ОДХВДҝВј
Т»,Чјұё
°ІЧ°ұҫҙОКөСйЛщРи°ІЧ°°ь
К№УГanaconda prompt
pip install selenium
И»әуИҘПВФШЗэ¶Ҝ,ёщҫЭІ»Н¬өДдҜААЖчөД»°РиТӘПВФШІ»Н¬өДЗэ¶Ҝ,ХвАпНЖјцChrome
Зэ¶ҜПВФШНшЦ·:https://npm.taobao.org/mirrors/chromedriver/
ПВФШЦ®әуКЗТ»ёцexeОДјю,И»әуҪ«ХвёцОДјюөДВ·ҫ¶МнјУөҪ»·ҫіұдБҝ
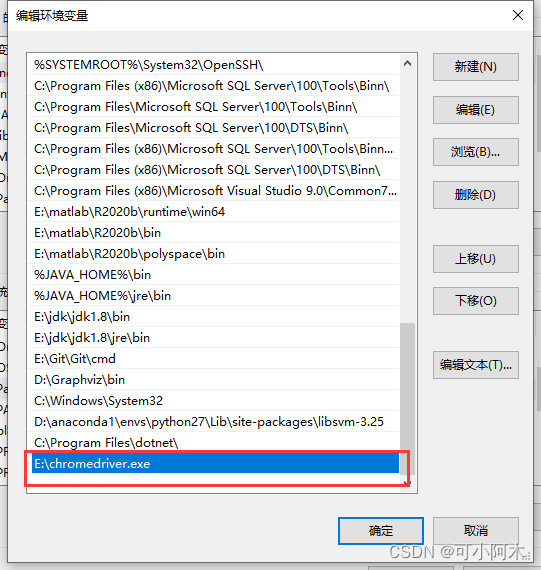
¶ю,ҙъВл
ФЛРРҪб№ыОТҫН·ЕФЪЧоәуГжөДКУЖөАпГжБЛ,ҫНІ»Т»Т»ҪШЖББЛ
ҙтҝӘдҜААЖч,ІўҙтҝӘ°Щ¶И
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
#ҪшИлНшТі
driver.get("https://www.baidu.com/")
УТјь,¶Ф°Щ¶ИТіГжҪшРРјмІй
ҝЙТФ·ўПЦЛСЛчҝтөДidКЗkw
ЛщТФҫНјтөҘБЛ
ФЪЛСЛчҝтАпГжКдИл
p_input = driver.find_element_by_id("kw")
p_input.send_keys('ФӯЙс')
ө«КЗКдИлЦ®әу»№РиТӘ»ШіөҫНәЬВй·і,ЛщТФјМРш
јмІйНшТіХТөҪ°ҙЕҘ°Щ¶ИТ»ПВөДid,ОӘsu
#өг»чЛСЛч°ҙЕҘ
p_btn=driver.find_element_by_id('su')
p_btn.click()
Иэ,ЕАИЎЦё¶ЁНшТіhttp://quotes.toscrape.com/js/өДГыСФ
Н¬Сщ,ПИҙтҝӘНшТі,ХТөҪГыСФөДid,І»УГПл,УҰёГКЗtext,ұПҫ№КЗtextОДұҫёсКҪөДЎЈ
ЛщТФЦұҪУҙъВл
from bs4 import BeautifulSoup as bs
from selenium import webdriver
import csv
from selenium.webdriver.chrome.options import Options
from tqdm import tqdm#ФЪөзДФЦХ¶ЛЙППФКҫҪш¶И,К№ҙъВлҝЙКУ»ҜҪш¶ИјУҝм
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('http://quotes.toscrape.com/js/')
#¶ЁТеcsvұнН·
quote_head=['ГыСФ','ЧчХЯ']
#csvОДјюөДВ·ҫ¶әНГыЧЦ
quote_path='C:\\Users\\hp\\Desktop\\pachong.csv'
#ҙж·ЕДЪИЭөДБРұн
quote_content=[]
'''
function_name:write_csv
parameters: csv_head,csv_content,csv_path
csv_head: the csv file head
csv_content: the csv file content,the number of columns equal to length of csv_head
csv_path: the csv file route
'''
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
print('ЕАИЎРЕПўіЙ№Ұ')
###
#ҝЙТФУГfind_elements_by_class_name»сИЎЛщУРә¬ХвёцФӘЛШөДјҜәП(БРұнТІУРҝЙДЬ)
#И»әу°СХвёцМбИЎіцАҙЦ®әуФЩУГјМРшМбИЎ
quote=driver.find_elements_by_class_name("quote")
#Ҫ«ТӘКХјҜөДРЕПў·ЕФЪquote_contentАп
for i in tqdm(range(len(quote))):
quote_text=quote[i].find_element_by_class_name("text")
quote_author=quote[i].find_element_by_class_name("author")
temp=[]
temp.append(quote_text.text)
temp.append(quote_author.text)
quote_content.append(temp)
write_csv(quote_head,quote_content,quote_path)
Ҫб№ы
ЛД,Selenium:requests+SelenumЕАИЎҫ©¶«ОпЖ·
ҙъВл
from selenium import webdriver
import time
import csv
from tqdm import tqdm#ФЪөзДФЦХ¶ЛЙППФКҫҪш¶И,К№ҙъВлҝЙКУ»ҜҪш¶ИјУҝм
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
#јУФШТіГж
driver.get("https://www.jd.com/")
time.sleep(3)
#¶ЁТеҙж·ЕНјКйРЕПўөДБРұн
goods_info_list=[]
#ЕАИЎ200ұҫ
goods_num=200
#¶ЁТеұнН·
goods_head=['јЫёс','ГыЧЦ','БҙҪУ']
#csvОДјюөДВ·ҫ¶әНГыЧЦ
goods_path='C:\\Users\\hp\\Desktop\\pachong2.csv'
#ПтКдИлҝтАпКдИлJava
p_input = driver.find_element_by_id("key")
p_input.send_keys('ұ§Хн')
#buttonәГПсІ»ДЬёщҫЭАаГыЦұҪУ»сИЎ,ПИ»сИЎҙуөДdiv,ФЩ»сИЎ°ҙЕҘ
from_filed=driver.find_element_by_class_name('form')
s_btn=from_filed.find_element_by_tag_name('button')
s_btn.click()#КөПЦөг»ч
#»сИЎЙМЖ·јЫёсЎўГыіЖЎўБҙҪУ
def get_prince_and_name(goods):
#ЦұҪУУГcss¶ЁО»ФӘЛШ
#»сИЎјЫёс
goods_price=goods.find_element_by_css_selector('div.p-price')
#»сИЎФӘЛШ
goods_name=goods.find_element_by_css_selector('div.p-name')
#»сИЎБҙҪУ
goods_herf=goods.find_element_by_css_selector('div.p-img>a').get_property('href')
return goods_price,goods_name,goods_herf
def drop_down(web_driver):
#Ҫ«№ц¶ҜМхөчХыЦБТіГжөЧІҝ
web_driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(3)
#»сИЎЕАИЎТ»Ті
def crawl_a_page(web_driver,goods_num):
#»сИЎНјКйБРұн
drop_down(web_driver)
goods_list=web_driver.find_elements_by_css_selector('div#J_goodsList>ul>li')
#»сИЎТ»ёцНјКйөДјЫёсЎўГыЧЦЎўБҙҪУ
for i in tqdm(range(len(goods_list))):
goods_num-=1
goods_price,goods_name,goods_herf=get_prince_and_name(goods_list[i])
goods=[]
goods.append(goods_price.text)
goods.append(goods_name.text)
goods.append(goods_herf)
goods_info_list.append(goods)
if goods_num==0:
break
return goods_num
while goods_num!=0:
goods_num=crawl_a_page(driver,goods_num)
btn=driver.find_element_by_class_name('pn-next').click()
time.sleep(1)
write_csv(goods_head,goods_info_list,goods_path)
Ое,КөСйҪб№ы
КөСйҪб№ыКУЖөЙПҙ«өҪБЛЯЩБЁЯЩБЁ,НшЦ·КЗhttps://www.bilibili.com/video/BV1ta411r79R/
pythonЕАИЎГыСФәНЙМЖ·РЕПў
Бщ,ЧЬҪб
әНҫІМ¬НшТіТ»СщІйҝҙНшТіҪб№№,ХТөҪФӘЛШid»тХЯАыУГПа№ШәҜКэөГөҪФӘЛШ,И»әуҪ«РЕПў»сИЎ,ҙжҙў,ІоұрІ»КЗәЬҙу