ��С�
˼·:
????????������������,��11��н�ʼ�Ч�����е�Ա����Ϣ�Ƚ϶�,���Ҫ�ҵ�ijλͬ��(�����ҵ�Ư������1�ļ�Ч���������ʵ�)�ð�����������һ��
????????�����Python�Ļ�,��û������Excel�����еIJ��ҹ���,�ܸ����������߹��ŵ��д����ԵĹؼ���,�ҵ���������ڵ���,�õ����е���Ϣ��?
????????���ǵ�Python�е��ֵ�������?�ֵ�Ԫ��Ϊ��ֵ��,����Ψһ�ļ�,�����ҵ���Ӧ��ֵ
����,���ǿ������Թ���Ϊ��,��ÿλԱ������������Ϊֵ��,�洢��һ����н����Ϣ�ֵ䡱��
���������á�Ա���Ĺ��š��롰��Ա���ĸ���н����Ϣ���γ�ӳ���ϵ,�ҵ����ž��ܶ�Ӧ������Ա����Ϣ�����������ֵ���ȡ����ֵ�ķ�ʽ,Ҳ���Ժܷ���ؽ������ݲ�ѯ��
�����:
# ��openpyxl���load_workbook����
from openpyxl import load_workbook
# ��11��Ա����Ч��.xlsx��������
performance_wb = load_workbook('./11��Ա����Ч��.xlsx')
# ��ȡ�������
performance_ws = performance_wb.active
# ����Ա����Ϣ�ֵ�
staff_info = {}
# �ӵڶ��п�ʼ��ȡ�������е���Ϣ
for row in performance_ws.iter_rows(min_row=2, values_only=True):
# ȡ������
member_number = row[0]
# ����Ϣ����Ա����Ϣ�ֵ�
staff_info[member_number] = {
'����': row[1],
'����': row[2],
'��Ч': row[3],
'����': row[4],
'��������': row[5],
'�Ƿ�ȷ��': row[6]
}
print(staff_info)
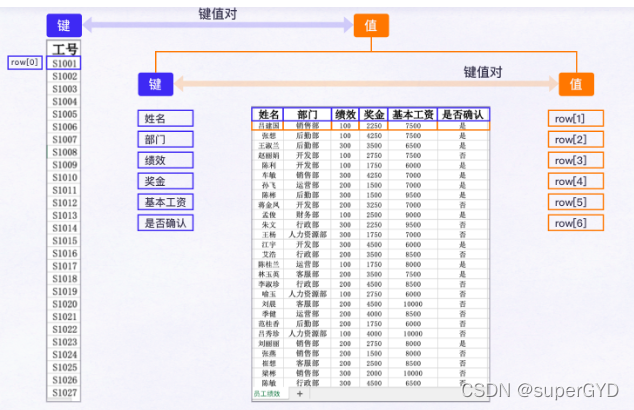
��ʵ,��ʱ���γ���,���ֵ��ֵ��Ҳ����һ���ֵ�����,Ҳ�����ֵ�Ƕ��
���˰�ÿ��Ա������Ϣ��Ϊ�ֵ�,���ǻ�����ÿ��Ա������Ϣ�����洢ΪԪ������,������ͼ:
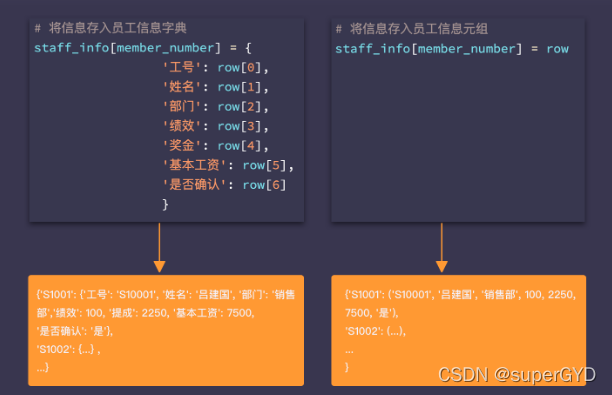
???????��ΪԪ���,Ҳ���Ը����������Ҷ�Ӧ����Ϣ,����ͨ��staff_info[member_number][1]�õ�Ա������
???????������,����ܻ�ѽ�,Ϊʲô��ʹ������ʱҪ����洢Ϊ�ֵ�,������Ϊ�˴�ӡ�����?
???????��ʵ��Ȼ,���ǵñ�����������������?������Ҫ���ݹ���,�ҵ���Ա����Ӧ����Ϣ��
???????�Ҹ��ݵõ����ֵ�,д��һ���Ը��ӵij������������һ�¡���ѯԱ����Ϣ�ֵ䡱�ĺ���֮����
# ����н����Ϣ�ֵ�(��ǰ8������Ϊ��)
staff_info = {
'S1001': {'����': 'Ư������1', '����': '���۲�', '��Ч': 100, '���': 2250, '��������': 7500, '�Ƿ�ȷ��': '��'},
'S1002': {'����': 'Ư������2', '����': '���ڲ�', '��Ч': 100, '���': 4250, '��������': 7500, '�Ƿ�ȷ��': '��'},
'S1003': {'����': 'Ư������3', '����': '���ڲ�', '��Ч': 300, '���': 3500, '��������': 6500, '�Ƿ�ȷ��': '��'},
'S1004': {'����': 'Ư������4', '����': '������', '��Ч': 100, '���': 2750, '��������': 7500, '�Ƿ�ȷ��': '��'},
'S1005': {'����': 'Ư������5', '����': '������', '��Ч': 100, '���': 1750, '��������': 6000, '�Ƿ�ȷ��': '��'},
'S1006': {'����': 'Ư������6', '����': '���۲�', '��Ч': 300, '���': 4250, '��������': 7000, '�Ƿ�ȷ��': '��'},
'S1007': {'����': 'Ư������7', '����': '��Ӫ��', '��Ч': 200, '���': 1500, '��������': 7000, '�Ƿ�ȷ��': '��'},
'S1008': {'����': 'Ư������8', '����': '���ڲ�', '��Ч': 300, '���': 1500, '��������': 9500, '�Ƿ�ȷ��': '��'}
}
# ���������ѯ��Ա���Ĺ���
staff_id = input('�����������ѯԱ���Ĺ���(��:S1001):')
# ���ݹ���(��)�ҵ�Ա����Ϣ(ֵ)
dict_staff = staff_info.get(staff_id)
# �жϸ�Ա���Ƿ����
if dict_staff:
# ��������Ҫ��ѯ��Ա����Ϣ
search_info = input('����������ѯ����Ϣ(��:����/����/��Ч/���/�Ƿ�ȷ��):')
# �жϸ�Ա����Ϣ�Ƿ����
if dict_staff.get(search_info):
print('����ѯ,��Ա��' + search_info + 'Ϊ:')
print(dict_staff[search_info])
# �˱�ͷʱ,����ѯ
else:
print('������Ϣ���ʹ���,ֻ�ܲ�ѯ���������š���Ч����ɡ��Ƿ�ȷ��')
# �˹���ʱ,����ѯ
else:
print('���乤�Ŵ���')
����Ը�����Щ����ȥ����,��֪���ֵ��ʽ�ж��ʹ����,ǰ��������Ҫѧ��ӱ�����ȡ�ؼ���Ϣ!
???????����,�������ж��������Ҫ���жԱ�ɸѡ���߷���ʱ,�����ݴ�Ϊ�ֵ�Ҳ�Dz�����ѡ��
��Ϊ,���Ѷ����������ͬ������,���硾11��н�ʼ�Ч�����͡�10��н�ʼ�Ч�����еĹ���,������Ϊ�����š�,������Եı�����Ϣ��,�ٽ��жԱȻ����
�������ܽ�:
����!����!
�������Ӿ���!
????????????????????????????????????????����!!!!����������
������ϵ��ʽ:
QQ:747498947
wx:SuperMan-Gyd