目录
一、哆嗦几句
? ? ? ? pyquery相对与xpath、beautifulsoup、re比较简单,而且支持的css选择器功能比较强大。pyquery和jqueryd的语法比较相似。所以选择puquery效率比较高。话不多说,开始搬砖。
二、库的安装
? ? ? ? 用到的库有:pyquery、time、time、random。安装方法:pip install 库
三、爬取思路
 (一、获取网页
(一、获取网页
def get_one_page(url):
#try except进行异常处理
try:
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
response=requests.get(url, headers=headers)
if response.status_code==200: # 如果状态码等于200,200代表响应成功
return response.text # 返回网页
else:
return None # 返回空
except Exception:
return None(二 )、解析网页
首先打开豆瓣电影 Top 250,按F12进入开发着模式,点击top250,如下图:
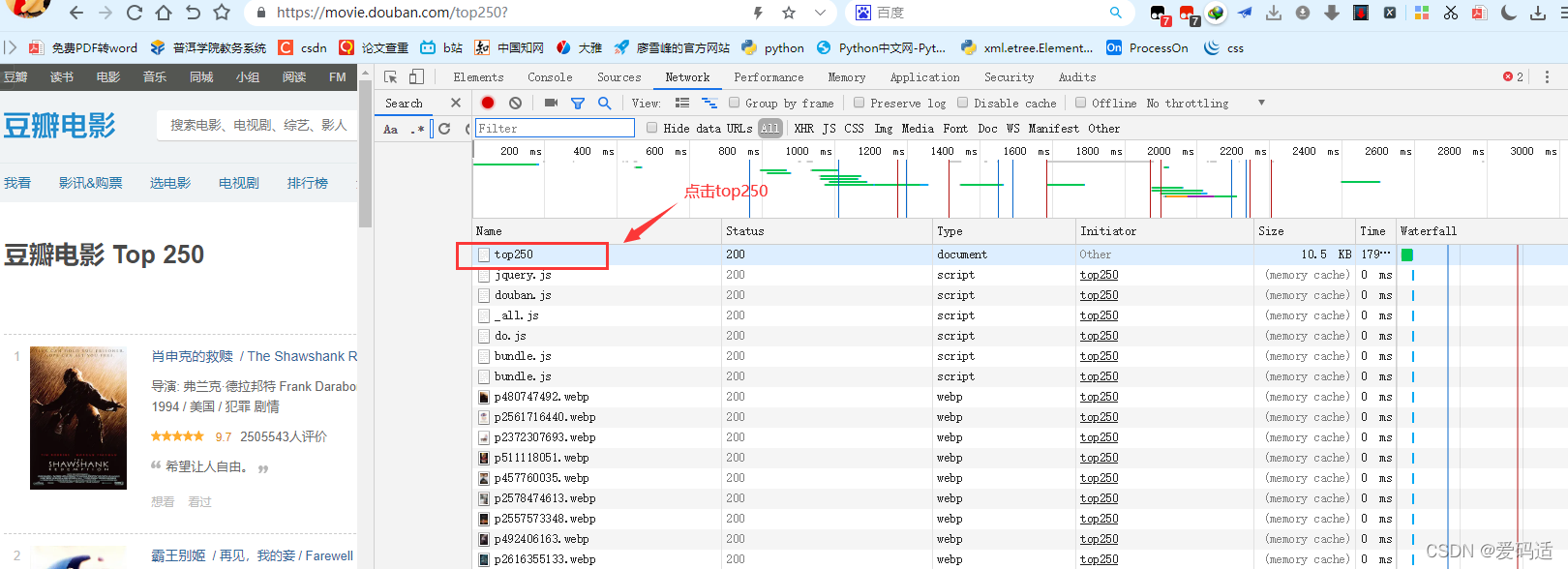
?其次按ctrl+F搜索肖生克的救赎,定位到对应的标签,如下图:
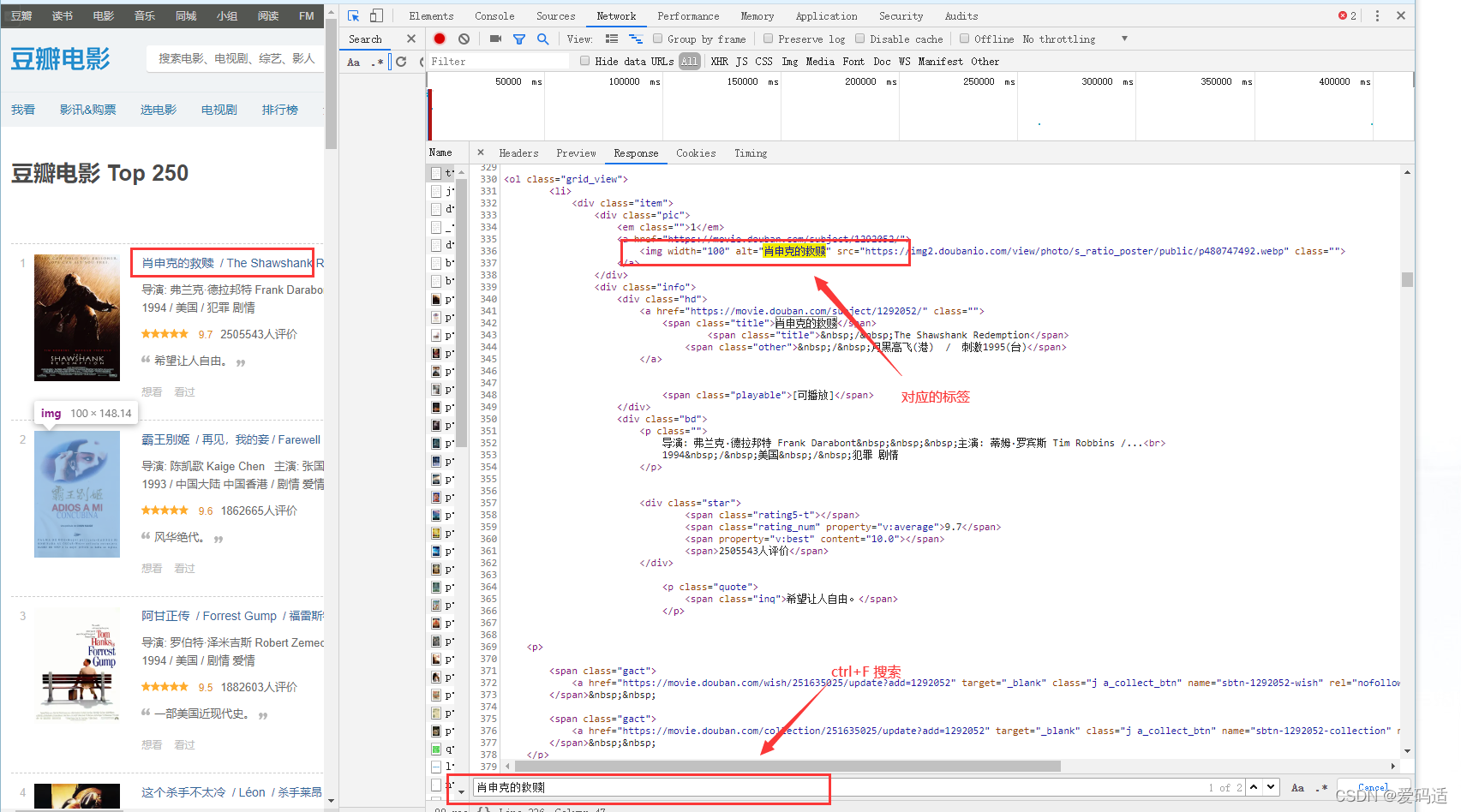
最后?找到需要提取标签,对应的标签在grid_view标签下,只要定位到grid_view标签,就可以提取。如图所示:
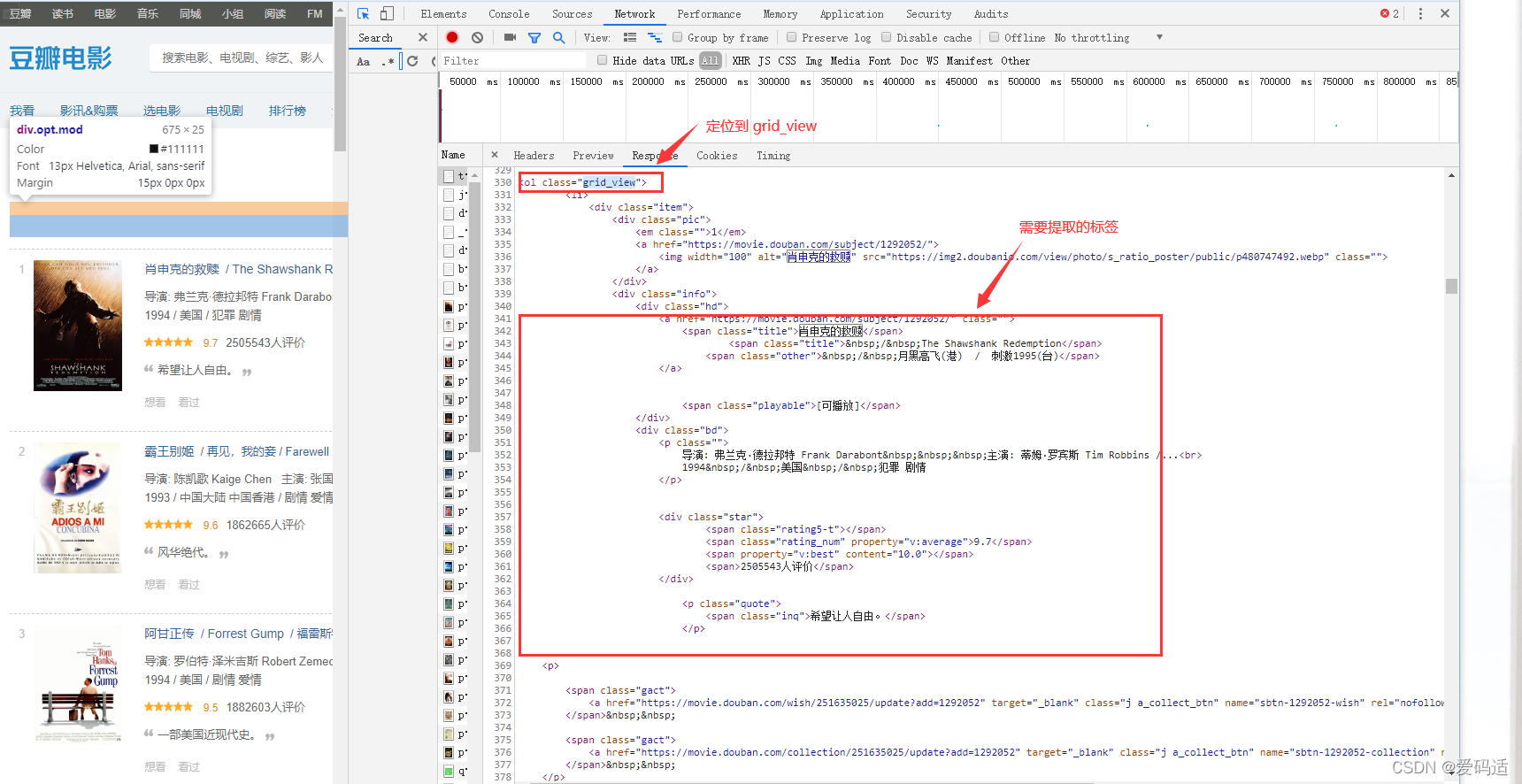
?代码提取标签如下:
def parse_one_page(html):
doc=pq(html) #对html进行初始化
print(doc)
get_all_html=doc('.grid_view') #获取grid_view标签下面的所有的节点
for i in get_all_html.items(): #用items()遍历多个节点
txt=i.text() #获取所有的文本
return txt #返回txt(三)、存储数据
def sava_data(txt):
with open('top250-2.txt','a+',encoding='utf-8') as f:
f.write(txt)(四、整合代码
def main(offset):
url='https://movie.douban.com/top250?start='+str(offset)+'&filter=' #对网页进行翻页
html=get_one_page(url) #把url参数传给get_one_page函数,然后赋给html
try:
for item in parse_one_page(html):
sava_data(item)
except:
return None
if __name__ == '__main__': #函数内置函数
for i in range(10):
main(offset=i*25)
time.sleep(random.randint(1, 6)) #生成随机数,间隔访问,以免ip被封四、完整代码
from pyquery import PyQuery as pq
import requests
import time
import random
#获取网页
def get_one_page(url):
#try except进行异常处理
try:
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
response=requests.get(url, headers=headers)
if response.status_code==200: # 如果状态码等于200,200代表响应成功
return response.text # 返回网页
else:
return None # 返回空
except Exception:
return None
#解析网页
def parse_one_page(html):
doc=pq(html) #对html进行初始化
print(doc)
get_all_html=doc('.grid_view') #获取grid_view标签下面的所有的节点
for i in get_all_html.items(): #用items()遍历多个节点
txt=i.text() #获取所有的文本
return txt #返回txt
#存储数据
def sava_data(txt):
with open('top250-2.txt','a+',encoding='utf-8') as f:
f.write(txt)
#整合代码
def main(offset):
url='https://movie.douban.com/top250?start='+str(offset)+'&filter=' #对网页进行翻页
html=get_one_page(url) #把url参数传给get_one_page函数,然后赋给html
try:
for item in parse_one_page(html):
sava_data(item)
except:
return None
if __name__ == '__main__': #函数内置函数
for i in range(10):
main(offset=i*25)
time.sleep(random.randint(1, 6)) #生成随机数,间隔访问,以免ip被封五、运行结果
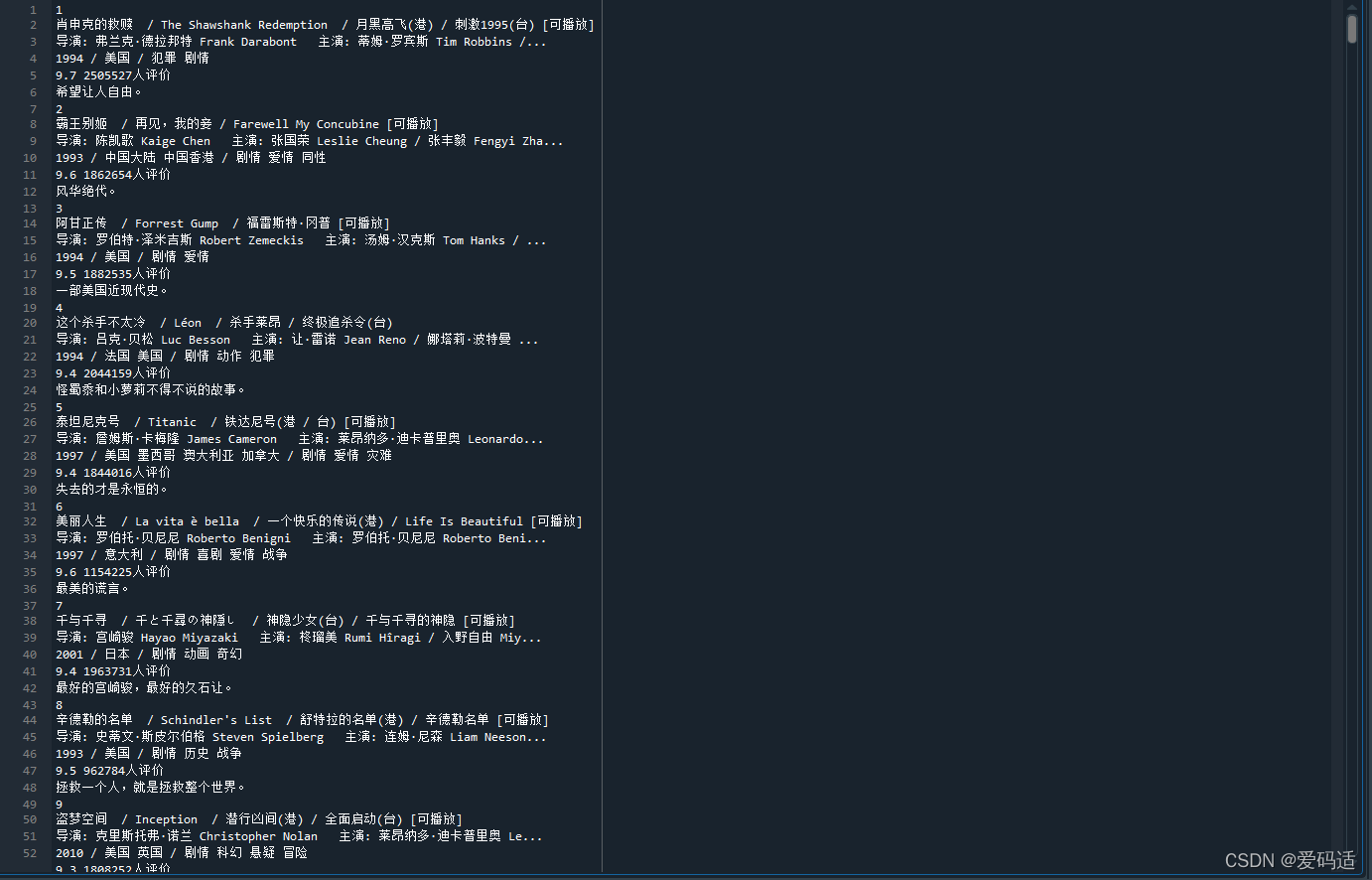
? ? ? ? ? ? ??
??
? ? ? ? ?