这一期内容主要是11月份的学习总结
一点点python
1
绘制柱形图的经典语句
fig = plt.figure(figsize=(20, 8))
plt.bar(x=names, height=nums)
for x, y in zip(names, nums):
plt.text(x, y+0.3, '%.0f'%y, ha='center', va='bottom', fontsize=10.5)
# plt.show()
plt.savefig(os.path.join(path_fig, f'{folder_name}_info.png'))
print(sum(nums))
其中的 for 循环较难,主要是在柱形图上方添加文字。
需要注意的是,plt.show() 和 plt.savefig() 不能同时使用
(题外话,以前经常分不清 fig.show() 和 plt.show() ,后来使用 fig.show() 翻过车才开始用plt.show() ,可能 fig.show() 不太稳定,以后默认使用plt.show() 好了)
2
使用random.shuffle重排数据顺序
https://www.runoob.com/python/func-number-shuffle.html
3
使用torch.where实现矩阵中特定元素的筛查
https://zhuanlan.zhihu.com/p/333864883
4
远程修改代码需要注意正确路径,不然是白改
/home/xxxx/anaconda3/envs/xxxxx/lib/python3.8/site-packages/xxxxxxxxx-0.0.0-py3.8.egg/xxxx/zzzzzzz.py
5
interpreter的设置一定要找到conda环境里的python.exe,即使创建环境时使用的是python3.8
win系统下是envs/env_name/python.exe
linux系统下是envs/env_name/bin/python.exe
只要找对了环境里的python程序,就可以调用该环境里所有的包!
6
使用__all__变量可以限制import *导入变量的范围
https://blog.csdn.net/woai8339/article/details/88623962
7
关于pytest的,很全面
https://www.cnblogs.com/sparkling-ly/p/5650413.html
8
pytest无法识别当前目录中的文件的报错
py.test: error: unrecognized arguments: --cov --cov-report term-missing besel_func_test.py
解决方法:
pip install pytest-cov
https://blog.csdn.net/zzq900503/article/details/84785598
9
pytest触发机制:1. 文件名有_test或者test_,在cmd里输py.test或者pytest可以运行所有文件并生成报告。 2. import pytest 通过pytest.assert调用。3. 如果文件名有_test或者test_, 编辑页面中右键即可出现pytest执行的字样
10
一句话建一个python包!
https://saltyball.top/2021/03/27/%E5%86%99%E4%B8%AApython%E5%8C%85-pyscaffold%E7%9A%84%E4%BD%BF%E7%94%A8/#more
安装pyscaffold
当前目录下,输入putup your_package_name
即可建立一个名为our_package_name!!!!!!
一句话一个包!太方便了!!!伙计们用起来!!!!!!!
11
一个简简单单的python终端退出查了n次了,这次不能再忘了
win平台 ctrl + z 再回车
linux Ctrl + D
https://jingyan.baidu.com/article/90bc8fc8a3fe5bf652640c63.html
12
从开源仓库扒下源码以后,cmd进入setup.py所在界面,使用命令
pip install -e .
安装代码库
是修订模式,conda 环境目录下只有一个egg的link,没有代码备份
所以修改源码的时候,在pull下来的目录里修改就好了
改完用git直接push到远程仓库,无需二次修改
python setup.py develop也行,但是有时候不容易通过pip卸载
不需要改源码的话,可以用
pip install .
或者
python setup.py install也行,但是有时候不容易通过pip卸载
当然,pip也有缺陷,它不能检查安装包的版本兼容性,容易造成冲突,使“老包”不能再使用
13
pytorch训练的时候,如何平衡num_worker和batch_size的问题
简单说,CPU负责准备训练数据,GPU负责计算数据,二者是“生产消费”模型
num_worker决定了CPU调用几个线程准备数据,这个一般不会是计算瓶颈,一般很快
最重要的是batch_size,这个指标决定了GPU的显存占用情况,跟训练时间和精度有直接关系。
batch_size调大了,训练时间会大幅下降,GPU显存可能会顶满,所谓“榨干GPU”,但是这样做可能会带来少量的精度损失。
14
一句话写一个if else语句
注意,不能有冒号
读起来有点绕

15
tsv是一种机器学习数据存储格式,全称 tab separated values,制表符分隔值
与其类似的,常见的,另一种格式是 CSV,全称 comma separated values;即“逗号分隔值”,
使用python读取时只需要填写正确的分隔符
如果是CSV的话,可以不用填…因为方法的名字就是read_csv
pd.read_csv("./tmp/chipotle.tsv", encoding="gbk", sep="\t")
链接:
https://blog.csdn.net/IT_SoftEngineer/article/details/107325062
https://blog.csdn.net/colourful_sky/article/details/79519597
16
ase 查看数据库的几条命令:
ase db bulk.db 命令行查看
ase db abc.db -w web查看(页面友好)
ase db bulk.db --insert-into bulk.json 数据库导入json文件
ase gui bulk.db 使用ase自带的gui查看
链接↓
https://databases.fysik.dtu.dk/ase/tutorials/db/db.html
还有 ase.io.read 也可以读取数据库。比如说:a = read(‘abc.db@42’)
17
npz文件的写入和读取
https://blog.csdn.net/weixin_35757704/article/details/118175632
下面链接中提到,可以用data.files的方式查看npz文件里的标签
https://blog.csdn.net/AugustMe/article/details/88095362
下面链接是官方文档:
https://numpy.org/doc/stable/reference/generated/numpy.savez.html
https://numpy.org/doc/stable/reference/generated/numpy.load.html
18
使用ase的atom对象写入数据库,如果没有设置calculator,数据库里就不会出现calculator的关键字,也不会出现force和energy。设置calculator以后还需要atoms.get_forces(),calculator会计算每个原子受力及其能量,并将其置于atoms对象里。
19
conda销毁某个环境的时候使用命令:
conda remove -n envname --all
创建新环境的时候使用命令:
conda create -n envname python=3.8
最后一定要加上python=3.8,其他版本也可以,看需求了。加这一句话的目的是下一步安装包的时候可以直接用命令pip,而且不用再下载python。不加这句话就没有python,里面是空的。加了以后会有一些基本的文件。
20
gpu上跑完的模型放到cpu上跑,fine_tuning,需要在state_dict里面改一下map_location的值
state_dict = torch.load(ckpt_path, map_location=‘cpu’)
https://blog.csdn.net/qq_19592705/article/details/109119149
21
RuntimeError: a leaf Variable that requires grad is being used in an in-place operation.
在报错代码前面加一个缩进 with torch.no_grad():
22
pytorch stack函数
https://zhuanlan.zhihu.com/p/365414757
23
在一张大矩阵里,不同索引对应值的相减,可以用索引序列代替(不用整for循环,大矩阵可以一次性take多个索引)
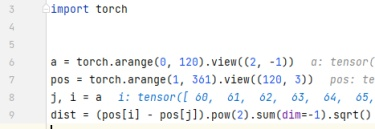
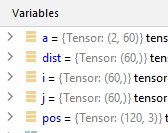
24
https://www.cnblogs.com/haifwu/p/12814760.html
使用repeat_interleave对张量进行复制,复制倍数由repeats决定,复制哪个维度由dim决定
25
from torch_sparse import SparseTensor
adj_t = SparseTensor(row=i, col=j, value=value, sparse_sizes=(num_nodes, num_nodes))
稀疏矩阵的 i 行和 j 列对应位置的值是value,这个很容易理解,但是后面sparse_sizes不太好理解
我认为是规定了“如果稀疏矩阵映射到dense矩阵,该矩阵的大小”
该矩阵可以比原稀疏矩阵大,多出来行列置零
26
超详细torch_scatter.scatter()的解释
https://blog.csdn.net/lifeplayer_/article/details/111561685
https://zhuanlan.zhihu.com/p/350953046
https://www.cnblogs.com/dogecheng/p/11938009.html
27
numpy.cross 和 torch.cross 可以用来求叉乘,求法向量
官方文档:
https://pytorch.org/docs/stable/generated/torch.cross.html
https://numpy.org/doc/stable/reference/generated/numpy.cross.html
28
https://pytorch.org/docs/stable/generated/torch.numel.html
torch.numel 输入一个tensor,返回该tensor里面的元素的个数
这个函数只有torch有,numpy没有
同样的 repeat_interleave 也是只有torch有
29
indices, offsets = neighborList.get_neighbors(0)
非周期性体系不能用 ase 的 get_neighbors 得到邻居原子的偏移量
因为非周期性体系没有晶格常数
30
定义函数的时候,有默认值的参数应该在最后面(无默认值的函数)
不然会报错:non-default parameter follows default parameter

杂
1
科研途中看到贝塞尔函数头皮发麻吗?不用担心,不用着急。
贝塞尔函数说白了就是一个曲线方程,可将其类比为三角函数
第二类贝塞尔函数可以看作第一类的非线性组合
知道这些就够了!!把它当做一个三角函数去理解!
https://zhuanlan.zhihu.com/p/87624884
https://blog.csdn.net/qq_29695701/article/details/109481820
https://docs.scipy.org/doc/scipy/reference/generated/scipy.special.j1.html
2
管道命令 | 是将左侧的输出作为右侧的输入
https://blog.csdn.net/qq_36002022/article/details/84945304
3
简单linux程序实现批量读取SCF能量
https://blog.csdn.net/EngzSinger/article/details/108113713
另外,SCF done的能量后log文件最后的HF=能量可能会不一致
简单说,如果使用的泛函不是后HF方法,二者应该是一致的
如果是后HF方法,SCF之后,会将其作为一个初始值计算电子相关能之类的,加上这个能量,体系会更加精确。这个时候的能量是在log文件末尾。可能是HF=也可能是泛函的名字CCSD=之类的
参考文章:http://sobereva.com/488
4
https://blog.csdn.net/bymaymay/article/details/94593982
./ 表示当前目录
…/ 表示父级目录
…/… 表示祖父目录
https://blog.csdn.net/Young__Fan/article/details/80152501