Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。?
Scrapy入门请看官方文档:scrapy官方文档
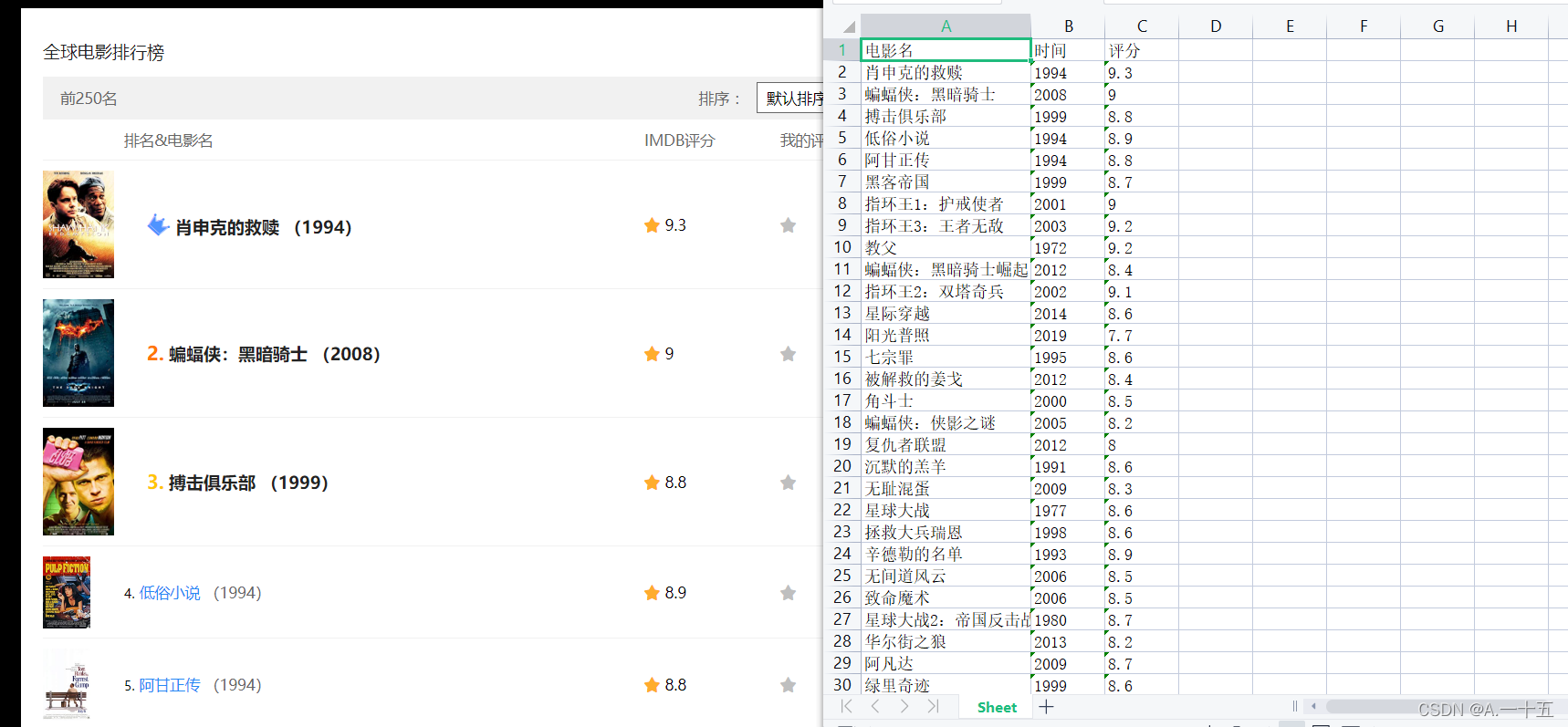
本爬虫爬取的是电影排名与放映时间和评分 成果图如下:
整体思路
1、新建项目和爬虫文件?2、编写test1文件和main.py代码 3、修改middlewares.py/编写piplines.py 4、修改settings,items文件代码 5、启动
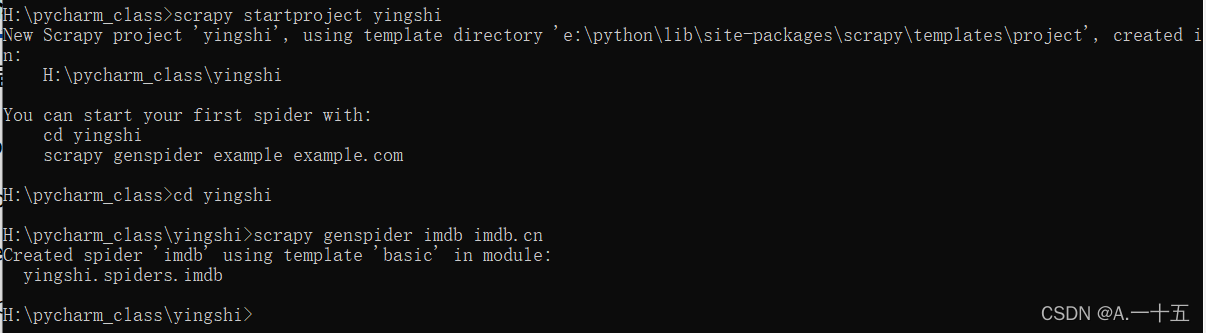
1.新建项目和爬虫文件
?
?2.编写imdb.py文件
注意理解注释。
from yingshi.items import YingshiItem
import scrapy
import time
class ImdbSpider(scrapy.Spider):
name = 'imdb'
allowed_domains = ['imdb.cn']
start_urls = ['https://www.imdb.cn/imdb250/']
offset=0
def parse(self, response):
items=YingshiItem()
lists=response.xpath('//tbody[@class="rl_lister-list"]/tr')#获取想要爬的地方的xpath
print('获取的lists:',lists)
for i in lists:
items['mingzi'] = i.xpath('./td/a/@title').get()#使用get方法获取电影名字的xpath
print('电影名:',items['mingzi'])
items['shijian']=i.xpath('./td/a/span/text()')[0].extract()#获取电影时间的xpath
items['shijian']=items['shijian'][1:5]#获取括号中的时间
print('时间:',items['shijian'])
items['fen']=i.xpath('./td[@class="rl_grade_IMDB"]/span/text()')[0].extract() #获取评分的xpath
print('评分:',items['fen'])
time.sleep(0.5)#停顿
yield itemsmain.py文件
from scrapy.cmdline import execute
execute("scrapy crawl imdb".split())3.修改middlewares.py
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
from scrapy.http import HtmlResponse
class YingshiSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class YingshiDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
bro = spider.bro
bro.get(request.url)
page=bro.page_source
n_response = HtmlResponse(url=request.url,body=page,encoding='utf-8',request=request)
return n_response
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
?编写piplines.py文件
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
from openpyxl import Workbook
class YingshiPipeline:
def __init__(self):
self.wb = Workbook()
self.ws = self.wb.active
self.ws.append(['电影名', '时间', '评分'])
def process_item(self, items, spider):
line = [items['mingzi'], items['shijian'], items['fen']]
self.ws.append(line)
self.wb.save('./电影排名.xls')
return items4.修改settings.py文件
# Scrapy settings for yingshi project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'yingshi'
SPIDER_MODULES = ['yingshi.spiders']
NEWSPIDER_MODULE = 'yingshi.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'yingshi (+http://www.yourdomain.com)'
User_Agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False#或True
LOG_LEVEL='ERROR'#输出日志设为输出发生错误的日志
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'yingshi.middlewares.YingshiSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'yingshi.middlewares.YingshiDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'yingshi.pipelines.YingshiPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
修改items文件代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class YingshiItem(scrapy.Item):
# define the fields for your item here like:
mingzi = scrapy.Field()#电影名字
shijian = scrapy.Field()#放映时间
fen = scrapy.Field()#评分
pass
5运行main.py文件
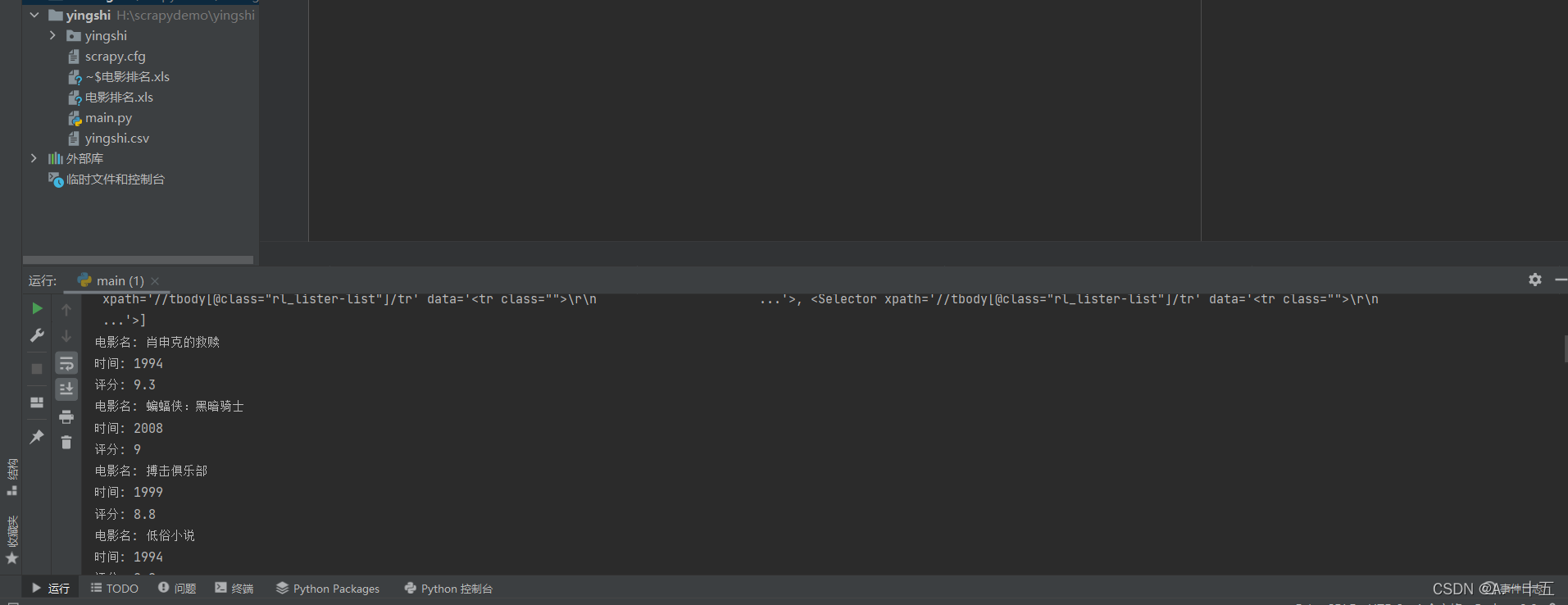
?以上就是爬取imdb网的电影排名,感谢观看。
别忘了一键三连呼。